1.1 Redis stand-alone problems
1.1.1 machine failure
When a Redis node is deployed on a server, if the mainboard and hard disk of the machine are damaged and cannot be repaired in a short time, the Redis operation cannot be handled. This is the possible problem of a single machine
Similarly, the server runs normally, but the main Redis process is down. At this time, you only need to restart Redis. If the performance loss during Redis restart is not considered, the single machine deployment of Redis can be considered
When a single Redis deployment fails, Redis is migrated to another server. At this time, the data in the failed Redis needs to be synchronized to the newly deployed Redis node, which also requires a high cost
1.1.2 capacity bottleneck
A server has 16G of memory. At this time, 12G of memory is allocated to run Redis
If there is a new demand: Redis needs to occupy 32G or 64G more memory, this server can not meet the demand. At this time, you can consider replacing a server with larger memory, or you can use multiple servers to form a Redis cluster to meet this demand
1.1.3 QPS bottleneck
According to the official statement of Redis, a single Redis can support 100000 QPS. If the current business needs 1 million QPS, Redis distributed can be considered at this time
2. What is master-slave replication
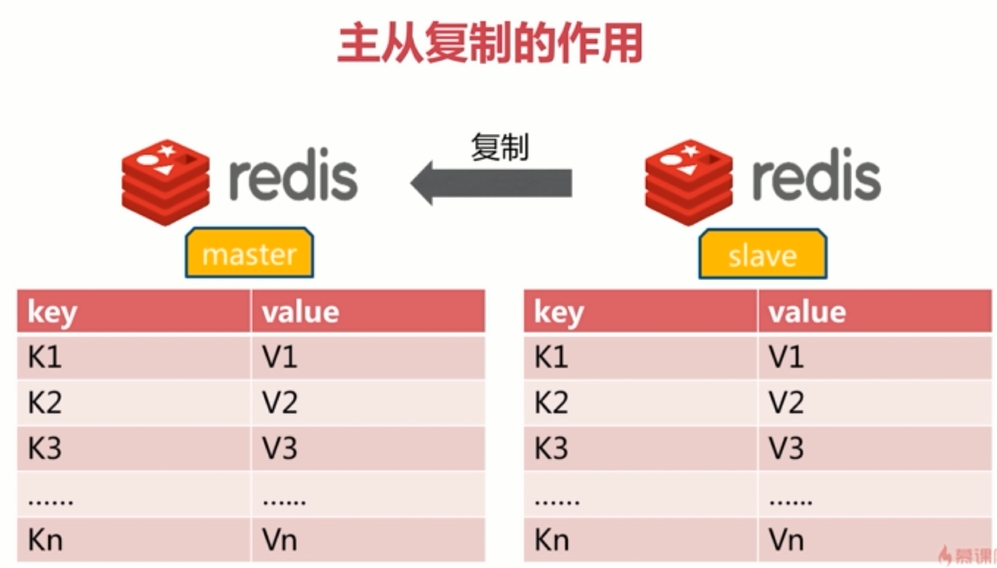
2.1 one master and one slave model
A Redis node is the master node, which is responsible for providing external services.
The other node is the slave node (slave node), which is responsible for synchronizing the data of the master node to achieve the effect of backup. When the master node fails, such as downtime, the slave node can also provide external services
As shown in the figure below
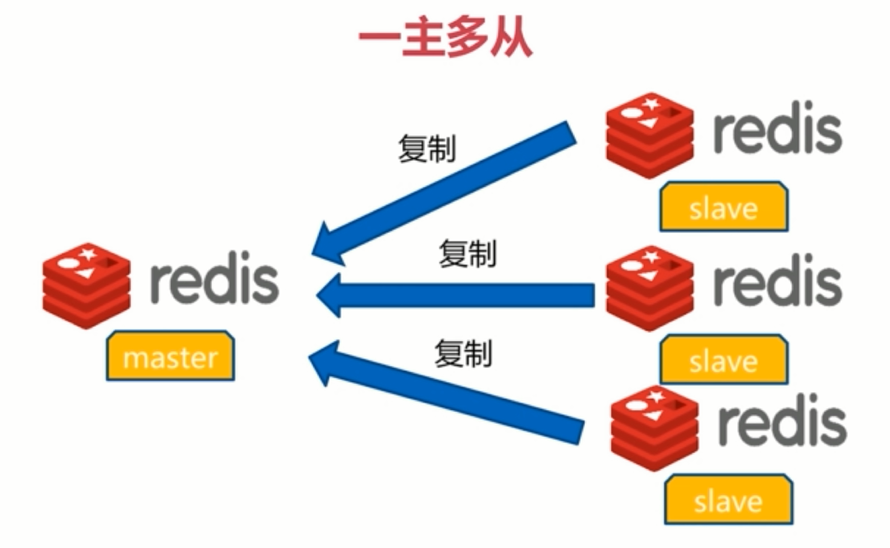
2.2 one master multi slave model
A Redis node is the master node, which is responsible for providing external services.
Multiple nodes are slave nodes (slave nodes). Each slave will back up the data in the primary node to achieve higher availability. In this case, even if the master and one slave are down at the same time, the other slave can still provide services for external reading and ensure that data will not be lost
When the master has many reads and writes and reaches the limit threshold of Redis, multiple slave nodes can be used to divert the read operations of Redis to effectively realize traffic diversion and load balancing. Therefore, one master and multiple slaves can also separate reads and writes
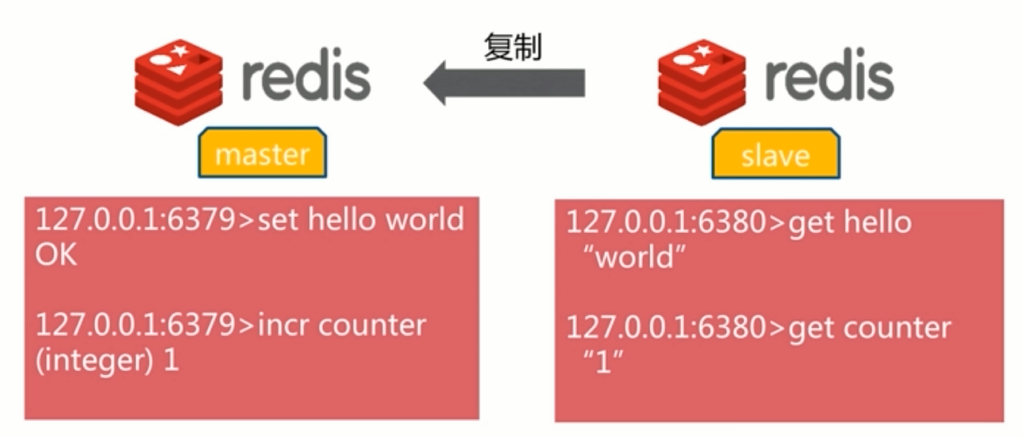
2.3 read write separation model
The master node is responsible for writing data, and the client can read data from the slave node
3. Master slave replication
Multiple backups are provided for data, which can greatly improve the reading performance of Redis and is the basis of high availability or distribution of Redis
4. Configuration of master-slave replication
4.1 slaveof command
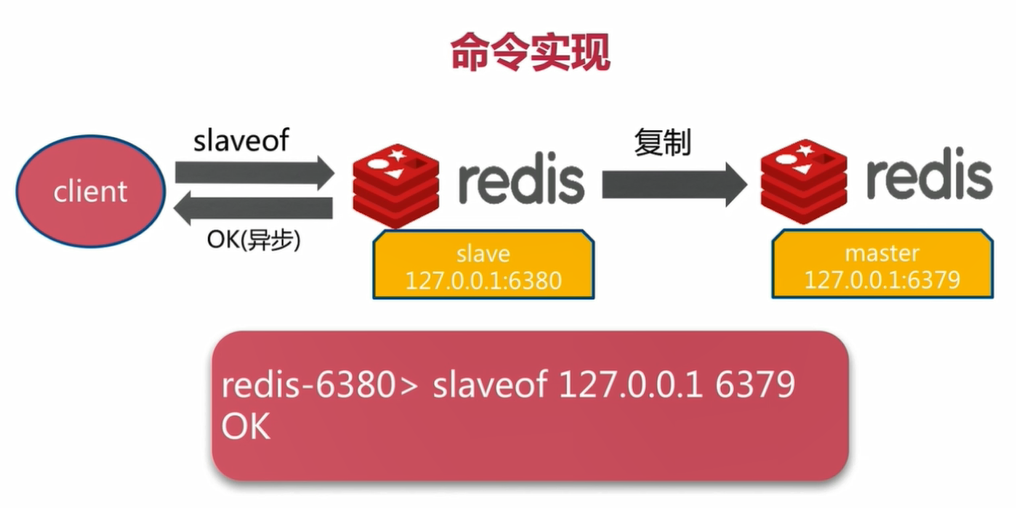
Cancel copy

4.2 configuration file configuration
Modify Redis configuration file / etc/redis.conf
slaveof <masterip> <masterport> # masterip is the IP address of the master node, and masterport is the port of the master node slave-read-only yes # The slave node only reads and does not write to ensure that the data of the master and slave devices are the same
4.3 comparison of two master-slave configuration modes
Use the command line configuration without restarting Redis,Unified configuration can be realized Configuration using the configuration file method is not subject to management, and needs to be restarted Redis
4.4 examples
There are two virtual machines with CentOS 7.5 operating system
Of a virtual machine IP The address is 192.168.81.100,do master Of a virtual machine IP The address is 192.168.81.101,do slave
Step 1: virtual machine operation on 192.168.81.101
[root@mysql ~]# vi /etc/redis.conf # Modify Redis configuration file bind 0.0.0.0 # Redis server can be connected externally slaveof 192.168.81.100 6379 # Set the IP address and port of the master
Then save the changes and start Redis
[root@mysql ~]# systemctl stop firewalld # Turn off firewalld firewall [root@mysql ~]# systemctl start redis # Start the Redis server on the slave [root@mysql ~]# ps aux | grep redis-server # View redis server processes redis 2319 0.3 0.8 155204 18104 ? Ssl 09:55 0:00 /usr/bin/redis-server 0.0.0.0:6379 root 2335 0.0 0.0 112664 968 pts/2 R+ 09:56 0:00 grep --color=auto redis [root@mysql ~]# redis-cli # Start Redis client 127.0.0.1:6379> info replication # View Redis replication info and Redis info on machine 192.168.81.101 # Replication role:slave # The role is slave master_host:192.168.81.100 # The primary node IP is 192.168.81.100 master_port:6379 # The primary node port is 6379 master_link_status:up master_last_io_seconds_ago:5 master_sync_in_progress:0 slave_repl_offset:155 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
Step 2: operate on the 192.168.81.100 virtual machine
[root@localhost ~]# systemctl stop firewalld # Turn off firewalld firewall
[root@localhost ~]# vi /etc/redis.conf # Modify Redis configuration file
bind 0.0.0.0
Then save the changes and start Redis
[root@localhost ~]# systemctl start redis # Start Redis on the master
[root@localhost ~]# ps aux | grep redis-server # View redis server process
redis 2529 0.2 1.8 155192 18192 ? Ssl 17:55 0:00 /usr/bin/redis-server 0.0.0.0:6379
root 2536 0.0 0.0 112648 960 pts/2 R+ 17:56 0:00 grep --color=auto redis
[root@localhost ~]# redis-cli # Start the redis cli client on the master
127.0.0.1:6379> info replication # View Redis information on 192.168.81.100 machine
# Replication
role:master # Role master node
connected_slaves:1 # Connect a slave node
slave0:ip=192.168.81.101,port=6379,state=online,offset=141,lag=2 # Information from the node
master_repl_offset:141
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:140
127.0.0.1:6379> set hello world # Write data to master node
OK
127.0.0.1:6379> info server
# Server
redis_version:3.2.10
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:c8b45a0ec7dc67c6
redis_mode:standalone
os:Linux 3.10.0-514.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
gcc_version:4.8.5
process_id:2529
run_id:7091f874c7c3eeadae873d3e6704e67637d8772b # Notice this run_id
tcp_port:6379
uptime_in_seconds:488
uptime_in_days:0
hz:10
lru_clock:12784741
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
Step 3: return to 192.168.81.101, the slave node
127.0.0.1:6379> get hello # Get the value of 'hello', you can get "world" 127.0.0.1:6379> set a b # Failed to write data to 192.168.81.101 slave node (error) READONLY You can't write against a read only slave. 127.0.0.1:6379> slaveof no one # Cancel slave node settings OK 127.0.0.1:6379> info replication # Check the 192.168.81.101 machine. It is no longer a slave node, but a master node # Replication role:master # Become the master node connected_slaves:0 master_repl_offset:787 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 127.0.0.1:6379> dbsize # View all data sizes of Redis on 192.168.81.101 (integer) 2
Step 4: return to 192.168.81.100 virtual machine
127.0.0.1:6379> mset a b c d e f # Write data to Redis collection on 192.168.81.100 OK 127.0.0.1:6379> dbsize # The data size in Redis is 5 (integer) 5
Step 5: view Redis logs on 192.168.81.100 virtual machine
[root@localhost ~]# tail /var/log/redis/redis.log # View the last 10 rows of Redis logs 2529:M 14 Oct 17:55:09.448 * DB loaded from disk: 0.026 seconds 2529:M 14 Oct 17:55:09.448 * The server is now ready to accept connections on port 6379 2529:M 14 Oct 17:55:10.118 * Slave 192.168.81.101:6379 asks for synchronization 2529:M 14 Oct 17:55:10.118 * Partial resynchronization not accepted: Runid mismatch (Client asked for runid '9f93f85bce758b9c48e72d96a182a2966940cf52', my runid is '7091f874c7c3eeadae873d3e6704e67637d8772b') # It is the same as the run viewed through the info command on the 192.168.81.100 device_ Same ID 2529:M 14 Oct 17:55:10.118 * Starting BGSAVE for SYNC with target: disk # BGSAVE command executed successfully 2529:M 14 Oct 17:55:10.119 * Background saving started by pid 2532 2532:C 14 Oct 17:55:10.158 * DB saved on disk 2532:C 14 Oct 17:55:10.159 * RDB: 12 MB of memory used by copy-on-write 2529:M 14 Oct 17:55:10.254 * Background saving terminated with success 2529:M 14 Oct 17:55:10.256 * Synchronization with slave 192.168.81.101:6379 succeeded # Data synchronization to 192.168.81.101 succeeded
Step 6: return to 192.168.81.101 virtual machine
127.0.0.1:6379> slaveof 192.168.81.100 6379 # Reset 192.168.81.101 to the slave node of 192.168.81.100 OK 127.0.0.1:6379> dbsize (integer) 5 127.0.0.1:6379> mget a 1) "b"
Step 7: view the Redis log on the 192.168.81.101 virtual machine
[root@mysql ~]# tail /var/log/redis/redis.log # View the last 10 rows of Redis logs 2319:S 14 Oct 09:55:17.625 * MASTER <-> SLAVE sync started 2319:S 14 Oct 09:55:17.625 * Non blocking connect for SYNC fired the event. 2319:S 14 Oct 09:55:17.626 * Master replied to PING, replication can continue... 2319:S 14 Oct 09:55:17.626 * Trying a partial resynchronization (request 9f93f85bce758b9c48e72d96a182a2966940cf52:16). 2319:S 14 Oct 09:55:17.628 * Full resync from master: 7091f874c7c3eeadae873d3e6704e67637d8772b:1 # Full replication of data from the master node 2319:S 14 Oct 09:55:17.629 * Discarding previously cached master state. 2319:S 14 Oct 09:55:17.763 * MASTER <-> SLAVE sync: receiving 366035 bytes from master # Displays the size of data synchronized from the master 2319:S 14 Oct 09:55:17.765 * MASTER <-> SLAVE sync: Flushing old data # slave clears the original data 2319:S 14 Oct 09:55:17.779 * MASTER <-> SLAVE sync: Loading DB in memory # Load the synchronized RDB file 2319:S 14 Oct 09:55:17.804 * MASTER <-> SLAVE sync: Finished with success
5. Full and partial replication
5.1 full copy
5.1.1 run_ The concept of ID
Every time Redis starts, it has a random ID to identify Redis. This random ID is the run obtained from the info command above_ id
View run on 192.168.81.101 virtual machine_ ID and offset
[root@localhost ~]# redis-cli info server |grep run_id run_id:7e366f6029d3525177392e98604ceb5195980518 [root@localhost ~]# redis-cli info |grep master_repl_offset master_repl_offset:0
View run on 192.168.91.100 virtual machine_ ID and offset
[root@mysql ~]# redis-cli info server | grep run_id run_id:7091f874c7c3eeadae873d3e6704e67637d8772b [root@mysql ~]# redis-cli info | grep master_repl_offset master_repl_offset:4483
run_id is a very important identification.
In the above example, 192.168.81.101 is used as a slave to copy the data on the master 192.168.81.100, and the corresponding run on the 192.168.81.100 machine will be obtained_ ID is marked on 192.168.81.101
When Redis runs on 192.168.81.100 machine_ The change of ID means that the Redis on the 192.168.81.100 machine is restarted or other major changes occur. 192.168.81.101 will synchronize all the data on 192.168.81.100 to 192.168.81.101, which is the concept of full replication
5.1.2 concept of offset
Offset is the number of bytes of data written.
When writing data on Redis of 192.168.81.100, the master will record how much data has been written and record it in the offset.
The operation on 192.168.81.100 will be synchronized to the 192.168.81.101 machine, and Redis on 192.168.81.101 will also record the offset.
When the offsets on the two machines are the same, the data synchronization is completed
Offset is an important basis for partial replication
View Redis offset on 192.168.81.100 machine
127.0.0.1:6379> info replication # View replication information # Replication role:master connected_slaves:1 slave0:ip=192.168.81.101,port=6379,state=online,offset=8602,lag=0 master_repl_offset:8602 # At this time, the offset on 192.168.81.100 is 8602 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:8601 127.0.0.1:6379> set k1 v1 # Write data to 192.168.81.100 OK 127.0.0.1:6379> set k2 v2 # Write data to 192.168.81.100 OK 127.0.0.1:6379> set k3 v3 # Write data to 192.168.81.100 OK 127.0.0.1:6379> info replication # View replication information # Replication role:master connected_slaves:1 slave0:ip=192.168.81.101,port=6379,state=online,offset=8759,lag=1 master_repl_offset:8759 # After writing data, the offset on 192.168.81.100 is 8759 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:8758
View the Redis offset on the 192.168.81.101 machine
127.0.0.1:6379> info replication # View replication information # Replication role:slave master_host:192.168.81.100 master_port:6379 master_link_status:up master_last_io_seconds_ago:8 master_sync_in_progress:0 slave_repl_offset:8602 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 # At this time, the offset on 192.168.81.101 is 8602 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> get k2 "v2" 127.0.0.1:6379> get k3 "v3" 127.0.0.1:6379> info replication # View replication information # Replication role:slave master_host:192.168.81.100 master_port:6379 master_link_status:up master_last_io_seconds_ago:7 master_sync_in_progress:0 slave_repl_offset:8759 # The offset on 192.168.81.101 after data synchronization is 8759 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
If the offset gap between the master and slave nodes is too large, it indicates that the slave node does not synchronize data from the master node, and there are problems in the connection between the master and slave nodes: such as network, blocking, buffer, etc
5.1.3 concept of full replication
If a master node has written a lot of data, the slave node not only synchronizes the existing data, but also synchronizes the data written by the slave on the master during synchronization (if the master is written during synchronization), so as to achieve complete data synchronization. This is the full replication function of Redis
The Redis master will synchronize the current RDB file to the slave. During this period, the data written in the master will be written to the repl_back_buffer. When the RDB file is synchronized to the slave, the master will synchronize the data in the repl_back_buffer to the slave through offset comparison
Redis uses the psync command for full and partial data replication
The psync command has two parameters: run_id and offset
To the psync command:
1.stay slave First time to master Don't know when synchronizing data master of run_id and offset,use`psync ? -1`Command to master Initiate synchronization request 2.master After accepting the request, you know slave It's full replication, master Will put run_id and offset Respond to slave 3.slave preservation master Sent over run_id and offset 4.master response slave After, execute BGSAVE Command to generate all current data RDB File, and then RDB File synchronization to slave 5.Redis Medium repl_back_buffer The copy buffer can record generation RDB The data written during the time period from the file to the completion of synchronization, and then synchronize these data to the slave 6.slave implement flushall Command clear slave The original data in, and then from RDB Read all data from the file to ensure slave And master Data synchronization in
As shown in the figure below:
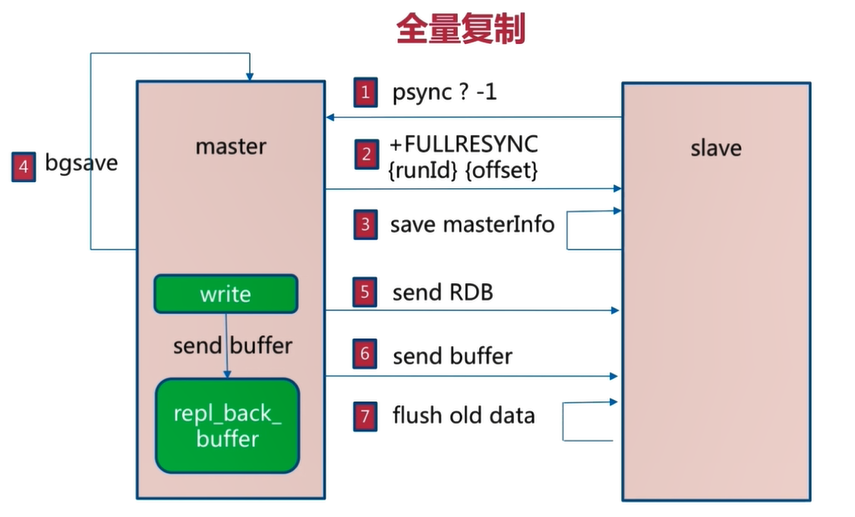
5.1.4 overhead of full replication
- Full replication is very expensive
- The BGSAVE command executed by the master takes some time
- The BGSAVE command fork s subprocesses and consumes CPU, memory and hard disk
- The time when the master transfers RDB files to the slave will also occupy a certain network bandwidth
- The time taken by the slave to clear the original data. If there is more original data in the slave, clearing the original data will also take some time
- slave loading RDB files takes some time
- Possible AOF file rewriting time: RDB file loading is completed. If the AOF function of the slave node is enabled, AOF rewriting will be performed to ensure that the latest data is saved in the AOF file
5.4 problems of full replication
In addition to the overhead mentioned above, if there is a problem with the network between the master and the slave, the data synchronized on the slave will be lost over a period of time
The best way to solve this problem is to do another full replication to synchronize all the data in the master
Redis version 2.8 adds the function of partial replication. In case of network problems between master and slave, partial replication is used to reduce the possibility of data loss as much as possible instead of full replication
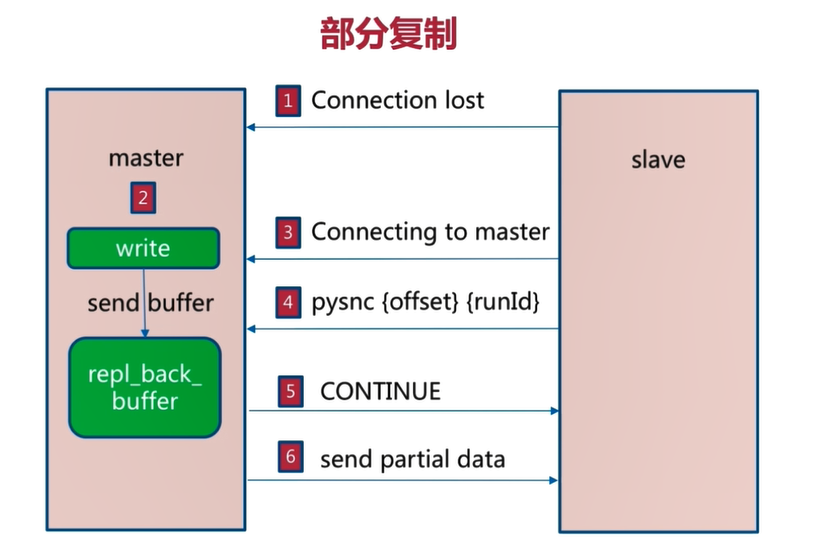
5.2 partial reproduction
When the connection between the master and the slave is disconnected, the master will save the written data to repl while writing data_ back_ Buffer copy buffer
When the network between the master and the slave is connected, the slave will execute the psync {offset} {run_id} command. Offset is the offset on the slave node
When the master receives the offset transmitted by the slave, it will contact the repl_ back_ The buffer is compared with the offset in the copy buffer,
If the received offset is less than repl_ back_ For the offset recorded in the buffer, the master will send the data between the two offsets to the slave. The slave synchronization is completed, and the data in the slave is consistent with the data in the master
As shown in the figure below
6. Master slave replication failure
6.1 slave downtime
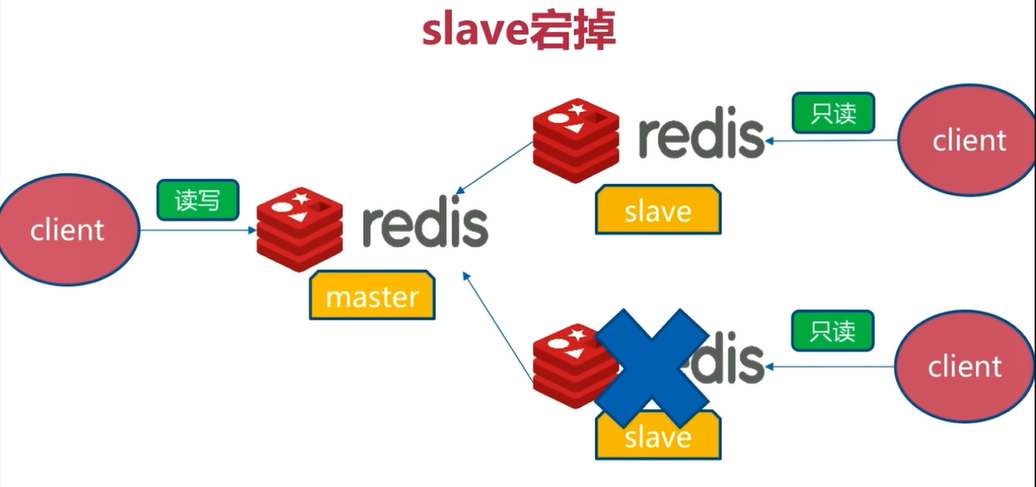
In this architecture, when the read and write are separated, the down slave cannot synchronize data from the master
6.2 master downtime
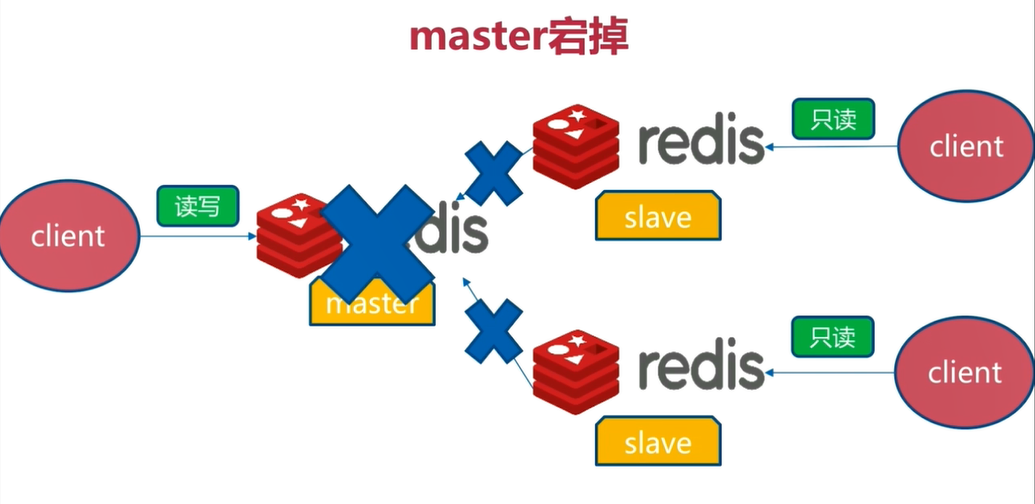
Redis's master cannot provide services. Only slave can provide data reading services
Solution: turn one slave into a master to provide the function of writing data, and the other slave as the slave node of the new master to provide the function of reading data. This solution still needs to be completed manually
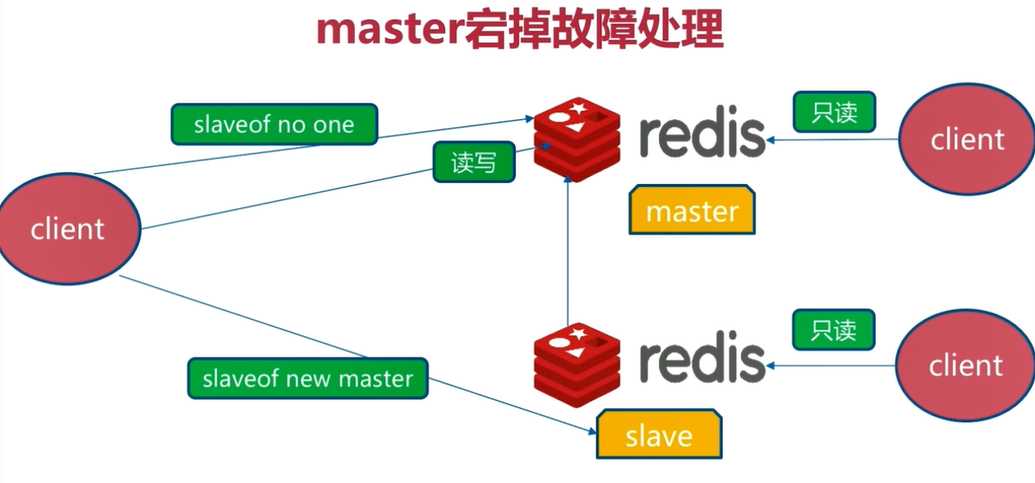
The master-slave mode does not realize automatic fault transfer, which is the role of Redis sentinel
7. Common problems in development, operation and maintenance
7.1 read write separation
Read write separation: the master is responsible for writing data and allocating the traffic of reading data to the slave node
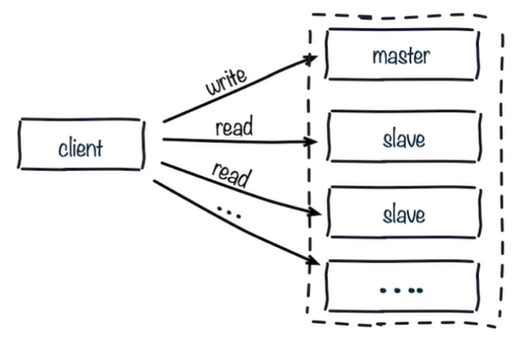
On the one hand, read-write separation can reduce the pressure on the master, and on the other hand, it expands the ability to read data
Problems encountered in read-write separation:
7.1.1 replication data latency
In most cases, the master synchronizes the data to the slave asynchronously, and there will be a time difference in the process
When the slave encounters a block, there will be a certain delay in receiving data. During this time period, the data read from the slave may be inconsistent
You can monitor the offset values of the master and slave. When the offset values differ too much, you can convert the read traffic to the master, but this method has a certain cost
7.1.2 reading expired data
How Redis deletes expired data
Method 1: lazy strategy
When Redis When you operate this data, you will check whether the data has expired. If the data has expired, an error will be returned-2 To the client, indicating that the queried data has expired
Mode 2:
Every other cycle, Redis Will collect some key,Look at this key Expired If expired key Very much or sampling slower than key When the expiration speed, there will be a lot of expiration key Not deleted here slave Sync includes expiration key Inner master All data on because slave You do not have permission to delete data. In this case, based on the read-write separation mode, the client will delete data from slave Read some expired data, that is, dirty data
7.1.3 slave node failure
In Figure 9, the slave is down, and the cost of migrating from the slave node to the master node is very high
Before considering the use of read-write separation, first consider the optimization of the master node
Redis has high performance and can meet most scenarios. You can optimize some memory configuration parameters or AOF policies, or consider using redis distributed
7.2 inconsistent master-slave configuration
The first case is: for example, maxmemory inconsistency: data loss
For example, when the memory allocated by the master node is 4G and the memory allocated by the slave node is only 2G, normal master-slave replication can be performed
However, when the data synchronized by the slave from the master is greater than 2G, the slave will not throw an exception, but will trigger the maxmemory policy policy of the slave node to eliminate part of the synchronized data. At this time, the data in the slave is incomplete, resulting in data loss
Another case of inconsistent master-slave configuration is that the data structure of the master node is optimized, but the slave is not optimized in the same way, resulting in inconsistent memory between the master and slave
7.3 avoid full replication
7.3.1 the overhead of full replication is very large
When configuring a slave for a master for the first time, there is no data in the slave, and full replication is inevitable
Solution: the maxmemory of the master-slave node should not be set too large, so the speed of transferring and loading RDB files will be fast, and the overhead will be relatively small. Full replication can also be carried out when the user access is relatively low
7.3.2 node run_id mismatch
When the master restarts, the run of the master_ The ID will change. slave finds the run of the previously saved Master when synchronizing data_ ID and current run_ If the IDS do not match, the current master will be considered unsafe
resolvent:
Make a full copy,When master In case of failure, slave Convert to master Provide data writing, or use Redis Sentinels and clusters
Redis 4.0 provides a new method: when the master runs_ When the ID changes, failover can avoid full replication
7.3.3 insufficient copy buffer
The copy buffer is used to write new commands to the buffer
The replication buffer is actually a queue. The default size is 1MB, that is, the replication buffer can only store data of 1MB
If the slave is disconnected from the master's network, the master will save the newly written data to the replication buffer
When the data written to the copy buffer is less than 1 MB Partial replication can be done to avoid the problem of full replication If the newly written data is greater than 1 MB When, you can only do full replication
Modify rel in configuration file_ backlog_ Size option to increase the size of the replication buffer to reduce the occurrence of full replication
7.4 avoiding replication storm
In the master-slave architecture, when the master node restarts, the master runs_ The ID will change, and all slave nodes will perform master-slave replication
The master generates RDB files, and then all slave nodes synchronize the RDB files. In this process, there is a great overhead on the CPU, memory and hard disk of the master node, which is the replication storm
Solution to single master node replication storm
Replace replication topology
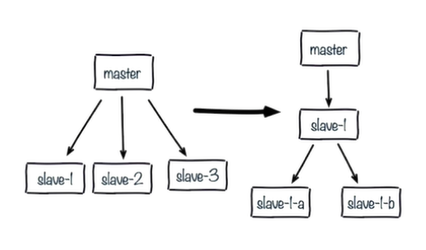
Single machine multi deployment replication storm
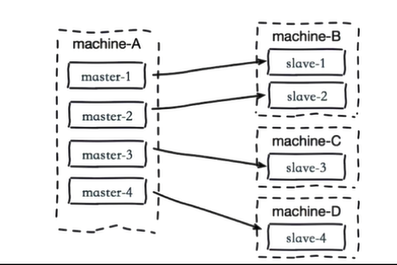
All nodes on a server are master,If this server system restarts, all slave Full replication of all nodes from this server will put great pressure on the server Master node decentralized multi machine take master Assign to different servers
Brief summary of Redis master-slave mode
One master There can be more than one slave One slave You can also have slave One slave There can only be one master The data flow direction is one-way and can only be from master reach slave