Common cache algorithms:
First in first out (FIFO) queue: first in first out. The data that enters first is eliminated first. Disadvantages: ignore the data access frequency and access times.
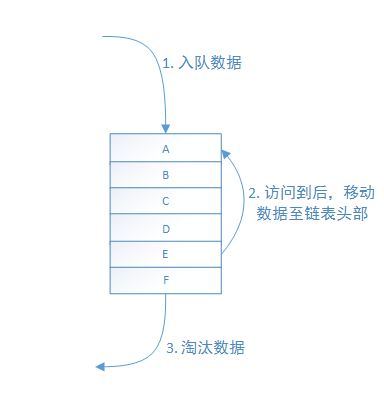
Least recently used (LRU) : least recently used algorithm, that is, if the data has been accessed recently, the probability of being accessed in the future is greater. LRU uses a linked list, and the newly inserted data will be added to the head of the linked list; when the cache hits, the data will be moved to the head of the linked list; if the linked list is full, the data at the end of the linked list will be discarded.
[hit rate] if there is hot data, the LRU is very efficient. However, for occasional and periodic batch operations, the LRU hit rate will drop sharply and the cache pollution will be serious.
[complexity] easy to implement.
[cost] when accessing data hits, you need to traverse the linked list, find the index position of the hit data block, and then move the data to the head of the linked list.
Least frequently used (LFU): algorithms are often used recently, that is, if data has been accessed many times in the past, it will be accessed more frequently in the future.
Caffeine cache algorithm: it combines LRU and LFU algorithms to manage cache.
Caffeine data structure:
Caffeine uses readBuffer and writeBuffer. It uses a Long array to store the access frequency of the key. The 64 bits of Long are divided into four segments, each segment accounting for 16 bits. First, calculate the hash value according to the key, and use the hash value to calculate which of the four segments is in; second, calculate the specific positions of the four segments and set the frequency of the current position; finally, take the minimum value of the four frequency values To represent the access frequency of the key.
The default value of ringbuffer is 16, and its array size is 256. Assuming that the reference size is 4 bytes (references are stored in ringbuffer), the cache line size is 64. Therefore, only one data is stored in each cache line, so the cas operation appends 16, that is, there is only one valid storage for every 16 elements in the array, and space is used for time.
High performance read / write operations:
Referring to the WAL idea of the database, after the read-write operation, the operation records (judge whether the data is expired; statistical frequency; record read-write statistical hit rate, etc.) are recorded in the buffer, and then processed asynchronously to improve the performance.
The core idea of WAL (write ahead logging) is to write the data to the log before writing it to the database, and then change the log record to the memory.
Three recycling strategies of Caffeine cache
Size based: maximumSize
Time based:
expireAfterAccess Last access expiration timing
expireAfterWrite Expiration timing on last writeReference based: only soft references and weak references are subject to expiration processing
usage method:
// Initialize Caffeine object
@Bean
public Cache<String, Object> caffeineCacheInstance() {
Cache<String, Object> caffeineCache = Caffeine.newBuilder().initialCapacity(initialCapacity)
// The setting never expires. The default is 300 years
.expireAfterAccess(Long.MAX_VALUE, TimeUnit.DAYS)
.expireAfterWrite(Long.MAX_VALUE, TimeUnit.DAYS)
// Set remove listener
.removalListener(new CacheRemoveListener())
// Unlimited capacity
//.maximumSize(maximumSize)
.build();
return caffeineCache;
}
// Add the class CacheRemoveListener to handle cache removal listener
public class CacheRemoveListener implements RemovalListener<Object, Object> {
@Override
public void onRemoval(@Nullable Object key, @Nullable Object value, @Null RemovalCause cause) {
// Process when cache is recycled or expired
if(cause.equals(RemovalCause.COLLECTED) || cause.equals(RemovalCause.EXPIRED)) {
// Processing is required when an object is recycled or expired
return;
}
// Processing on cache update
if(cause.equals(RemovalCause.REPLACED)) {
logger.warn("Caffeine " + cause + " OK, key-value, " + key + ":" + value);
}
}
}
Usage: referenced in a specific @ Service class
@Autowired
private Cache<String, Object> caffeineCacheInstance;
Storage: caffeineCacheInstance.put(key, value);
Read: Object value = caffeineCacheInstance.getIfPresent(key);
Precautions during use:
(1) Initialize local cache data
(2) Capacity evaluation, do not exceed the memory capacity
(3) Cache hit rate
(4) Garbage recycling
(5) Performance test
Explanation of related terms:
Eviction: deletion automatically performed in the background because certain eviction policies are met
invalidation: indicates that the cache is manually deleted by the caller
Remove: listener listening for evictions or invalid operations