preface
Today, I'd like to share common problems and solutions when Redis is used as a cache. Solutions to problems such as cache penetration, cache failure (breakdown) and cache avalanche.
1, Cache penetration?
Redis middleware is basically an indispensable element in high concurrency system design. There are some problems that we need to deal with when we use it as a cache. For example, cache penetration, first explain what is cache penetration?
Cache penetration refers to querying a non-existent data, resulting in the miss of both cache layer and persistence layer. Caching loses the meaning of protecting the persistence layer. Generally, we do this. When data requests come in, we will query in the cache first. When there is no data in the cache, we will query in the persistence layer. After the persistence layer query, the queried data will be written to the cache. If the persistence layer does not query, it will not be written to the cache. It is this kind of data that does not exist at all. If the request volume is large, it will eventually hit the persistence layer, resulting in the persistence layer hanging. The whole system crashed. So how?
Solution:
-
Cache empty objects
We also put the data not found in the database into the cache, and set an expiration time for the empty object, so that subsequent requests will be fetched from the cache within the expiration time of the empty object, thus reducing the pressure on the database.
Code demonstration:@Autowired private StringRedisTemplate stringRedisTemplate; @Autowired private RedisCacheService cacheService; @RequestMapping(value = "/cache_pierce") @ResponseBody public String cachePierce(String key){ if (key == null || key.equals("")){ return "key The parameter is null"; } String cacheData = stringRedisTemplate.opsForValue().get(key); if(cacheData != null){ //Return from cache return cacheData; }else { //If the cache is empty, go to query the database and simulate it here String s = cacheService.searchDB(key); stringRedisTemplate.opsForValue().set(key,s); if(s.equals("null")){ stringRedisTemplate.expire(key,30, TimeUnit.SECONDS); System.out.println("Cache empty object"); } return s; } } //Simulated query database public String searchDB(String key){ //I think the database found it if(key != null && key.equals("fafa")){ System.out.println("The persistence layer found it"); return "fafa"; }else { try { Thread.sleep(1000); }catch (Exception exception){ exception.printStackTrace(); } System.out.println("Does not exist in persistence layer"); return "null"; } } -
Bloom filter
For malicious requests on the network, we can also use bloom filter to process them. For non-existent data, Bloom filters can generally filter out. It can also prevent cache penetration. When the requested data comes in, it first passes through the bloom filter. The bloom filter says that the data exists, and the data may or may not exist. However, if the bloom filter says that the data does not exist, the data certainly does not exist. Here is a brief analysis of the principle of Bloom filter through a diagram:
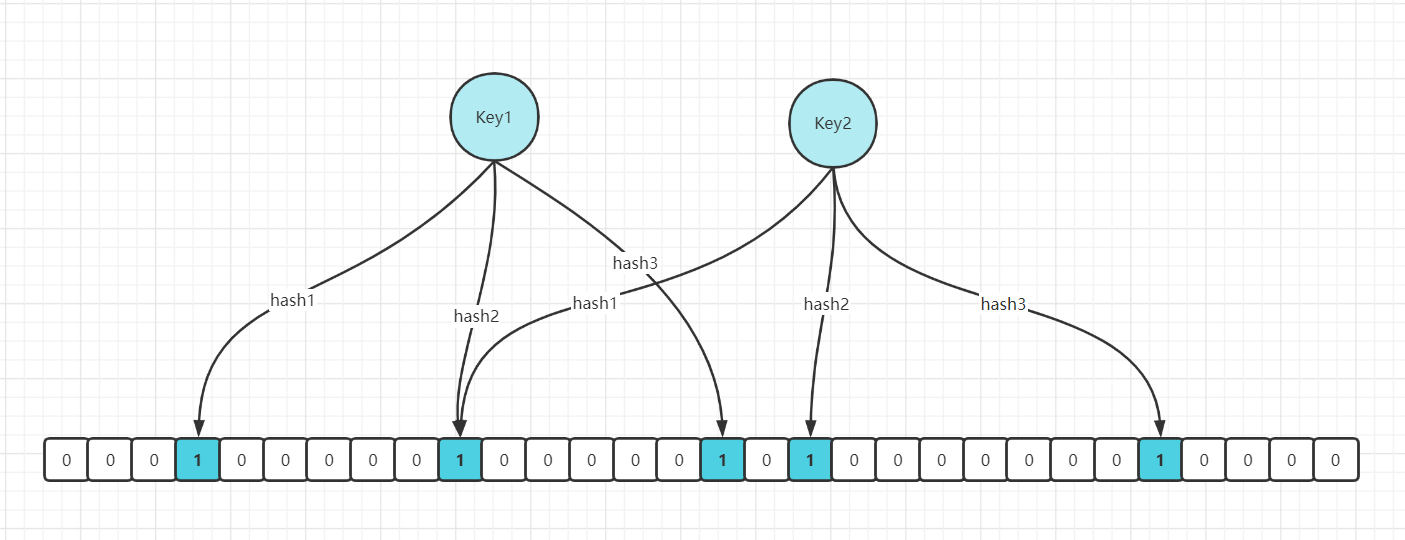
Bloom filter is a large set of bits and several different unbiased hash functions. Unbiased means that the hash value of an element can be calculated evenly. When adding a key to the bloom filter, multiple hash functions will be used to hash the key to obtain an integer index value, and then modulo the length of the bit array to obtain a position. Each hash function will calculate a different position. Then set these positions of the bit group to 1 to complete the add operation. When you ask the bloom filter whether a key exists, just like add, you will calculate several positions of the hash to see whether these positions in the bit group are all 1. As long as one bit is 0, it means that the key in the bloom filter does not exist. If they are all 1, this does not mean that the key must exist, but it is very likely to exist, because these bits are set to 1, which may be caused by the existence of other keys. If the digit group is sparse, the probability will be large. If the digit group is crowded, the probability will be reduced. This method is suitable for application scenarios with low data hit, relatively fixed data and low real-time performance (usually with large data sets). Code maintenance is complex, but the cache space takes up little.
Redisson can implement bloom filter:
Import dependency:<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.6.5</version> </dependency>The code is as follows:
@Autowired private Redisson redisson; //redisson needs to be injected into spring first RBloomFilter<Object> bloomFilter = redisson.getBloomFilter("nameList"); //Initialize bloom filter: it is estimated that the element is 100000000L and the error rate is 3%. The size of the underlying bit array will be calculated according to these two parameters bloomFilter.tryInit(100000000L,0.03); bloomFilter.add("tuofafa"); //The contains method returns true, indicating that the key exists in the cache. Otherwise, it is vice versa System.out.println(bloomFilter.contains("xiaohua")); System.out.println(bloomFilter.contains("tuofafa"));Note: when using the bloom filter, the data should be put into the cache in advance, and when adding data, it should also be put into the bloom filter. The bloom filter cannot delete data. If you want to delete data, you need to reinitialize the data.
2, Cache failure (breakdown)
Cache failure or cache breakdown is due to the simultaneous failure of a large number of data, resulting in a large number of requests hitting the persistence layer in an instant, resulting in the depletion of persistence layer resources and the final system crash. That leads to the simultaneous invalidation of large quantities of data because the expiration time set when we store data in the cache is the same.
Solution: we set a time range for the expiration time of a large number of cached data. In this way, the probability of expiration in an instant is very small.
The code is as follows:
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private RedisCacheService cacheService;
if (key == null || key.equals("")){
return "key The parameter is null";
}
String cacheData = stringRedisTemplate.opsForValue().get(key);
if(cacheData != null){
System.out.println("Return from cache");
return cacheData;
}else {
//If the cache is empty, go to query the database and simulate it here
String s = cacheService.searchDB(key);
stringRedisTemplate.opsForValue().set(key,s);
if(s.equals("null")){
//Set a period of time without a time range
int time = new Random().nextInt(100)+100;
stringRedisTemplate.expire(key,time, TimeUnit.SECONDS);
}
return s;
}
3, Cache avalanche
Cache avalanche means that the cache layer cannot support or is down, and all traffic flows madly to the persistence layer. The cache layer carries a large number of requests and can effectively protect the persistence layer. However, if the cache layer is not well designed or goes down for some reasons, there will be an avalanche effect in the end. The system cannot operate normally.
Solution:
- Adopt highly available cache architecture, such as sentinel architecture, cluster architecture, etc
- Rely on the isolation component to fuse and degrade the back-end current limit. For example, use Sentinel or Hystrix current limiting to degrade components.
- Predict the drill in advance.
4, Reconstruction and optimization of hotspot cache Key
The strategy of "cache + expiration time" can not only accelerate data reading and writing, but also ensure regular data update. This mode can basically meet most requirements. However, if two problems occur at the same time, they may cause fatal harm to the application:
- At present, the key is a hot key (for example, a popular entertainment news), and the concurrency is very large
- Rebuilding the cache cannot be completed in a short time. It may be a complex calculation, such as complex SQL, multiple IO, multiple dependencies, etc
At the moment of cache failure, a large number of threads rebuild the cache, resulting in increased back-end load and even application crash. The main solution to this problem is to avoid a large number of threads rebuilding the cache at the same time. We can use mutual exclusion to solve this problem. This method only allows one thread to rebuild the cache, and other threads can get data from the cache again after waiting for the thread to rebuild the cache to execute.
5, The cache is inconsistent with the double write of the database
In the case of ultra-high concurrency, there may be data inconsistency when operating the database and cache at the same time.
1. Double write inconsistency
Explain what double write inconsistency is through a diagram
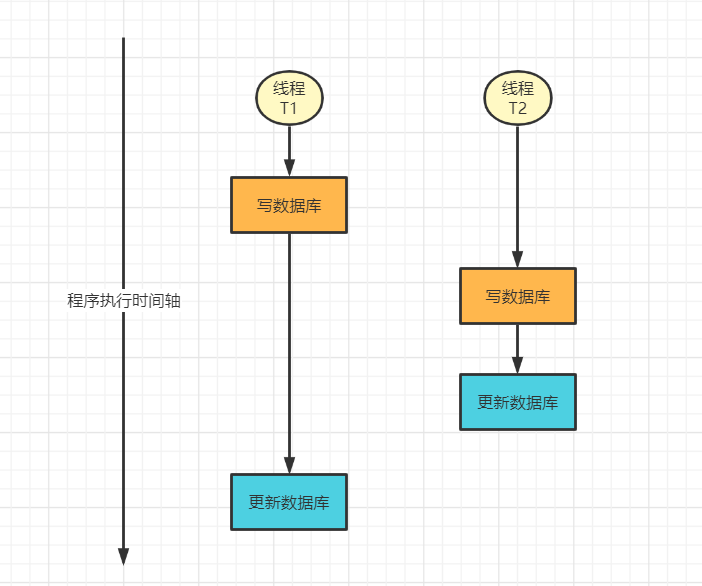
As can be seen from the above figure, there are two threads T1 and T2. T1 starts to write the database first. After a while, T2 also starts to write the database. T2 finishes writing the database and updates the latest data to the cache. At this time, T1 thread completes the write operation to the database. The data is also updated to the cache. Obviously, the latest data in the database should be T2, but T1 is in the cache. This is double write inconsistency.
2. Inconsistent read-write concurrency
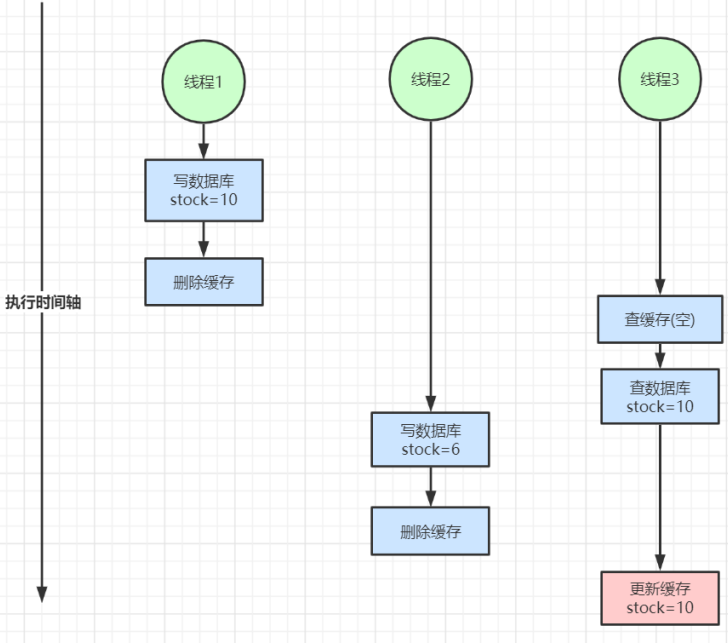
The read-write concurrency is inconsistent, as shown in the figure above. When the double write is inconsistent, someone on the Internet burst out saying "delayed double deletion". As the name suggests, it is to delay the deletion for a period of time. The question is, how long is it appropriate to delay the deletion. So the fundamental problem was not solved.
3. Solution:
1. For data with low concurrency probability (such as order data and user data in personal dimension), this problem hardly needs to be considered. Cache inconsistency rarely occurs. You can add expiration time to the cached data and trigger active update of read at regular intervals.
2. Even if the concurrency is high, if the business can tolerate the inconsistency of cache data for a short time (such as commodity name, commodity classification menu, etc.), the cache plus expiration time can still meet the cache requirements of most businesses.
3. If inconsistent cache data cannot be tolerated, you can add read-write locks to ensure that concurrent reads and writes or writes are queued in order, which is equivalent to no lock.
4. Alibaba's open source canal can also be used to modify the cache in time by listening to the binlog log of the database. However, a new middleware is introduced, which increases the complexity of the system.
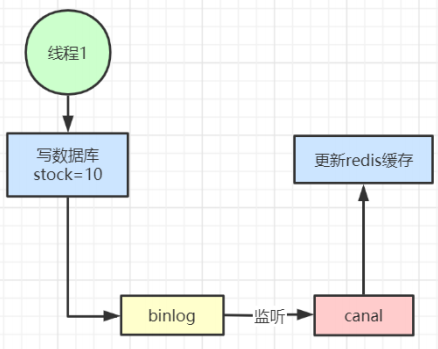
6, Summary
We are aiming at the situation of more reads and less writes, adding cache to improve performance. If the situation of more writes and more reads cannot tolerate inconsistent cache data, there is no need to add cache, and you can directly operate the database. The data put into the cache should be data that does not require high real-time and consistency. Remember not to over design and control in order to use cache and ensure absolute consistency, which will increase the complexity of the system.