2.1 introduction to machine learning process
2.1.1 overall process of machine learning
Next, the implementation process of "supervised learning", which is the most widely used of three types of machine learning methods, is described. The implementation process of supervised learning can be summarized into the following steps:
- collecting data
- Data cleaning (removing duplicate or missing data to improve data accuracy)
- Using machine learning algorithm to learn data
- Use the test data set to evaluate the performance of the model
- Install the machine learning model into the application environment such as web pages
In the above five steps, only 3 will use machine learning technology. In fact, data collection and data cleaning are the most important steps, and it takes a lot of time.
2.1.2 data learning
In the process of data learning, various machine learning algorithms will be used, such as:
- support vector machines
- Random forest algorithm
- KNN nearest neighbor algorithm
- Decision tree algorithm
- BP neural network and so on
-We need to use these algorithms to find the features and patterns contained in the data, and then classify and predict the data.
2.2 use of learning data
2.2.1 learning data and test data
In the process of supervised learning, we need to divide the data into "training data" and "test data". Instead of learning all the data in one brain, we set aside some data to test the trained model. More generally speaking, the accuracy of the trained model is not necessarily very good, If we don't take out part of the data for testing, we are likely to get the wrong results.
In most cases, we choose 20% of the overall data as the test data.
2.2.2 theory and practice of retention method
Next, the method of dividing data is introduced: setting aside method and k-fold cross validation. First, the setting aside method is introduced. The so-called set aside method, as the name suggests, is a simple method to divide the given data set into training set and test set. When using machine learning algorithm, we usually use the third-party software library in Python: scikit learn. When using scikit learn to practice the set aside method, we need to use train_ test_ The split() function is used as follows:
############Import modules to be used#########################
from sklearn import datasets
from sklearn.model_selection import train_test_split
#############Read named iris Data set of#####################
iris=datasets.load_iris()
x=iris.data
y=iris.target
####################Save data to using set aside method“ x_train,x_test,y_train,y_test"in,###########
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=0)
############################Confirm the size of training data and test data########################
print('x_train:',x_train.shape)
print('x_test',x_test.shape)
print('y_train:',y_train.shape)
print('y_test:',y_test.shape)
| parameter | meaning |
|---|---|
| x_train | X in training set (independent variable) |
| x_test | X (independent variable) in the test set |
| y_train | Tags in training set |
| y_test | Label in test set |
| test_size | Proportion of test set, usually 0.2 |
| random_state | When 0 is specified, the test set will be fixed and will not be changed randomly. It is usually specified as 0 |
2.2.3 theory of k-fold cross validation
K-fold cross validation is a method of model evaluation and validation. It uses sampling without putting back (the sampled data will not be put back to the original data set), divides the training set into k subsets, uses the k-1 subset data as the learning data set, and uses the remaining 1 subset for model testing. In this way, we will get k models and corresponding K performance evaluation data. In this way, we will repeat the learning and evaluation K times, and finally take the average value of K performance evaluation data as the final result of the model.
Leave one cross validation method is a special method of k-fold cross validation. It sets the number of separated subsets to be the same as the number of data sets, that is, if you have 20 rows of data, leave one method to divide it into 20 subsets, that is, each row of data is a subset. When doing model training, test one row of data, The remaining 19 lines of data were used for training. This method is suitable for processing very small data sets (such as 50 ~ 100 rows).
2.2.4 practice of k-fold cross validation
Python implementation of classic k-fold cross validation:
'''Through adjustment cv=k Medium k Value, the score will be different'''
from sklearn import svm,datasets #Import the required SVM algorithm package and data set
from sklearn.model_selection import cross_val_score #Import k-fold cross validation function
iris=datasets.load_iris() #Import the required iris dataset
x=iris.data #Gets the value of the data argument
y=iris.target #Gets the label of the data
svc=svm.SVC(C=1,kernel='rbf',gamma=0.001) #Using SVM algorithm
scores=cross_val_score(svc,x,y,cv=5) #Calculate the cross validation score, and the internal data X and y of the program will be divided into x_train,x_test,y_train,y_test form
print(scores) #Output the score of each verification
print('Average score:',scores.mean()) #Output average score
'''
[0.86666667 0.96666667 0.83333333 0.96666667 0.93333333]
Average score: 0.9133333333333334
'''
Leave one method for Python code implementation
from sklearn import datasets from sklearn.model_selection import LeaveOneOut from sklearn.model_selection import cross_val_score #Import k-fold cross validation function from sklearn import svm svc=svm.SVC(C=1,kernel='rbf',gamma=0.001) iris=datasets.load_iris() x=iris.data[0:70] #Select the first 70 rows of the dataset y=iris.target[0:70] #ditto loo=LeaveOneOut() #Call leave one method scores=cross_val_score(svc,x,y,cv=loo) print(scores.mean()) #Output average score ''' The average score is 0.7142857142857143 '''
From the final average score of the leave one method, the result is not very satisfactory, which is related to the selection of the model and the amount of data.
2.3 over fitting
2.3.1 what is overfitting
Let me use a diagram to explain what is over fitting:
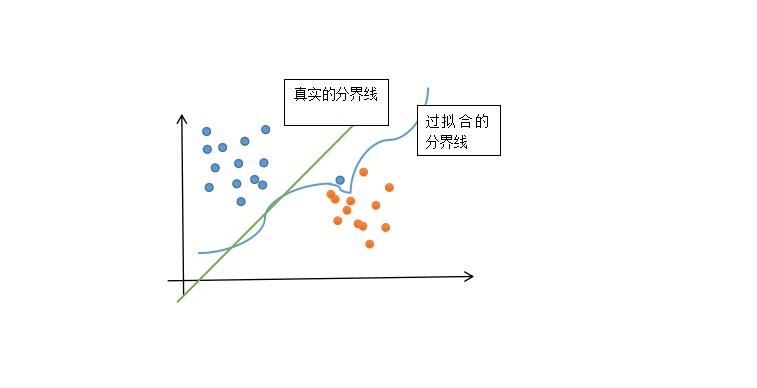
As shown in the figure, we currently have two types of data sets, blue and orange. We can clearly see that one blue data point deviates from the position of the normal situation. This situation is usually wrong data, that is, the data set with serious deviation. At this time, we let the computer classify it, Then the computer will be very "obedient" to process and classify these data. Finally, the computer will get a conclusion of "over fitting boundary", and the correct answer to the boundary is the green line. Therefore, we can see that the classification plane is affected by one of the data and can not draw the correct boundary. The state caused by the over learning of the data by the computer is called "over fitting"
2.3.2 how to avoid over fitting
- In deep learning, we often use dropout method to prevent over fitting
- In other machine learning algorithms, we often normalize the data before learning
Let's talk about what is normalization.
Normalization processing
Normalization, as the name suggests, is to map data values to
[
0
,
1
]
[0,1]
[0,1] interval, the simplest normalization method is:
d
a
t
a
n
e
w
=
d
a
t
a
o
l
d
−
d
a
t
a
m
i
n
d
a
t
a
m
a
x
−
d
a
t
a
m
i
n
data_{new}=\frac{data_{old}-data_{min}}{data_{max}-data_{min}}
datanew=datamax−datamindataold−datamin
In this way, we have made such a mapping:
d
a
t
a
→
[
0
,
1
]
data\to[0,1]
data→[0,1]
2.4 integrated learning
Ensemble learning is a method to realize the generalization of data through multiple training models. There are two common methods:
- Bagging algorithm is a method that allows multiple models to learn at the same time and enhances the generalization performance of model prediction results by averaging the prediction results.
- The promotion algorithm improves the generalization performance by generating the corresponding model according to the prediction results of the model.
Previous articles: