preface:
There are many kinds of text processors or text editors in Linux/UNIX system, including VIM editor and grep, which we have learned before.
grep, sed and awk are text processing tools often used in shell programming, which are called three swordsmen of shell programming.
1, sed editor
(1) Overview of sed editor
sed is a flow editor, which edits the data flow based on a set of rules provided in advance before the editor processes the data.
The sed editor can process the data in the data stream according to the commands, which are either input from the command line or stored in a command text file.
(2) The workflow of and sed mainly includes three processes: reading, executing and displaying:
Read: sed reads a line from the input stream (file, pipe, standard input) and stores it in a temporary buffer (also known as pattern space)
Execute: by default, all sed commands are executed sequentially in the mode space. Unless the address of the line is specified, the SED command will be executed successively on all lines.
Display: send the modified content to the output stream. After sending data, the mode space will be cleared. Before all the contents of the file are processed, the above process will be repeated until all the contents are processed.
Before all the contents of the file are processed, the above process will be repeated until all the contents are processed.
Note: by default, all sed commands are executed in the mode space, so the input file will not change unless the output is stored by redirection.
(3) . command format:
Format 1: sed -e 'operation' File 1 file 2 ......
Format 2: sed -n -e 'operation' File 1 file 2 .......
Format 3: sed -f Script file 1 file 2 .......
Format 4: sed -i -e 'operation' File 1 file 2.......
Format 5:
sed -e ' n {
Operation 1
Operation 2
.......
}' File 1 file 2......
(4) Common sed command options
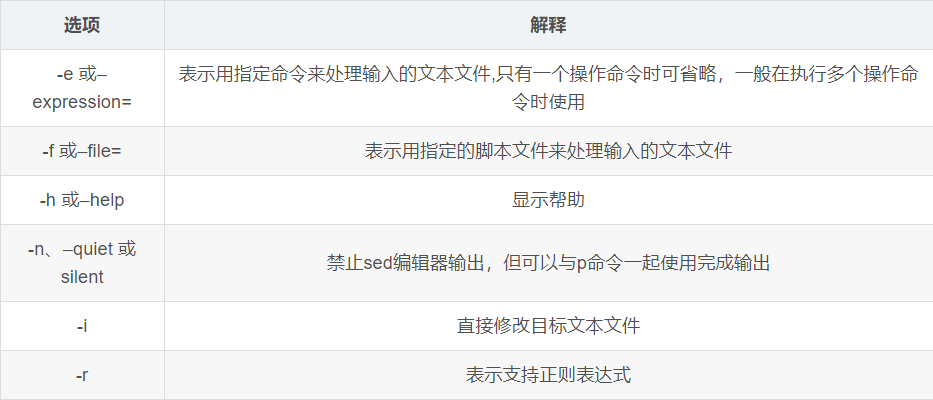
(V) common operation
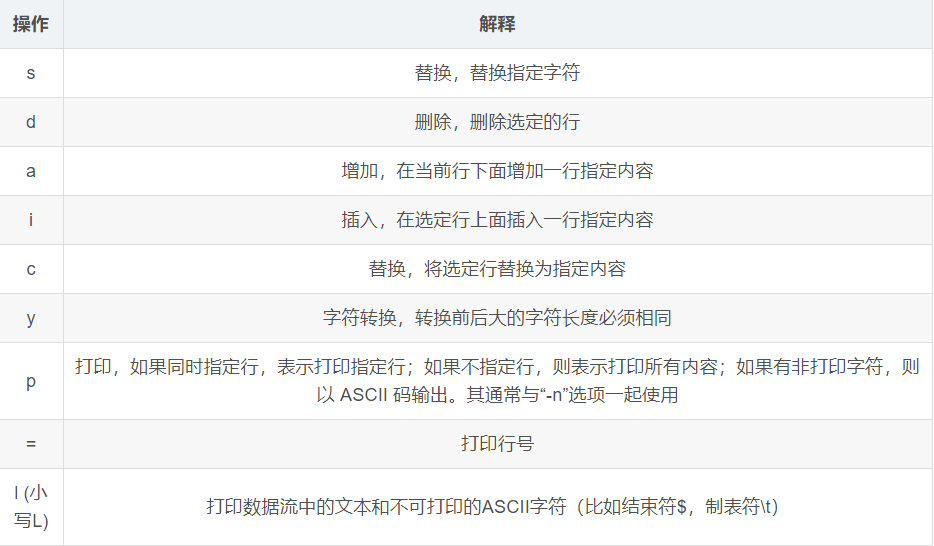
(6) Operation example:
1. Print text content
#First, create the following text for demonstration [root@gcc zhengze1]#vim testfile1 one two three four five six seven eight nine ten eleven twelve
(1) . print content
[root@gcc zhengze1]#sed -n -e 'p' testfile1 #-When n and - p are used together, it means that the content is printed once. If - n is not added, the content is printed twice one two three four five six seven eight nine ten eleven twelve
(2) . print line number
[root@gcc zhengze1]#sed -n -e '=' testfile1 # -n -e '=' is to print only the line number 1 2 3 4 5 6 7 8 9 10 11 12 [root@gcc zhengze1]#sed -e '=' testfile1 #If - n is not added, both the line number and the content are printed [root@gcc zhengze1]#sed -n '=;p' testfile1 #The result is the same as above, both line number and content are printed [root@gcc zhengze1]#sed -n -e '=' -e 'p' testfile1 #The result is the same as above, indicating that the line number is printed first and then the content is printed [root@gcc zhengze1]#sed -n ' #This method uses less, but it also means that the line number is printed first and then the content is printed = p ' testfile1 #Then, if you want to print the content first and then the line number, you can use the operation 'p' first and then the operation '=' ----------------------------------------------------------------- 1 one 2 two 3 three 4 four 5 five 6 six 7 seven 8 eight 9 nine 10 ten 11 eleven 12 twelve
(3) Printing ASCII characters
[root@gcc zhengze1]#sed -n -e 'l' testfile1 #Plus - l is to print ASCII characters one$ two$ three$ four$ five$ six$ seven$ eight$ nine$ ten$ eleven$ twelve$
2. Use address
sed editor has two addressing modes:
- The row interval is expressed in numerical form
- Use text mode to filter travel
--------------------The following is the content of line interval in digital form----------------------
[root@gcc zhengze1]#sed -n '1p' testfile1 #Print the contents of the first line
one
[root@gcc zhengze1]#sed -n '$p' testfile1 #Print the contents of the last line
twelve
[root@gcc zhengze1]#sed -n '1,3p' testfile1 #Print 1-3 lines
one
two
three
[root@gcc zhengze1]#sed -n '3,$p' testfile1 #Print 3 to the last line
three
four
five
six
seven
eight
nine
ten
eleven
twelve
[root@gcc zhengze1]#sed -n '1,+3p' testfile1 #Print three lines after the first line, that is, 1 to 4 lines
one
two
three
four
[root@gcc zhengze1]#sed '5q' testfile1 #Exit after printing the first 5 lines. Note that there is no - e here
one
two
three
four
five
[root@gcc zhengze1]#sed -n 'p;n' testfile1 #Print odd lines, which means to use p to print the first line first, and then n to skip one line and print it until the end
one
three
five
seven
nine
eleven
[root@gcc zhengze1]#sed -n 'n;p' testfile1 #Print even lines, which means skip one line at a time from the first line
two
four
six
eight
ten
[root@gcc zhengze1]#sed -n '2,${n;p}' testfile1 #This command also means printing odd lines
three
five
seven
nine
eleven
--------------------------------The following is the text mode to filter travel-------------------------------------
[root@gcc zhengze1]#sed -n '/user/p' /etc/passwd #/User / means to filter out the line with the string user. Remember to add / / and distinguish the case of letters in / /
saslauth:x:996:76:Saslauthd user:/run/saslauthd:/sbin/nologin
rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
qemu:x:107:107:qemu user:/:/sbin/nologin
radvd:x:75:75:radvd user:/:/sbin/nologin
[root@gcc zhengze1]#sed -n '/^a/p' /etc/passwd #Filter out lines starting with a
adm:x:3:4:adm:/var/adm:/sbin/nologin
abrt:x:173:173::/etc/abrt:/sbin/nologin
avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
[root@gcc zhengze1]#sed -n '/bash$/p' /etc/passwd #Filter out lines ending in bash
root:x:0:0:root:/root:/bin/bash
gcc:x:1000:1000:gcc:/home/gcc:/bin/bash
wangyi:x:1001:1001::/home/wangyi:/bin/bash
wanger:x:1002:1002::/home/wanger:/bin/bash
wangsan:x:1003:1003::/home/wangsan:/bin/bash
wangsi:x:1004:1004::/home/wangsi:/bin/bash
[root@gcc zhengze1]#sed -n '/ftp\|root/p' /etc/passwd #Print lines with ftp or ("|) root, and add escape character \ here to prevent | from having other meanings, such as | having the function of pipe symbol
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
[root@gcc zhengze1]#sed -n '2,/nobody/p' /etc/passwd #Print from the second line until the first line with nobody stops
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
[root@gcc zhengze1]#sed -nr '/ro{1,}t/p' /etc/passwd #Add r to support regular expressions, ro{1,}t to match the leading character o at least once
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
3. Delete row
[root@gcc zhengze1]#sed 'd' testfile1 #Delete all rows [root@gcc zhengze1]# [root@gcc zhengze1]#sed '3d' testfile1 #Delete the third line one two four five six seven eight nine ten eleven twelve [root@gcc zhengze1]#sed '2,9d' testfile1 #Delete lines 2-9 one ten eleven twelve [root@gcc zhengze1]#sed '$d' testfile1 #Delete last line [root@gcc zhengze1]#sed '/^$/d' testfile1 #Delete empty lines [root@gcc zhengze1]#sed -i '/^$/d' testfile1 #Because all the previous printed contents are not directly modified files, if you want to modify the file contents, you can use the - i operation to modify them directly [root@gcc zhengze1]#sed '/nologin$/d' /etc/passwd #Delete lines ending with nologin [root@gcc zhengze1]#sed '/nologin$/!d' /etc/passwd #! Indicates the reverse operation, that is, all lines except those ending in nologin are deleted [root@gcc zhengze1]#sed '/2/,/3/d' testfile2 #Turn on the line deletion function from the first position to turn off the line deletion function from the second position, that is, delete from the first line with character 2 to the line with character 3
4. Replace
Format:
Row range s/Old string/New string/Replace tag
- 4 replacement marks
Number: indicates where the new string will replace the first match
g: Indicates that the new string will replace all matches
p: Print lines that match the replace command, used with - n
w file: write the replacement result to the file[root@gcc zhengze1]#sed -n 's/root/admin/p' /etc/passwd #Replace the first root with admin and print it out. Note that only the first root is replaced. If there is a second root after the same line, the third root will not be replaced admin:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/admin:/sbin/nologin [root@gcc zhengze1]#sed -n 's/root/admin/2p' /etc/passwd #Replace the second root in a row with admin. Note that only the second root in a row is replaced, and other roots in the same row are not replaced root:x:0:0:admin:/root:/bin/bash [root@gcc zhengze1]#sed -n 's/root/admin/gp' /etc/passwd #Replace all root s, no matter the first or several admin:x:0:0:admin:/admin:/bin/bash operator:x:11:0:operator:/admin:/sbin/nologin [root@gcc zhengze1]#sed -n 's/root//GP '/ etc / passwd # delete all root s :x:0:0::/:/bin/bash operator:x:11:0:operator:/:/sbin/nologin [root@gcc zhengze1]#sed '1,20 s/^/#/' /etc/passwd #Will 1-20 Add at the beginning of line#number #root:x:0:0:root:/root:/bin/bash #bin:x:1:1:bin:/bin:/sbin/nologin #daemon:x:2:2:daemon:/sbin:/sbin/nologin #adm:x:3:4:adm:/var/adm:/sbin/nologin #lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@gcc zhengze1]#sed -n '/^root/ s/$/#/p' /etc/passwd #In order root Add at the end of the first line#number root:x:0:0:root:/root:/bin/bash# [root@gcc zhengze1]#vim script.sed #Create a script for the sed command s/2/666/ #Replace 2 with 666, and so on s/3/777/ s/100/888 [root@gcc zhengze1]#sed -f script.sed testfile2 #Then you can directly use the script to operate on file 2 ....... [root@gcc zhengze1]#sed '1,20w out.txt' /etc/passwd #Save 1-20 lines of output in / etc/passwd to out Txt file [root@gcc zhengze1]#sed '1,20 s/^/#/w out.txt' /etc/passwd #take/etc/passwd 1 in-20 Add at the beginning of line#Save to out Txt file [root@gcc zhengze1]#sed -n 's/\/bin\/bash/\/bin\/csh/p' /etc/passwd #Replace / bin/bash with / bin/csh. The escape character "\" is added before "/". Because "/" has other functions, it needs to be limited by the escape character [root@gcc zhengze1]#sed -n 's!/bin/bash!/bin/csh!p' /etc/passwd #It looks messy, so we can use "!" As the separator of the string, but the meaning is the same as the above command
5. Insert
[root@gcc zhengze1]#sed '/45/c ABC' testfile2 #Replace 45 lines with ABC [root@gcc zhengze1]#sed '/45/ y/45/AB/' testfile2 #Replace content 45 with AB. note that when using "y", the length of characters before and after conversion must be the same [root@gcc zhengze1]#sed '1,3a ABC' testfile1 #In lines 1-3, insert ABC below each line one ABC two ABC three ABC four five six [root@gcc zhengze1]#sed '1i ABC' testfile1 #Insert ABC above the first line ABC one two three [root@gcc zhengze1]#sed '1r /etc/resolv.conf' testfile1 #"- r" is the operator read in. This command means that / etc / reslv The contents of conf are read into the testkey 1 file below the first line one # Generated by NetworkManager nameserver 192.168.200.2 two three [root@gcc zhengze1]#sed '/root/{H;d};$G' /etc/passwd #Cut the line with / root to the end, H means copy to the clipboard, d means delete, and G means paste after the specified line [root@gcc zhengze1]#sed '1,2H;3,4G' testfile1 #Copy lines 1 and 2 below lines 3 and 4. Note that the contents of lines 1 and 2 will be copied in the third and fourth lines one two three one two four one two five six seven2, awk editor
In Linux/UNIX system, awk is a powerful editing tool. It reads the input text line by line, looks up according to the specified matching pattern, and formats and outputs or filters the qualified content. It can realize quite complex text operations without interaction. It is widely used in Shell scripts to complete various automatic configuration tasks.
(1) Working principle:
Read the text line by line. By default, it is separated by space or tab key. Save the separated fields to the built-in variable, and execute the editing command according to the mode or condition.
-
The sed command is often used to process a whole line, while awk prefers to divide a line into multiple "fields" and then process it. The reading of awk information is also read line by line. The execution result can be printed and displayed through the function of print. In the process of using the awk command, you can use the logical operators "& &" to represent "and", "||" to represent "or" and "!" to represent "not"; you can also carry out simple mathematical operations, such as +, -, *, /,%, ^ to represent addition, subtraction, multiplication, division, remainder and power respectively.
-
(2) . command format:
awk option 'Mode or condition {operation}' File 1 file 2... awk -f Script file 1 Document 2...(3) awk common built-in variables (which can be used directly) are as follows:
- FS: column delimiter. Specifies the field separator for each line of text, which defaults to spaces or tab stops. Same as "- F"
NF: the number of fields in the currently processed row.
Number of rows currently processed (NR)
$0: the whole line content of the currently processed line.
$n: the nth field of the current processing line (column n)
FILENAME: the name of the file being processed.
Rs: line separator. When awk reads data from a file, it will cut the data into many records according to the definition of RS, while awk only reads one record at a time for processing. The default is' \ n '(4) . example:
1. Output text by line
Output all contentawk '{print)' testfile1 #Output all content awk '{print $0}' testfile1 #Output all contentExample:
[root@gcc zhengze1]#awk '{print}' testfile1 #Output all content one two three four five six seven eight nine ten eleven [root@gcc zhengze1]#awk '{print $0}' testfile1 #Like the above command, it also outputs all the contents one two three four five six seven eight nine ten eleven twelveOutput the contents of the specified line
awk 'NR==1, NR==3{print}' testfile1 #Output lines 1-3 awk '(NR>=1) && (NR<=3) {print}' testfile1 #Output lines 1-3 awk 'NR==1 || NR==3 {print}' testfile1 #Output the contents of line 1 and line 3Example:
[root@gcc zhengze1]#awk 'NR==1,NR==3{print}' testfile1 #Output lines 1-3 one two three [root@gcc zhengze1]#awk '(NR>=1)&&(NR<=3){print}' testfile1 #Output lines 1-3 one two three [root@gcc zhengze1]#awk 'NR==1||NR==3{print}' testfile1 #Output the contents of line 1 and line 3 one threeOutput odd and even lines
awk '(NR%2)==1{print}' testfile1 #Output odd rows awk '(NR%2)==0{print}' testfile1 #Output even rowsExample:
[root@gcc zhengze1]#awk '(NR%2)==1{print}' testfile1 #Output odd lines one three five seven nine eleven [root@gcc zhengze1]#awk '(NR%2)==0{print}' testfile1 #Output even lines two four six eight ten twelveOutput the contents of lines beginning with... And ending with
awk '/^root/{print}' /etc/passwd #Output content starting with root awk '/nologin$/{print}' /etc/passwd #Output content ending with nologinExample:
[root@gcc zhengze1]#awk '/^root/{print}' /etc/passwd root:x:0:0:root:/root:/bin/bash [root@gcc zhengze1]#awk '/nologin$/{print}' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologinCount the number of lines ending with
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd #Count the number of lines ending in / bin/bash, which is equal to grep -c "/bin/bash$" /etc/passwdBEGIN mode means that you need to perform the actions specified in BEGIN mode before processing the specified text; awk processes the specified text and then executes the actions specified in the END mode. In the END {} statement block, statements such as print results are often placed.

2. Output text by field
-
awk -F ":" '{print }' /etc/passwd # output the third field in each line (with ":" split ")
awk -F ":" '{print ,}' /etc/passwd # output the first and third fields in each line (divided by ":"
Awk - F ":" '$3 < 5 {print $1, $3}' / etc / passwd # outputs the first and third fields of the row whose value of the third field is less than 5
awk -F ":" '! ($3 < 200) {print} '/ etc / passwd # outputs the contents of the row whose value of the third field is not less than 200
awk 'BEGIN {FS=":"}; {if ($3 > = 200) {print}} '/ etc/passwd # first process the content in begin (change the column separator to:) and then print the content in the text (if the value of the third paragraph is greater than or equal to 200, output it)
awk -F ":" '{max=($3>$4)?$3:$4;{print max}}' /etc/passwd
#($3>$4)?$ 3: $4 is a ternary operator. If the value of the third field is greater than the value of the fourth field, assign the value of the third field to max; otherwise, assign the value of the fourth field to maxawk -F ":" '{print NR,Awk - F ":" '{print NR, $0}' / etc / passwd }' /etc/passwd # outputs the content and line number of the inner line. If a record is not processed, the NR value (the line number of the currently processed line) is increased by 1
awk -F ":" '~"/bash"{print }' /etc/passwd # output the first field of the row separated by colon and containing / bash in the seventh field
awk -F ":" '($1 to "root") & & (NF = = 7) {print $1, $2}' / etc / passwd # output the first and second fields of the row with root and 7 fields in the first field (NF: the number of fields of the row currently processed)
Awk - F ":" '($7! = "/ bin/bash") & & ($7! = "/ sbin/nologin") {print}' / etc / passwd # output the seventh field is not / bin/bash, nor all lines of / sbin/nologin
-
3. Call shell commands through pipe symbols and double quotes
echo $PATH | awk 'BEGIN{RS=":"};END{print NR} '# counts the number of text paragraphs separated by colons. In the END {} statement block, statements such as print results are often placed
awk -F ":" '/bash$/{print | "wc -l"}' /etc/passwd
#Call the wc -l command to count the number of users using bash (i.e. lines ending in Bash), which is equivalent to
grep -c "bash$" /etc/passwd
free -m | awk '/Mem:/ {print int(/(+)*100) "%"}' # view the current memory usage percentage (int refers to character type, which represents integer type, that is, there is no decimal point)
top -b -n 1 | grep Cpu | awk -F ',' '{print $4}' | awk '{print $1}'
#View the current cpu idle rate (- b -n 1 means only one output is required)
The whole sentence command means: dynamically output the result of a process (top -b -n 1); Filter out the Cpu line (grep Cpu); Separated by commas, print out the fourth column (awk - f ',' {print $4} '); Then print out the first value of the filtered fourth column (awk '{print $1}')
date -d "$(awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H:%M:%S"
#Displays the time of the last system restart, which is equivalent to uptime: second ago is the time before the display, and + "% F% H:% m:% s" is equivalent to the time format of + "% Y -% m -% d% H:% m:% s"
awk 'BEGIN {n=0 ; while ("w" | getline) n++ ; {print n-2}}'
#Call the w command and use it to count the number of online users; The w command can obtain the detailed information of the current online user; getline is to get the line; Printing n-2 lines is because the first two lines of W displayed information are useless, so the first two lines are removed.
[root@gcc zhengze1]#w
15:41:01 up 19:50, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 192.168.200.1 11:19 5.00s 0.12s 0.01s w
Awk 'begin {"hostname" | getline; {print $0}}' # call the hostname command to output the current hostname
----------------------------------------------------------------------------------------------------------------------------------------------------------------
When there is no redirection character "<" or "|" around getline, awk first reads the first line, which is 1, and then getline gets the second line below 1, which is 2. Because after getline, awk will change the corresponding internal variables such as NF, NR, FNR and $0, so the value of $0 is no longer 1, but 2, and then print it out.
When the file is just read in with the character "getawline", it is only read in with the character "getawline". When the file is just read in, it is not read in with the character "getawline".
seq 10 | awk '{getline; print Seq 10 | awk '{getline; print $0)')' # can get even lines
seq 10 | awk '{print Seq 10 | awk '{print $0; getline}; getline}' # can get odd rows
4. CPU utilization
cpu_us='top -b -n 1 | grep Cpu | awk '(print $2}'
cpu_sy='top -b -n 1 | grep Cpu | awk -F ',' '{print $2}' | awk '{print $1}'
cpu_sum=$ ( ($cpu_us+$cpu_sy))
echo $cpu_sum
summary
grep ,sed,awk