Programming problem
prices = {
'AAPL': 191.88,
'GOOG': 1186.96,
'IBM': 149.24,
'ORCL': 48.44,
'ACN': 166.89,
'FB': 208.09,
'SYMC': 21.29
}
1. Some stock codes (keys) and prices (values) are saved in the dictionary. Use one line of code to find the stock with the highest price and output the stock code. (5 points)
max(prices,key = lambda x : prices[x]) # 'GOOG'
max(prices,key = prices.get) # 'GOOG'
2. Some stock codes (keys) and prices (values) are saved in the dictionary. Use one line of code to sort the dictionary according to the stock price from high to low, and output the list of stock codes. (5 points)
sorted(prices,key = lambda x:prices[x],reverse = True) # ['GOOG', 'FB', 'AAPL', 'ACN', 'IBM', 'ORCL', 'SYMC'] # Reverse -- collation, reverse = True descending, reverse = False ascending (default).
sorted(prices,key = prices.get) # ['SYMC', 'ORCL', 'IBM', 'ACN', 'AAPL', 'FB', 'GOOG']
Solving problems with pandas 1,2
import numpy as np import pandas as pd df = pd.DataFrame(data = prices.values(),index = prices.keys() ,columns = ['prices']) # 1 df.prices.nlargest(1).index # Index(['GOOG'], dtype='object') # 2 df.prices.sort_values(ascending = False).index # Index(['GOOG', 'FB', 'AAPL', 'ACN', 'IBM', 'ORCL', 'SYMC'], dtype='object')
3. Design a function to generate a verification code with a specified length. The verification code is composed of upper and lower case English letters and numbers. (10 points)
Stupid method: first list the upper and lower case English letters and numbers, and generate the index according to the random number of the specified length to form the verification code
import random
list1 = ['a','b','c','d','e','f','g','h','i','g','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','A','B','C','D','E','F','G','H','I','G','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z','1','2','3','4','5','6','7','8','9','0']
length = len(list1)
# print(length)
def func_1(n):
res = []
for _ in range(n):
res.append(list1[random.randint(0,length)])
return ''.join(res)
print(func_1(10))
Reference answer: directly call the list of letters and numbers in string, using random Choose a verification code of the specified length
import string
all_chars = string.ascii_letters + string.digits
def random_code(length = 4):
return ''.join(random.choices(all_chars,k=length))
Note: because you are modifying named variables, you need to write "variable name = set value" when modifying the default parameter value of variables“
for _ in range(10):
print(random_code(length = 7))
"""
LxTjoyk
DK4wI9Q
ASc2jB4
r61h4VY
8vilgaR
mMbxDAq
aY6EoRo
Mvd50Pd
y2kFI9W
96fFYhl
"""
4. Design a function to count the number of occurrences of English letters and numbers in the string and return them in the form of two tuples. (10 points)
Using regular expressions to solve problems
import re
def func_2(data):
length = len(data)
num = re.sub(r'\D',"",data) # Replace non numeric characters with empty strings
return length-len(num),len(num)
data2 = 'abc23543RFGV'
print(func_2(data2)) # (7, 5)
Reference answer: define two counters to count letters and numbers respectively
def count_(content:str):
letters_count,num_count = 0,0
for x in content:
if 'a' <= x <= 'z' or 'A' <= x <= 'Z':
letters_count+=1
if '0' <= x <= '9':
num_count+=1
return letters_count,num_count
print(count_('abc23543RFGV')) # (7, 5)
5. Design a function to count the characters with the highest frequency in a string and their occurrence times, and return them in the form of binary. Note that there may be more than one character with the highest frequency. (10 points)
Reference answer:
def find_highest_freq(content:str):
info={}
for ch in content:
info[ch] = info.get(ch,0) + 1 # Get each character of the string one by one, take the character as the key to get the corresponding value, and the value + 1 updates the value corresponding to the corresponding key in the dictionary
max_count = max(info.values())
return [key for key,value in info.items() if value == max_count],max_count
# Dictionaries. get(key, default value) - get the value corresponding to the specified key in the dictionary. If the key does not exist, the default value will be returned
verification
find_highest_freq('aabbccaacc') # (['a', 'c'], 4)
6. There are 1000000 elements in the list, and the value range is [1000, 10000). Design a function to return the repeated elements in the list. Please take the execution efficiency of the function into account. (10 points)
Reference answer: space for time
def find_duplicates(nums):
counters = [0]*10000 # Create an array with a length of 10000 and an element of 0. The value corresponding to the array subscript is the number of occurrences of the subscript value in the given array
for num in nums:
counters[num] += 1 # Take out each number and modify the value of the corresponding subscript of the count array plus 1
return [index for index,item in enumerate(counters) if item >1] # Returns the subscript value with value > 1 in the count array
verification
find_duplicates([1111,1111,1112,1113,1112]) # [1111 , 1112]
database
1. There are tb_student and tb_myopia as shown below to query the names of students without myopia. (10 points) (183 points deducted for similar problems)
# # tb_student # +---------+-----------+ # | stu_id | stu_name | # +---------+-----------+ # | 1 | Alice | # | 2 | Bob | # | 3 | Jack | # | 4 | Jerry | # | 5 | Tom | # +---------+-----------+ # # tb_myopia # +------+------------+ # | mid | stu_id | # +------+------------+ # | 1 | 3 | # | 2 | 2 | # | 3 | 5 | # +------+------------+
Build table
create table tb_student ( stu_id int unsigned auto_increment, stu_name varchar(20) not null , primary key (stu_id) ); create table tb_myopia ( `mid` int unsigned auto_increment, stu_id int not null, primary key (`mid`) ); insert into tb_student (stu_id,stu_name) values (1,'Alice'), (2,'Bob'), (3,'Jack'), (4,'Jerry'), (5,'Tom'); insert into tb_myopia (`mid`,stu_id) values (1,3), (2,2), (3,5);
Method 1: sub query + not in
Idea: select stu_ Name of student whose ID is not in the myopia table
select stu_name from tb_student where stu_id not in (select stu_id from tb_myopia);
Method 2: left outer connection
Idea: the final choice is the left table, and the right table does not. Select the left outer connection, and the condition is where mid is null / where stu_id is null
select stu_name from tb_student t1 left join tb_myopia t2 on t1.stu_id=t2.stu_id where mid is null;
or
select stu_name from tb_student t1 left join tb_myopia t2 on t1.stu_id=t2.stu_id where t2.stu_id is null;
2. There are the following employee table (tb_emp) and department table (tb_dept). It is required to use the window function to query the employees with the highest salary (sal) in each department. (10 points) (185 questions deducted)
# # tb_emp # +-----+--------+--------+--------+ # | eno | ename | sal | dno | # +-----+--------+--------+--------+ # | 1 | Alice | 85000 | 1 | # | 2 | Amy | 80000 | 2 | # | 3 | Bob | 65000 | 2 | # | 4 | Betty | 90000 | 2 | # | 5 | Jack | 69000 | 1 | # | 6 | Jerry | 85000 | 1 | # | 7 | Martin | 72000 | 2 | # | 8 | Vera | 75000 | 1 | # +-----+--------+--------+--------+ # # tb_dept # +----+-------+ # | id | name | # +----+-------+ # | 1 | R&D | # | 2 | Sales | # +----+-------+
Build table
create table tb_emp ( eno int unsigned auto_increment, ename varchar(20) not null, sal int not null, dno int not null, primary key (eno) ); create table tb_dept ( id int not null, name varchar(20) ); insert into tb_emp (eno,ename,sal,dno) values (1,'Alice',85000,1), (2,'Amy',80000,2), (3,'Bob',65000,2), (4,'Betty',90000,2), (5,'Jack',69000,1), (6,'Jerry',85000,1), (7,'Martin',72000,2), (8,'Vera',75000,1); insert into tb_dept (id,name) values (1,'R&D'), (2,'Sales');
Idea: window function + sub query
select name `Department`,ename `Employee`,sal `Salary` from ( select name,ename,sal, dense_rank() over (partition by id order by sal desc) as rn from tb_emp t1, tb_dept t2 where t1.dno = t2.id ) temp where rn<=3;
Intermediate process (sub query):
select name,ename,sal, dense_rank() over (partition by id order by sal desc) as rn from tb_emp t1, tb_dept t2 where t1.dno = t2.id;
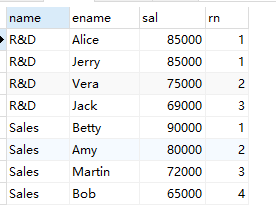
3. There is a table (tb_sales) as shown below, and it is required to find the results shown in the table (tb_result). (10 points)
# tb_sales # +------+---------+--------+ # | year | quarter | amount | # +------+---------+--------+ # | 2020 | 2 | 11 | # | 2020 | 2 | 12 | # | 2020 | 3 | 13 | # | 2020 | 3 | 14 | # | 2020 | 4 | 15 | # | 2021 | 1 | 16 | # | 2021 | 1 | 17 | # | 2021 | 2 | 18 | # | 2021 | 3 | 19 | # | 2021 | 4 | 18 | # | 2021 | 4 | 17 | # | 2021 | 4 | 16 | # | 2022 | 1 | 15 | # | 2022 | 1 | 14 | # +------+---------+--------+ # # tb_result # # +------+--------+--------+--------+--------+ # | year | Q1 | Q2 | Q3 | Q4 | # +------+--------+--------+--------+--------+ # | 2020 | 0 | 23 | 27 | 15 | # | 2021 | 33 | 18 | 19 | 51 | # | 2022 | 29 | 0 | 0 | 0 | # +------+--------+--------+--------+--------+
Table creation:
create table tb_sales ( year int not null, quarter int not null, amount int not null ); delete from tb_sales; insert into tb_sales values (2020,2,11), (2020,2,12), (2020,3,13), (2020,3,14), (2020,4,15), (2021,1,16), (2021,1,17), (2021,2,18), (2021,3,19), (2021,4,18), (2021,4,17), (2021,4,16), (2022,1,15), (2022,1,14);
Idea: aggregate function + (case when then else end)
Wide watch and narrow Watch
select year, sum(case quarter when 1 then amount else 0 end) as 'Q1', sum(case quarter when 2 then amount else 0 end) as 'Q2', sum(case quarter when 3 then amount else 0 end) as 'Q3', sum(case quarter when 4 then amount else 0 end) as 'Q4' from tb_sales group by year;
4. There is a table (tb_record) as shown below, in which the second column (income) represents everyone's income and counts the mode of income. (10 points)
# tb_record # +--------+--------+ # | name | income | # +--------+--------+ # | Alice | 85000 | # | Amy | 65000 | # | Bob | 65000 | # | Betty | 90000 | # | Jack | 82000 | # | Jerry | 65000 | # | Martin | 82000 | # | Vera | 85000 | # +--------+--------+
Build table
create table tb_record
(
name varchar(20) not null,
income int unsigned not null
);
insert into tb_record (`name` , income)
values
('Alice',85000),
('Amy',65000),
('Bob',65000),
('Betty',90000),
('Jack',82000),
('Jerry',65000),
('Martin',82000),
('Vera',85000);
Idea: ALL: if it is true compared with ALL the values returned by the sub query, it will return true
select income from tb_record group by income having count(*) >= all(select count(*) from tb_record group by income);
5. There is the following table (tb_login_log) to count the users who have logged in for three consecutive days (user_id). It is required to use the window function. (10 points)
Build table
create table tb_login_log
(
user_id varchar(10) not null,
login_date date not null
);
insert into tb_login_log(user_id,login_date)
values
('A','2019-09-02'),
('A','2019-09-03'),
('A','2019-09-04'),
('B','2018-11-25'),
('B','2018-12-31'),
('C','2019-01-01'),
('C','2019-04-04'),
('C','2019-09-03'),
('C','2019-09-04'),
('C','2019-09-05');
Idea: window function + sub query
select distinct user_id from ( select user_id,login_date, row_number() over (partition by user_id order by login_date) as rn from tb_login_log ) temp group by user_id,subdate(login_date,rn) having count(*) >= 3;