
Why write this?
I've wanted to write it for a long time, but there is a series of redis source code learning in front of me, which has been dragging on.
When I was studying protobuf, I saw a blog on the Internet. It was very good, but it was inserted as follows: fixed focuses on time and int focuses on space compared with int. So if you have requirements for space performance, use int.
Then I really believed it. Then I changed all int32 in the project agreement to fixed32, and gave me a meal of fierce operation.
Later, due to the incompleteness of the previous study, I went to the official website of protobuf to check the official documents and wanted to see if the man was right. Good guy, turn around. People just say that if there are frequent businesses in large numbers, consider using fixed. They don't say which is fast and which is slow...
Then I was confused. You know, my bishrie is almost decimal (less than 8 digits). Is what he said right or wrong???
Think about it. Let's see what's written in the source code.
code
Coding structure
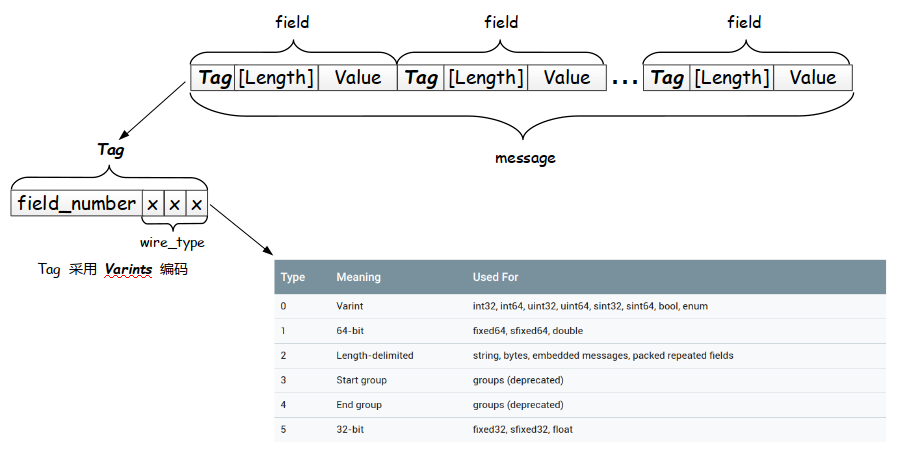
The [Length] here is optional. It means that different types of data coding structures may become in the form of Tag - Value. If it becomes such a form, how can we determine the boundary of Value without Length?
Note that the two types of Start group and End group have been abandoned.
So:
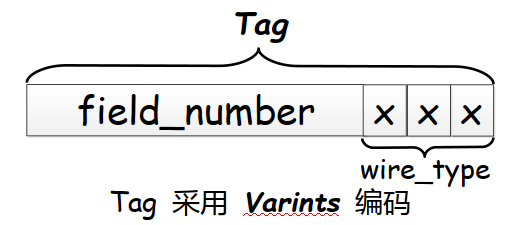
There will be some special coding (ZigTag coding) for sint32 and sint64, which is equivalent to two different codes in the coding type of Varint.
Now let's simulate that we have received a series of serialized binary data. We first read a Varints encoding block, decode Varints, and read the last 3 bit s to get wire_type (so we can know which code the following Value adopts), and then obtain the field_number (so we can know which field it is). According to wire_type to correctly read the following Value. Then continue to read the next field field
Varints code
1,At the beginning of each byte bit Set msb(most significant bit ),Identifies whether to continue reading the next byte 2,Store the binary complement corresponding to the number 3,The low order of the complement comes first
Take an example:
int32 val = 1; // Set the value of an int32 field val = 1; At this time, the coding results are as follows Original code: 0000 ... 0000 0001 // Original code representation of 1 Complement: 0000 ... 0000 0001 // Complement representation of 1 Varints Code: 0#000 0001 (0x01) / / Varints encoding of 1, where MSB of the first byte = 0
Coding process:
The number 1 corresponds to the complement 0000... 0000 0001 (Rule 2). Take every 7 bits from the end and reverse the sorting (Rule 3), because the rest of 0000... 0000 0001 is 0 except the first 7 bits (i.e. the last 7 bits of the original sequence). Therefore, only the first 7-bit group needs to be taken, and there is no need to take down another 7-bit, then the MSB of the first 7-bit group = 0. Finally:
0 | 000 0001(0x01)
Decoding process:
msb = 0 in the Varints code of the number 1, so you only need to read the first byte without reading it again. After removing the msb, the remaining 000 0001 is the reverse order of the complement, but there is only one byte here, so there is no need to reverse. Directly explain the complement 000 0001 and restore it to the number 1.
The number 1 is encoded here, and Varints uses only 1 byte. Under normal circumstances, int32 will use 4 bytes to store the number 1.
msb actually plays the role of Length. Because of msb (Length), we can get rid of the original dilemma that four bytes must be allocated regardless of the size of the number. With Varints, we can make small numbers represented in fewer bytes. Thus, space utilization and efficiency are improved.
Varints encoding of negative numbers
Not much to say, let's take a direct example:
int32 val = -1 Original code: 1000 ... 0001 // Note that here are 8 bytes Complement: 1111 ... 1111 // Note that here are 8 bytes
Review the Varints code again: take a group of 7 bit s for the complement code, and put the low bit in the front.
The above complement consists of 8 bytes and 64 bit s in total. It can be divided into 9 groups (the complement of negative numbers is different from that of positive numbers), and these 9 groups are all 1. The MSBs of these 9 groups are all 1. The 1 of the last bit is filled with 0 as the last group, and finally the Varints code is obtained:
1#1111111 ... 0#000 0001 (FF FF FF FF FF FF FF FF FF 01)
Note that because a negative number must be set to 1 in the highest bit (sign bit), this means that a negative number must occupy all bytes anyway, so its complement always occupies 8 bytes. You can't remove the extra high bits (all 0) like a positive number. With msb, the final result of Varints encoding will be fixed at 10 bytes.
That's why it's not good to store negative numbers directly with int in protoc ol.
ZigZag coding
It is recommended to store negative numbers. When using sint, ZigZag coding is adopted by default.
In fact, you can see from a picture:
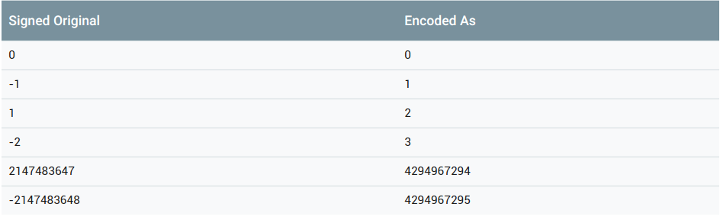
The "mapping" here is realized by shift.
bool
When boolVal = false, the encoding result is null.
Here is another trick ProtoBuf does to improve efficiency: specify a default value mechanism, and set the value of the field as the default value when the read field is empty. The default value of bool type is false. That is to say, if false is encoded and then transmitted (one byte is consumed), it is better not to output any encoding result directly (empty). When the terminal parses and finds that the field is empty, it will set its value as the default value (i.e. false) according to the regulations. In this way, space can be further saved and efficiency can be improved.
fixed family
Varints coding is efficient in a certain range. More bytes are occupied than a certain number, and the efficiency is lower. If there are a lot of big numbers in the current scene, it is not appropriate to use varints. Specifically, if the value is larger than 2 ^ 56, fixed64 is more efficient than uint64. If the value is larger than 2 ^ 28, fixed32 is more efficient than uint32.
example.set_fixed64val(1) example.set_sfixed64val(-1) example.set_doubleval(1.2) // The encoding result is always 8 bytes 09 # 01 00 00 00 00 00 00 00 11 # FF FF FF FF FF FF FF FF ff FF FF FF FF FF FF FF FF ff FF FF FF FF FF FF FF FF ff FF FF FF FF FF FF FF FF ff FF FF FF FF FF FF FF FF ff FF FF FF FF FF FF FF FF ff FF FF FF FF FF FF FF FF ff ff ff ff ff 19 # 33 33 33 33 33 33 F3 3F
fixed32, sfixed32 and float are the same as 64 bit
Variable length data type
string,bytes,EmbeddedMessage,repeated. The encoding structure of length defined type is Tag - Length - Value:
syntax = "proto3";
// message definition
message Example1 {
string stringVal = 1;
bytes bytesVal = 2;
}
Example1 example1;
example1.set_stringval("hello,world");
example1.set_bytesval("are you ok?");
0A 0B 68 65 6C 6C 6F 2C 77 6F 72 6C 64
12 0B 61 72 65 20 79 6F 75 20 6F 6B 3F
repeat
The coding structure of the original repeated field is Tag length Value Tag length Value Tag length Value... Because these tags are the same (the same field), the values of these fields can be packaged, that is, the coding structure is changed to Tag length Value value
syntax = "proto3";
// message definition
message Example1 {
repeated int32 repeatedInt32Val = 4;
repeated string repeatedStringVal = 5;
}
example1.add_repeatedint32val(2);
example1.add_repeatedint32val(3);
example1.add_repeatedstringval("repeated1");
example1.add_repeatedstringval("repeated2");
22 02 02 03
2A 09 72 65 70 65 61 74 65 64 31 2A 09 72 65 70 65 61 74 65 64 32
The encoding result of repeatedInt32Val field is:
22 | 02 02 03
22, i.e. 00100010 - > wire_ type = 2(Length-delimited), field_ Number = 4 (repeatedint32val field). If the 02 byte length is 2, read two bytes, and then decode the numbers 2 and 3 according to Varints.
repeated string no default packed
- Because int32 adopts varints coding, which omits L in TLV and is actually in TV format, repeated int32 is in tlvv format
- String adopts TLV encoding, so repeated string adopts tlvlv format
Nested fields
Nested fields are not mentioned above because:
According to the meta information (i.e. the. Proto file, when compiled with protoc, the. Proto file will be compiled into a string and saved in the code xxx.pb.cc), you can distinguish whether the field is a nested field. In short, you can't decode information directly from Pb binary data. You must have Proto files. Just at the code level Proto files have existed in some form in the client code generated by protobuf since the time of protoc, and the code can be obtained at any time Meta information expressed in the proto file, such as whether a field is a nested field.
Serializable and Deserialize
The title of the article is to explore the source code, isn't it. Yes, we have to put some code out.
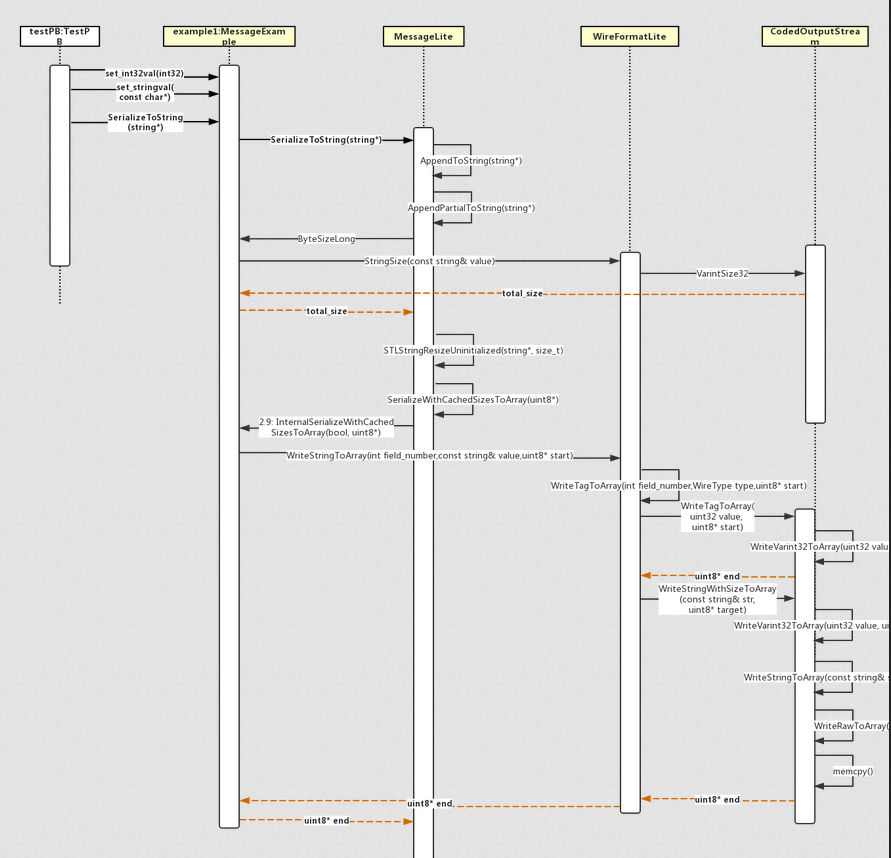
SerializeToString
When a Message calls SerializeToString, it will eventually call the underlying key encoding function WriteVarint32ToArray or WriteVarint64ToArray after layers of calls. The whole process is shown in the following figure:
inline uint8* CodedOutputStream::WriteVarint32ToArray(uint32 value, uint8* target) {
// 0x80 -> 1000 0000
// Greater than 1000 0000 means that at least two bytes are required for Varints encoding
// If value < 0x80, only one byte is required. The encoding result is the same as the original value, and there is no loop to return directly
// If at least two bytes are required
while (value >= 0x80) {
// If there are subsequent bytes, value | 0x80 sets the highest bit of the last byte of value to 1 and takes the last seven bits
*target = static_cast<uint8>(value | 0x80);
// After processing seven bits, move back to continue processing the next seven bits
value >>= 7;
// Pointer plus one, (array moves back one bit)
++target;
}
// Jumping out of the loop indicates that there are no subsequent bytes, but there is still the last byte
// Put the last byte into the array
*target = static_cast<uint8>(value);
// The end address points to the end of the last element of the array
return target + 1;
}
// Varint64 the same
inline uint8* CodedOutputStream::WriteVarint64ToArray(uint64 value,
uint8* target) {
while (value >= 0x80) {
*target = static_cast<uint8>(value | 0x80);
value >>= 7;
++target;
}
*target = static_cast<uint8>(value);
return target + 1;
}
On the coding of fixed family
inline uint8* WireFormatLite::WriteFixed32ToArray(int field_number,
uint32 value, uint8* target) {
// WriteTagToArray: Tag is still a Varint code, which is consistent with the Varint type in the previous section
// Writefixed32nodagtoarray: fixed write four bytes
target = WriteTagToArray(field_number, WIRETYPE_FIXED32, target);
return WriteFixed32NoTagToArray(value, target);
}
inline uint8* WireFormatLite::WriteSFixed32NoTagToArray(int32 value,
uint8* target) {
return io::CodedOutputStream::WriteLittleEndian32ToArray(
static_cast<uint32>(value), target);
}
inline uint8* CodedOutputStream::WriteLittleEndian32ToArray(uint32 value,
uint8* target) {
#if defined(PROTOBUF_LITTLE_ENDIAN)
memcpy(target, &value, sizeof(value));
#else
target[0] = static_cast<uint8>(value);
target[1] = static_cast<uint8>(value >> 8);
target[2] = static_cast<uint8>(value >> 16);
target[3] = static_cast<uint8>(value >> 24);
#endif
return target + sizeof(value);
}
Will this be fast? Don't look at the while above and think others are slow.
Length delimited field serialization
Because its encoding structure is Tag - Length - Value, the complete serialization of its fields will be a little more process:
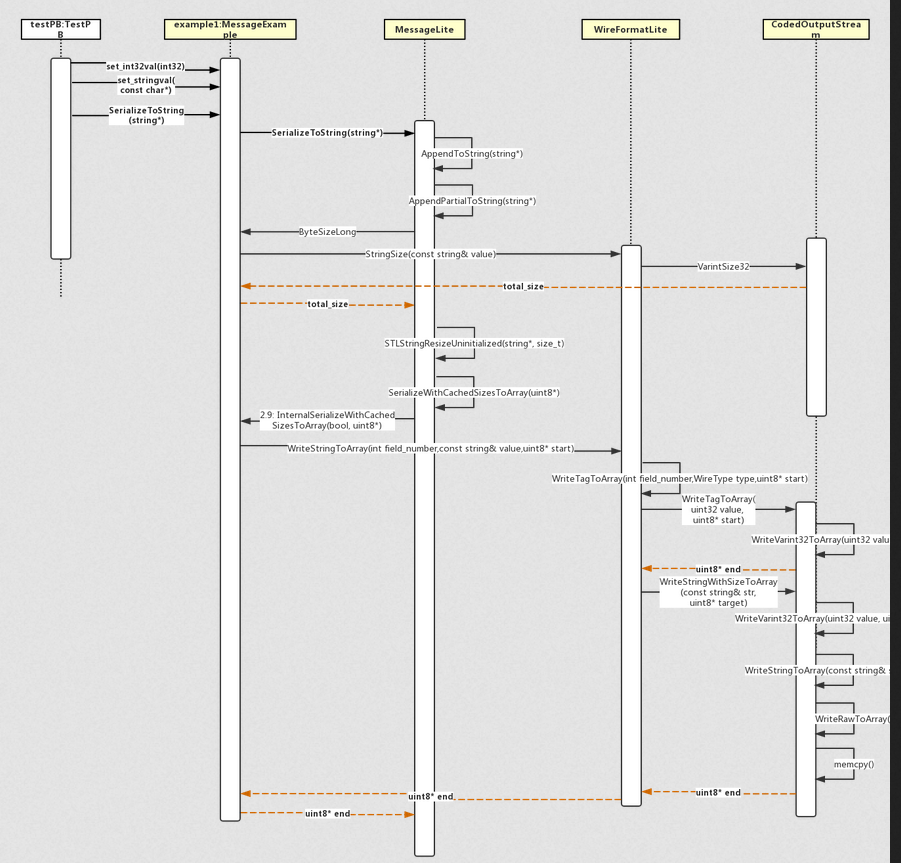
Several key functions of its serialization implementation are:
ByteSizeLong: Calculate the space required for object serialization and open up a corresponding size of space in memory WriteTagToArray: take Tag The value is written to the previously opened memory WriteStringWithSizeToArray: take Length + Value The value is written to the previously opened memory