pyspark learning -- 2. pyspark's running method attempt and various sample code attempts
Operation method
First, build a small project with pycharm: the environment directory is as follows, and two files in the red box are required: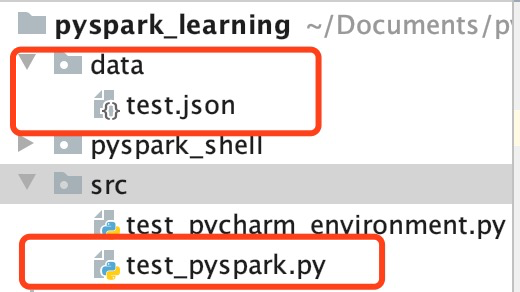
The contents of the file in test.json are as follows:
{'name': 'goddy','age': 23} {'name': 'wcm','age': 31}
The content of test_pyspark.py file is as follows:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession \ .builder \ .appName("goddy-test") \ .getOrCreate() schema = StructType([ StructField("name", StringType()), StructField("age", IntegerType()) ]) # Here, the path is relative, but if you want to put it into the system's pyspark execution, you need to specify the absolute path, otherwise an error will be reported data = spark.read.schema(schema).json('../data/') #data = spark.read.schema(schema).json('/Users/ciecus/Documents/pyspark_learning/data/') data.printSchema() data.show()
Pycharmrun
Click the run key of pycharm directly, and the result is as follows: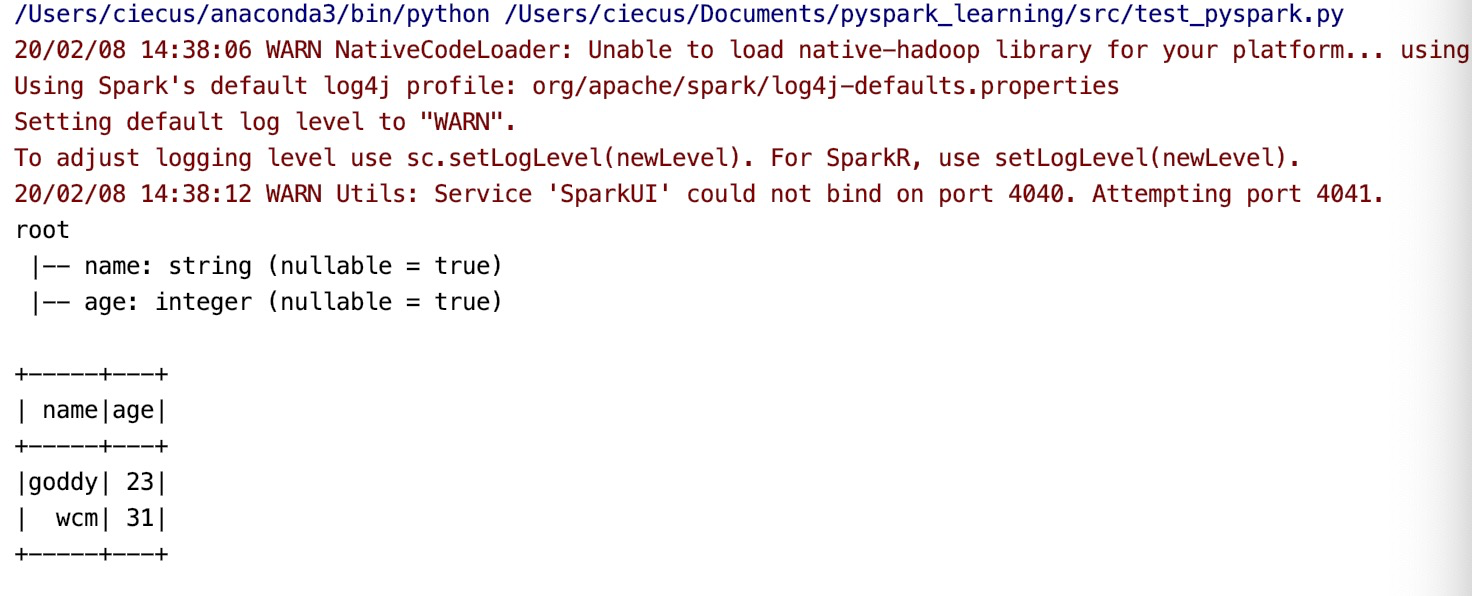
spark operation in the system: spark submit
(1) Index to spark directory
(2)./bin/spark-submit /Users/ciecus/Documents/pyspark_learning/src/test_pyspark.py
Running result: the result is very long, so it needs to use grep to filter the result. There is no result filtering here, only partial results are intercepted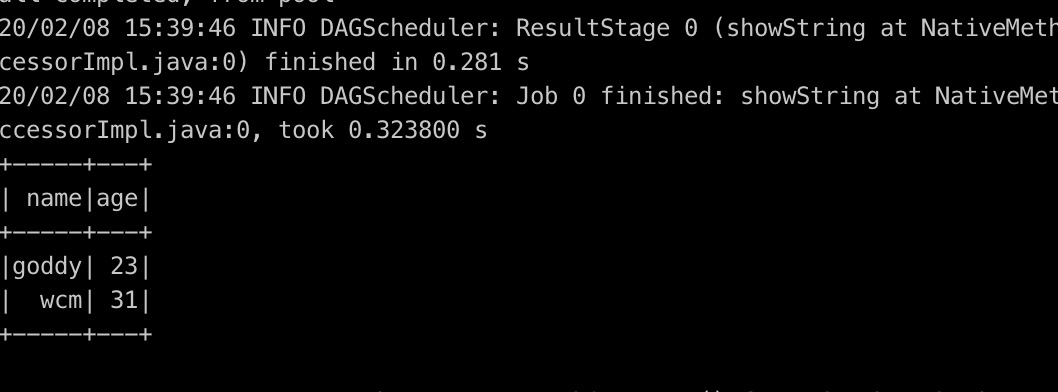
Start spark task run
(1) Index to spark directory
(2) Start master node
./sbin/start-master.sh
At this time, open http://localhost:8080 / with a browser, and we can see the spark management interface, from which we can get the address of the spark master.
(3) Start the slave node, which is the working node
./sbin/start-slave.sh spark://promote.cache-dns.local:7077
The following spark address is the address in the red box above
At this time, there is an additional work node in the management interface.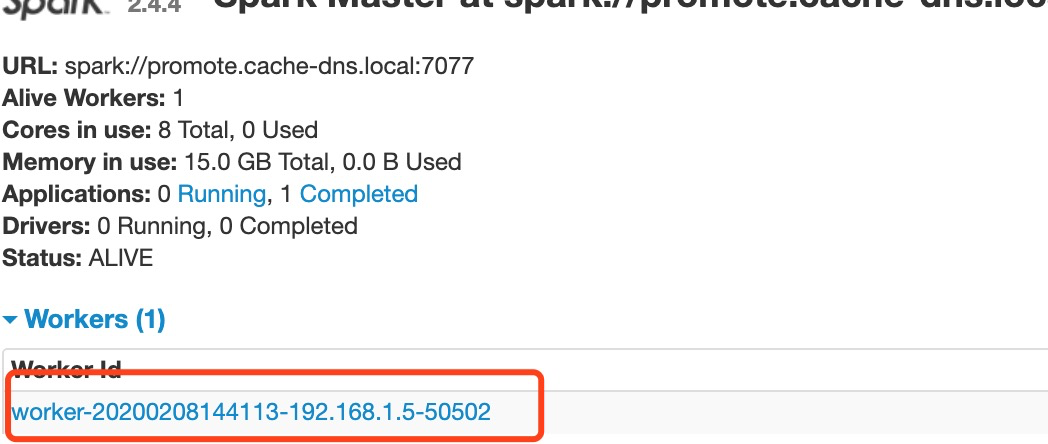
(4) Submit task to master
Absolute path is also needed here
./bin/spark-submit --master spark://promote.cache-dns.local:7077 /Users/ciecus/Documents/pyspark_learning/src/test_pyspark.py
-
Distributed (not yet tried here)
Sample run command
./bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 520M --executor-memory 520M --executor-cores 1 --num-executors 1 /Users/ciecus/Documents/pyspark_learning/src/test_pyspark.py
During execution, you can observe the management interface.
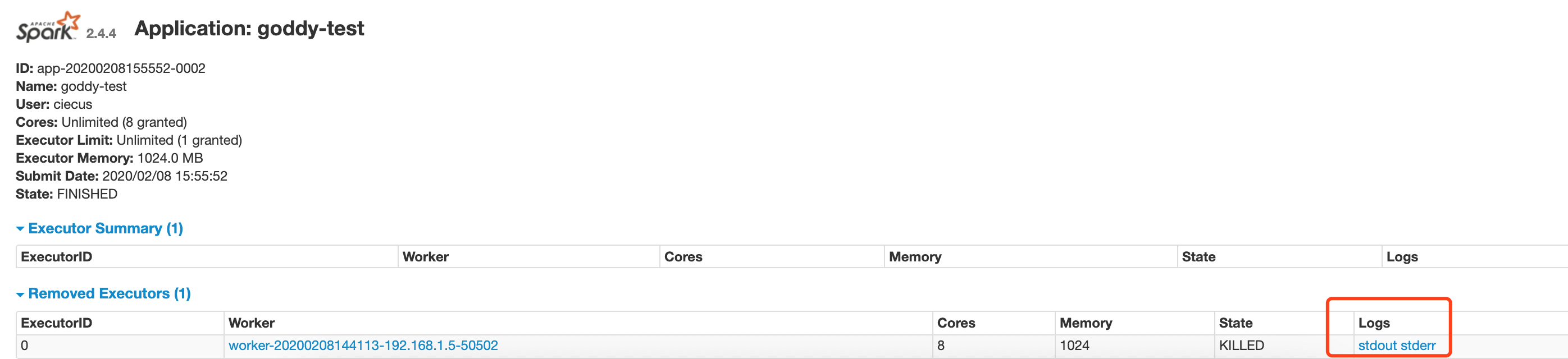
Click the application id to view the result. The log is divided into two parts: stdout (record result) stderr (record error)
- The mission is kill ed here. Find out the reason
Sample code
Streaming text processing streaming context
Stream text word count
wordcount.py
from pyspark import SparkContext from pyspark.streaming import StreamingContext # Create a local StreamingContext with two working thread and batch interval of 1 second sc = SparkContext("local[2]", "NetworkWordCount") ssc = StreamingContext(sc, 5) # Create a DStream that will connect to hostname:port, like localhost:9999 lines = ssc.socketTextStream("localhost", 9999) # Split each line into words words = lines.flatMap(lambda line: line.split(" ")) # Count each word in each batch pairs = words.map(lambda word: (word, 1)) wordCounts = pairs.reduceByKey(lambda x, y: x + y) # Print the first ten elements of each RDD generated in this DStream to the console wordCounts.pprint() ssc.start() # Start the computation ssc.awaitTermination() #
(1) Run the following command at the terminal first:
NC - LK 9999 (no response after pressing, just execute directly next)
(2) Run word "count. Py" in pycharm
Then enter in the command line interface:
a b a d d d d

Then press enter. You can see the output in pycharm s as follows: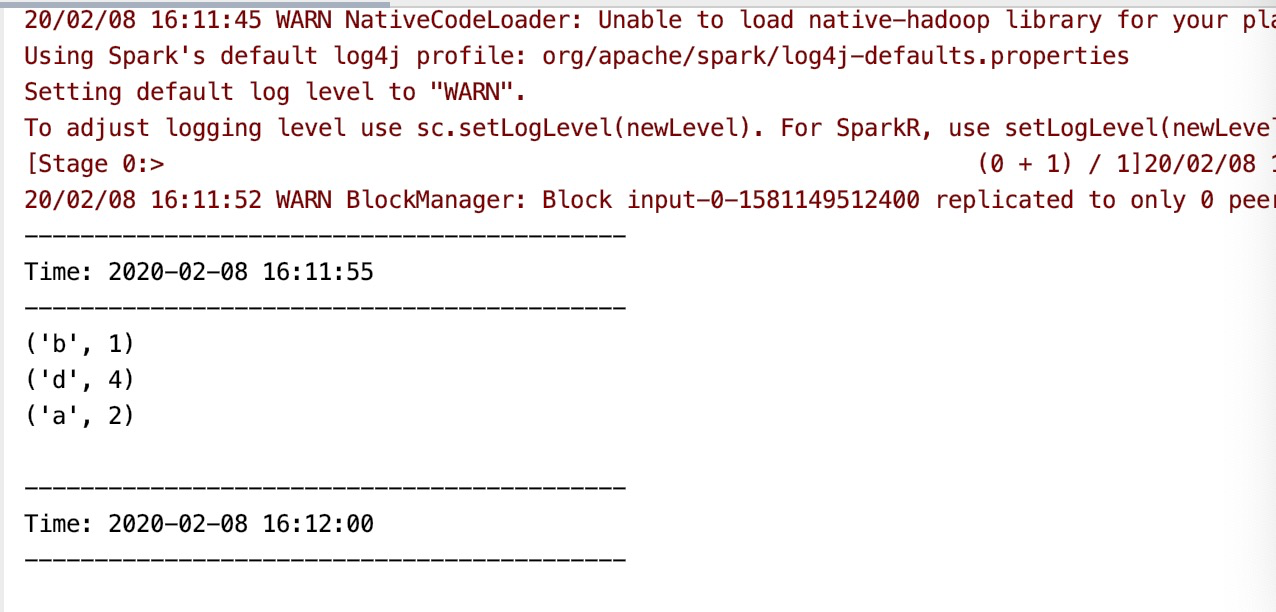
Error reporting summary
(1) Execute:. / bin / spark submit / users / CIECS / documents / pyspark? Learning / SRC / test? Pyspark.py
Error: py4j.protocol.Py4JJavaError: An error occurred while calling o31.json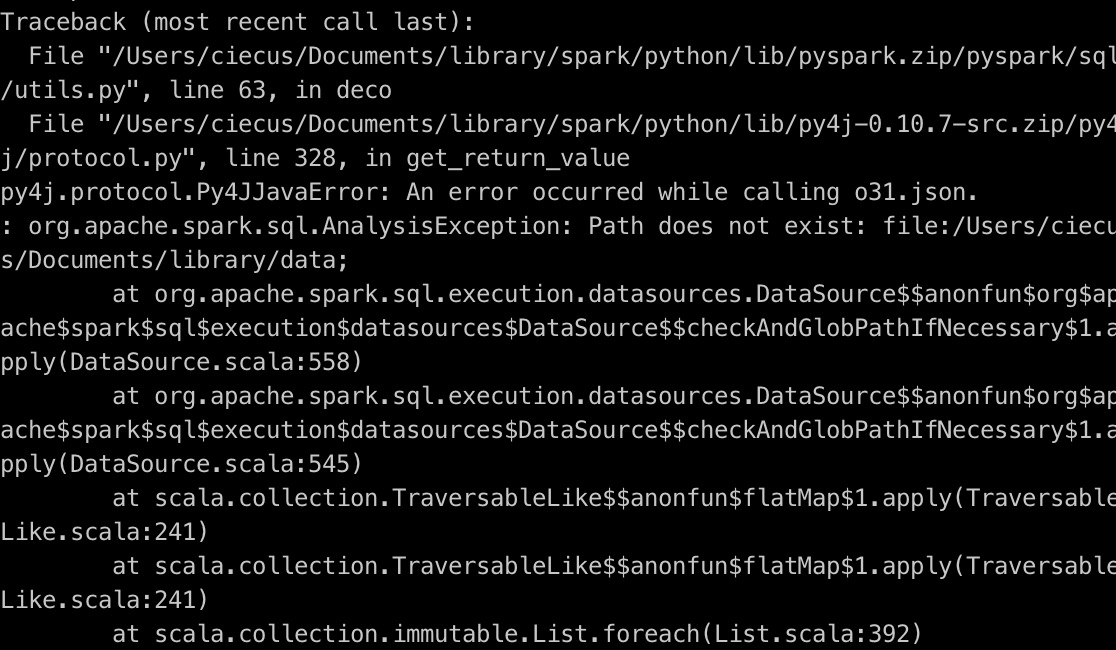
Error cause analysis: the file path in the code is a relative path. If running on the command line, the file path must be an absolute path.
(2) After starting the spark task, the task is kill ed
Reference link:
- Using pyspark & the use of spark thrift server
-
Install spark on Mac, and configure pycharm pyspark full tutorial
[Note: I haven't done all the operations of the pycharm environment configuration here, but it still works normally, so I don't think I need to configure the pycharm environment]

