Python 3 Advanced | implementation of multithreading and multi process
Process and thread concepts
Click here to learn the following while watching the video explanation
During the interview, I am often asked about the difference between process and thread.
Simply put: a process is a running program.
The python program we write (or other applications such as paintbrush, qq, etc.) is called a process when it runs
Open the task manager under windows, which displays the processes running on the current system.
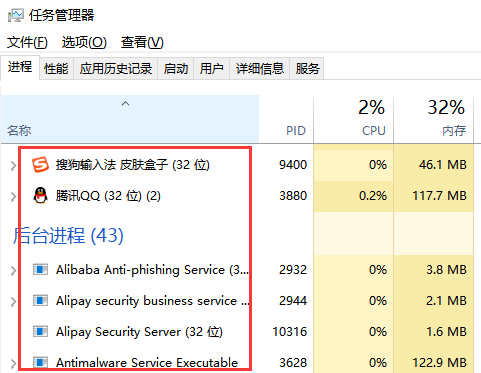
We can see that there are many processes running in our system, such as qq, Sogou input method, etc.
When these programs are not running, their program code files are stored on disk, that is, those with extensions exe file.
Double click on them and these The exe file is loaded into memory by the os and runs as a process
Each process in the system contains at least one * * thread * *.
Threads are created by the operating system. Each thread corresponds to a data structure for code execution, which saves important state information in the process of code execution.
Without threads, the operating system cannot manage and maintain the status information of code operation.
Therefore, the operating system will not execute our code until the thread is created.
Although there is no code to create a thread in the python program we wrote earlier, in fact, when the Python interpreter program runs (becomes a process), the OS automatically creates a thread, usually called the main thread, and executes code instructions in the main thread.
When the interpreter executes our python program code. Our code is interpreted and executed in this main thread.
For example, after the following program runs, there is only one thread, the main thread. In the main thread, the code is executed in sequence until the end, and the main thread exits. At the same time, the process is over.
fee = input('Please enter lunch fee:')
members = input('Please enter the name of the dinner party, with English comma,separate:')
# Put people into a list
memberlist = members.split(',')
# Number of people received
headcount = len(memberlist)
# Calculate per capita cost
avgfee = int (fee) / headcount
print(avgfee)
Click here to learn the following while watching the video explanation
On modern computers, the CPU is multi-core, and each core can execute code.
To run the code in the program, the operating system will allocate a CPU core to execute the code.
Sometimes, we hope that more CPU cores can execute some code in our program at the same time.
Suppose that there is a function called compress in our program to perform the task of compressing files.
Now there are four large files that need to be compressed.
If a CPU core executes this function (a single threaded program) and it takes 10 seconds to compress a file, it takes 40 seconds to compress four files.
If we can make four CPU cores} execute the compression function at the same time, it theoretically takes only 10 seconds.
Sometimes, we have a batch of tasks to execute, and the execution time of these tasks is mainly spent on {non CPU computing}.
For example, we need to go to 51job.com to get the job information related to python development.
We need to grab the contents of hundreds of web pages and execute the code of these tasks of capturing information. The time is mainly spent waiting for the website to return information. The CPU is idle when waiting for the information to return.
If we use a loop to get the information of 100 Web pages in a thread as before, as follows
# Grab the position information of the web page
def grabOnePage(url):
print('The code initiates a request and grabs the web page information. The specific code is omitted')
for pageIdx in range(1,101):
url = f'https://search.51job.com/list/020000,000000,0000,00,9,99,python,2,{pageIdx}.html'
grabOnePage(url)
There will be a long time spent waiting for the server to return information.
If we can use 100 threads to run the code to obtain web page information at the same time, in theory, we can reduce the execution time 100 times.
To enable multiple CPU cores to execute tasks at the same time, our program must} create multiple threads and let the CPU execute the code corresponding to multiple threads.
Create a new thread in Python code
Click here to learn the following while watching the video explanation
So how does our program code generate new threads?
The application must request the operating system to allocate a new thread through the} system call provided by the operating system.
Python 3 encapsulates the function of creating threads by system calls in the standard library threading.
Let's look at the following code
print('The main thread executes code')
# Import the Thread class from the threading library
from threading import Thread
from time import sleep
# Define a function as the entry function executed by the new thread
def threadFunc(arg1,arg2):
print('Child thread start')
print(f'Thread function parameters are:{arg1}, {arg2}')
sleep(5)
print('Child thread end')
# Create an instance object of the Thread class
thread = Thread(
# The target parameter specifies the function to be executed by the new thread
# Note that the function object specified here can only write one name and cannot be followed by parentheses,
# If you add parentheses, it is called and executed directly in the current thread, rather than in the new thread
target=threadFunc,
# If the new thread function needs parameters, fill in the parameters in args
# Note that the parameter is a tuple. If there is only one parameter, it should be followed by a comma, such as args = ('parameter 1')
args=('Parameter 1', 'Parameter 2')
)
# Execute the start method and a new thread will be created,
# And the new thread will execute the code in the entry function.
# At this time, the process has two threads.
thread.start()
# The code of the main thread executes the join method of the child thread object,
# It will wait for the child thread to end before continuing to execute the following code
thread.join()
print('Main thread end')
When running the program, the interpreter executes the following code
thread = Thread(target=threadFunc,
args=('Parameter 1', 'Parameter 2')
)
A Thread instance object is created, where the Thread class has two initialization parameters
The target parameter specifies the entry function of the new thread. After the new thread is created, the code in the entry function will be executed,
args specifies the parameters passed to the entry function threadFunc. Thread entry function parameters must be placed in a tuple, and the elements in it are used as the parameters of the entry function in turn.
Note that the above code only creates a Thread instance object, but at this time, the new Thread has not been created.
To create a Thread, you must call the start method of the Thread instance object. That is, when the following code is executed
thread.start()
The new thread is created successfully and starts to execute the code in the entry function threadFunc.
Sometimes, a thread needs to wait for other threads to end. For example, it needs to be processed according to the results of other threads.
In this case, you can use the {join} method of the Thread object
thread.join()
If the code of A Thread A calls the {join} method of the Thread object of the corresponding Thread B, Thread A will stop executing the code and wait for Thread B to finish. After Thread B ends, Thread A continues to execute subsequent code.
Therefore, when the main thread executes the above code, it pauses here. It will not continue to execute the subsequent code until the new thread finishes executing and exits.
As for the purpose of multi-threaded join, Bai Yue and Heiyu have such a metaphor in communicating with a VIP practical class, as shown in the figure below
join is usually used by the main thread to assign tasks to several sub threads. After the sub threads finish their work, they need to reprocess their task processing results.
It's like a leader assigns tasks to several employees. After several employees finish their work, he needs to collect the reports submitted by them for follow-up processing.
In this case, the main thread must be completed by the child thread before subsequent operations can be performed. Therefore, the join returns only after the thread corresponding to the parameter is completed.
Many students write the following when creating thread objects
thread = Thread(target=threadFunc('Parameter 1', 'Parameter 2'))
Why is that wrong? What's the difference between it and the following writing?
thread = Thread(target=threadFunc,
args=('Parameter 1', 'Parameter 2'))
Click here to watch the video exchange and explanation between Bai Yue, Heiyu and VIP students
Access control of shared data
Click here to learn the following while watching the video explanation
In multithreading development, we often encounter such a situation: the code in multiple threads needs to access the same public data object.
The public data object can be any type, such as a list, dictionary, or custom class object.
Sometimes, programs need to prevent thread code from operating public data objects at the same time. Otherwise, data access may conflict with each other.
Look at an example.
We use a simple program to simulate a banking system. Users can deposit money in their own account.
The corresponding codes are as follows:
from threading import Thread
from time import sleep
bank = {
'byhy' : 0
}
# Define a function as the entry function executed by the new thread
def deposit(theadidx,amount):
balance = bank['byhy']
# Some tasks took 0.1 seconds
sleep(0.1)
bank['byhy'] = balance + amount
print(f'Child thread {theadidx} end')
theadlist = []
for idx in range(10):
thread = Thread(target = deposit,
args = (idx,1)
)
thread.start()
# Store all thread objects in threadlist
theadlist.append(thread)
for thread in theadlist:
thread.join()
print('Main thread end')
print(f'Finally, our account balance is {bank["byhy"]}')
The above code is executed together
At the beginning, the balance of the account was 0. Then we started 10 threads. Each thread used the deposit function to deposit 1 yuan into the account byhy.
It can be expected that after the program is executed, the balance of the account should be 10.
However, after running the program, we found the following results
Child thread 0 ended End of sub thread 3 End of child thread 2 End of sub thread 4 End of child thread 1 End of child thread 7 End of sub thread 5 End of child thread 9 End of sub thread 6 End of child thread 8 Main thread end Finally, our account balance is 1
Why 1? Instead of 10?
If there is only one thread in our program code, as shown below
from time import sleep
bank = {
'byhy' : 0
}
# Define a function as the entry function executed by the new thread
def deposit(theadidx,amount):
balance = bank['byhy']
# Some tasks took 0.1 seconds
sleep(0.1)
bank['byhy'] = balance + amount
for idx in range(10):
deposit (idx,1)
print(f'Finally, our account balance is {bank["byhy"]}')
The code is {executed serially. There is no problem that multiple threads access the bank object at the same time, and everything is normal.
Now, there are multiple threads in our program code, and deposit will be called in these threads. It is possible to operate the bank object at the same time, and it is possible that one thread may overwrite the result of another thread.
At this time, you can use the Lock object Lock in the threading library to protect it.
We modify the multithreading code as follows:
from threading import Thread,Lock
from time import sleep
bank = {
'byhy' : 0
}
bankLock = Lock()
# Define a function as the entry function executed by the new thread
def deposit(theadidx,amount):
# Apply for a lock before operating shared data
bankLock.acquire()
balance = bank['byhy']
# Some tasks took 0.1 seconds
sleep(0.1)
bank['byhy'] = balance + amount
print(f'Child thread {theadidx} end')
# Apply to release the lock after sharing the data
bankLock.release()
theadlist = []
for idx in range(10):
thread = Thread(target = deposit,
args = (idx,1)
)
thread.start()
# Store all thread objects in threadlist
theadlist.append(thread)
for thread in theadlist:
thread.join()
print('Main thread end')
print(f'Finally, our account balance is {bank["byhy"]}')
Execute it, and the results are as follows
Child thread 0 ended End of child thread 1 End of child thread 2 End of sub thread 3 End of sub thread 4 End of sub thread 5 End of sub thread 6 End of child thread 7 End of child thread 8 End of child thread 9 Main thread end Finally, our account balance is 10
That's right.
The acquire method of the Lock object is to request a Lock.
Before operating the shared data object, each thread should apply for obtaining the operation right, that is, calling the acquire method of the lock object corresponding to the shared data object.
If thread A executes the following code and calls the acquire method,
bankLock.acquire()
Other thread B has applied for this lock and has not released it, so the code of thread A waits here for thread B to release the lock and does not execute the following code.
Thread A cannot acquire the lock until thread B executes the release method of the lock and releases the lock, and then the following code can be executed.
If thread B executes the acquire method of the lock at this time, it needs to wait for thread A to execute the release method of the lock object to release the lock. Otherwise, it will also wait and do not execute the following code.
Refer to the explanation in the video for details.
daemon thread
Let's execute the following code
from threading import Thread
from time import sleep
def threadFunc():
sleep(2)
print('Child thread end')
thread = Thread(target=threadFunc)
thread.start()
print('Main thread end')
It can be found that the main thread ends first. It takes 2 seconds for the whole program to exit after the sub thread runs.
Because:
In a Python program, the whole program will end only when all 'non daemon threads' end
The main thread is a non daemon thread, and the child thread started is also a non daemon thread by default.
Therefore, the program will not end until both the main thread and the sub thread end.
We can set the daemon parameter value to True when creating a thread, as follows
from threading import Thread
from time import sleep
def threadFunc():
sleep(2)
print('Child thread end')
thread = Thread(target=threadFunc,
daemon=True # Set the new thread as the daemon thread
)
thread.start()
print('Main thread end')
Running again, you can find that as long as the main thread ends, the whole program ends. Because only the main thread is a non daemon thread.
Multi process
Each thread of the official Python interpreter must obtain something called GIL (global interpreter lock) in order to obtain execution permission.
This leads to the fact that multiple threads of Python can not use multiple CPU cores at the same time.
Therefore, if it is a computing intensive task, it cannot be multi-threaded.
You can run the following code
from threading import Thread
def f():
while True:
b = 53*53
if __name__ == '__main__':
plist = []
# Start 10 threads
for i in range(10):
p = Thread(target=f)
p.start()
plist.append(p)
for p in plist:
p.join()
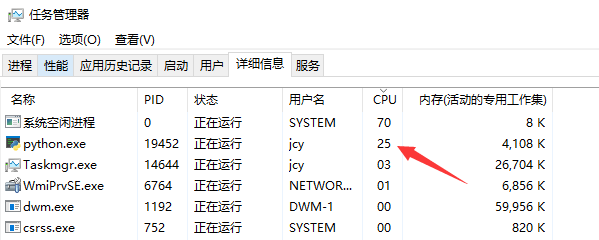
After running, open the task manager. You can find that even if you start 10 threads, you can only occupy the computing power of one CPU core.
As shown in the figure below, my computer has four cores, and this Python process occupies the running capacity of one core, so the figure below shows 25, representing 25%, that is, 1 / 4 of the CPU utilization
If you need to use the computing power of multiple CPU cores of the computer, you can use Python's multi process library, as follows
from multiprocessing import Process
def f():
while True:
b = 53*53
if __name__ == '__main__':
plist = []
for i in range(2):
p = Process(target=f)
p.start()
plist.append(p)
for p in plist:
p.join()
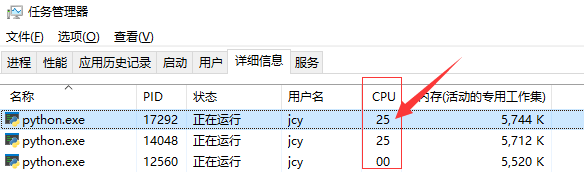
After running, open the task manager, and you can find that there are three Python processes, of which the CPU occupancy of the main process is 0, and the CPUs of the two sub processes each occupy a core computing power.
As shown in the figure below
A closer look at the above code shows that it is very similar to multithreading.
Another question is, how does the main process get the operation results of the child process?
You can use the Manage object in the multi process library, as follows
from multiprocessing import Process,Manager
from time import sleep
def f(taskno,return_dict):
sleep(2)
# Store calculation results in shared objects
return_dict[taskno] = taskno
if __name__ == '__main__':
manager = Manager()
# Create a dictionary like cross process shared object
return_dict = manager.dict()
plist = []
for i in range(10):
p = Process(target=f, args=(i,return_dict))
p.start()
plist.append(p)
for p in plist:
p.join()
print('get result...')
# Fetch the calculation results of other processes from the shared object
for k,v in return_dict.items():
print (k,v)