Please indicate the author and source of Reprint:
https://blog.csdn.net/qq_45627785?spm=1011.2124.3001.5343
Running platform: Windows
Python version: Python 3 x
Foreword
Preparatory knowledge
Actual combat
0. background
1.requests installation
2. Crawl single page target link
3. Crawl multi page target links
4. Overall code
summary
0 Preface
I just reviewed the knowledge of Python and wanted to do something. In fact, I had the idea of being a reptile before, but what to climb is also a problem. See that there are many pictures of climbing girls on the Internet, then I'll climb my brother's picture and lie down (laugh). As the saying goes, looking at your brother can improve your beauty and prolong your life. So, let's climb and lie down today!
1 preparatory knowledge
In order to quickly write handwritten code, we need to first understand the third-party libraries we need for this crawler Code: beautiful soup and requests.
Installation: open CMD directly by win + R # and then enter PIP install beautiful soup4 at the command line prompt. If you encounter various problems, please solve them by Baidu keyword. Installing requests also opens CMD, and then enter pip install requests at the command line prompt.
Specific usage of Library: https://pypi.org/ If you want to see Chinese tutorials, you can directly query the usage of the corresponding library in the browser. There will also be many tutorials.
2 actual combat
2.1 background
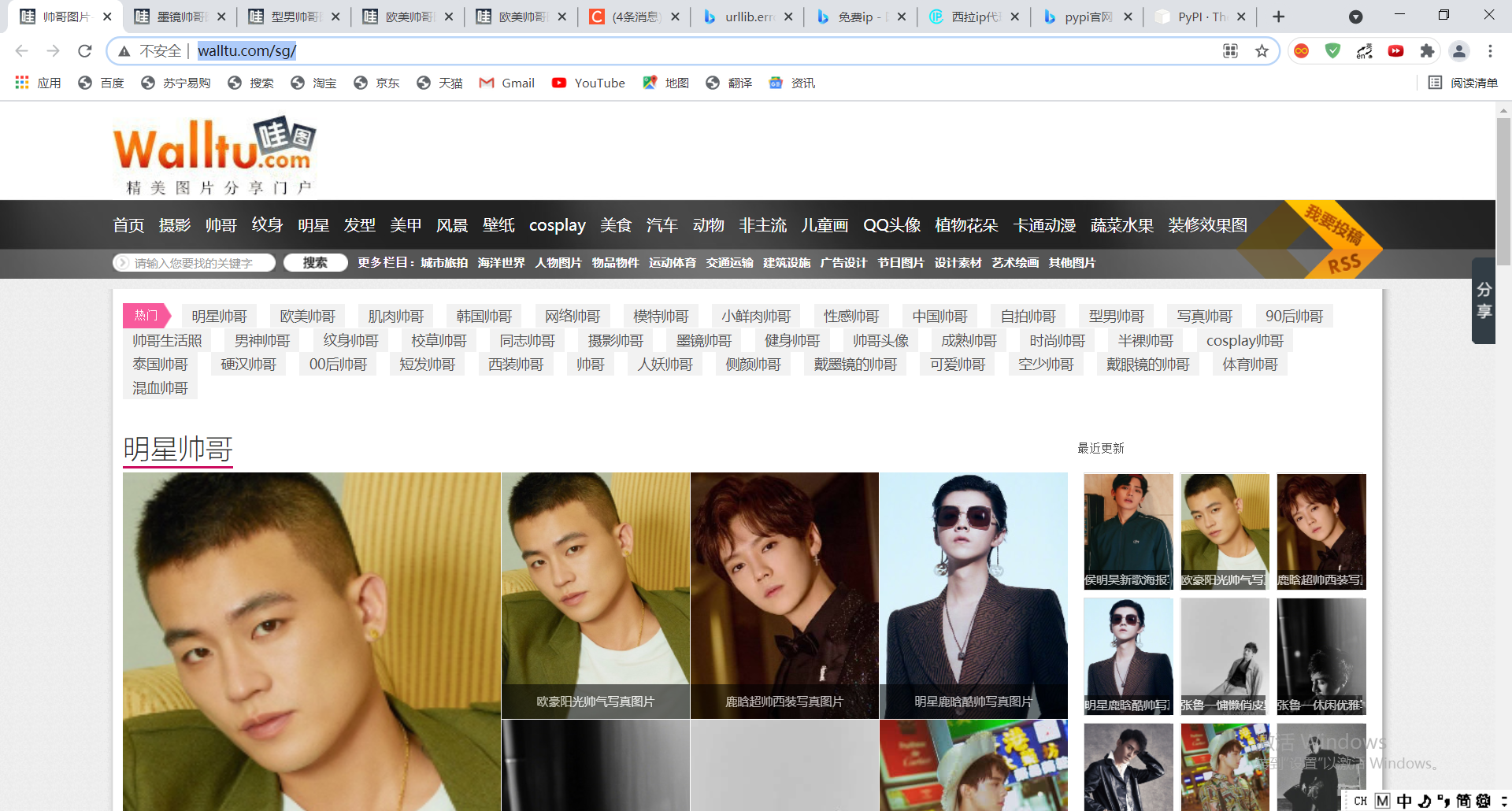
Climb to take the pictures of handsome guys on the "wow map" website!
URL : http://www.walltu.com/sg/
Take a look at the website first:
2.2 crawling single page target link
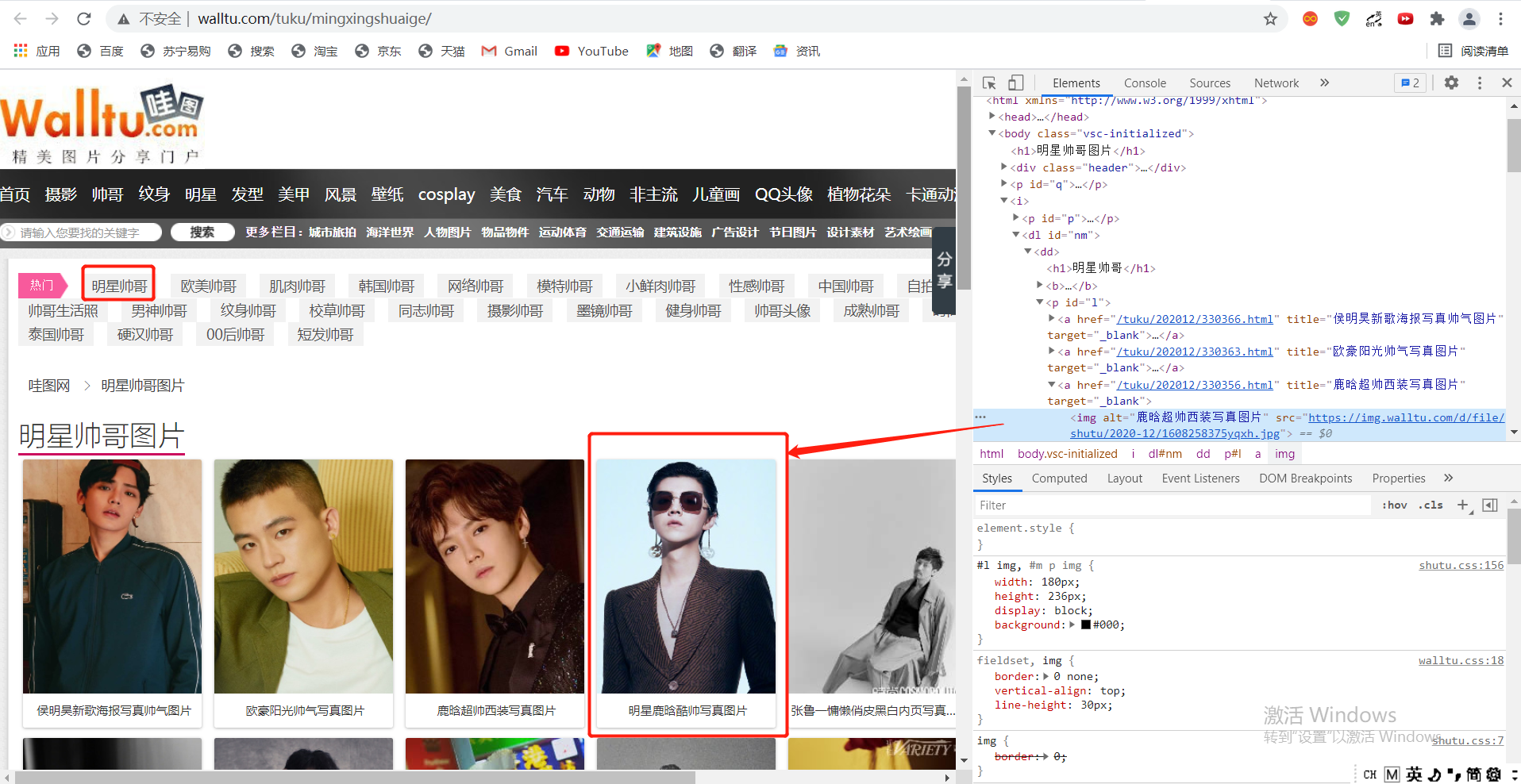
First of all, let's climb the website of the "star handsome man" page and open its source code. We can see the SRC attribute in the < img > tag of the source code of the picture. We have successfully found the website of the picture in chapters. Let's take a look at the code.
code:
#Import required libraries
from bs4 import BeautifulSoup
import requests
import os
from urllib.request import urlretrieve
import time
n = 0
list_url = []
url = 'http://www.walltu.com/tuku/mingxingshuaige/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"
}
req = requests.get(url=url, headers=headers)
req.encoding = 'utf-8'
html = req.text
bf = BeautifulSoup(html, 'lxml')
img_url = bf.find_all("img")
#Get picture link
for each in img_url:
list_url.append(each.get('src'))
#create a file
if not os.path.exists('./imgs'):
os.mkdir('./imgs')
#Convert picture links into pictures with a loop
while n < (len(list_url)):
img_url = list_url[n]
urlretrieve(img_url, './imgs/%s.jpg' % n)
n = n + 1
print("Download complete")Then, let's take a look at the running effect
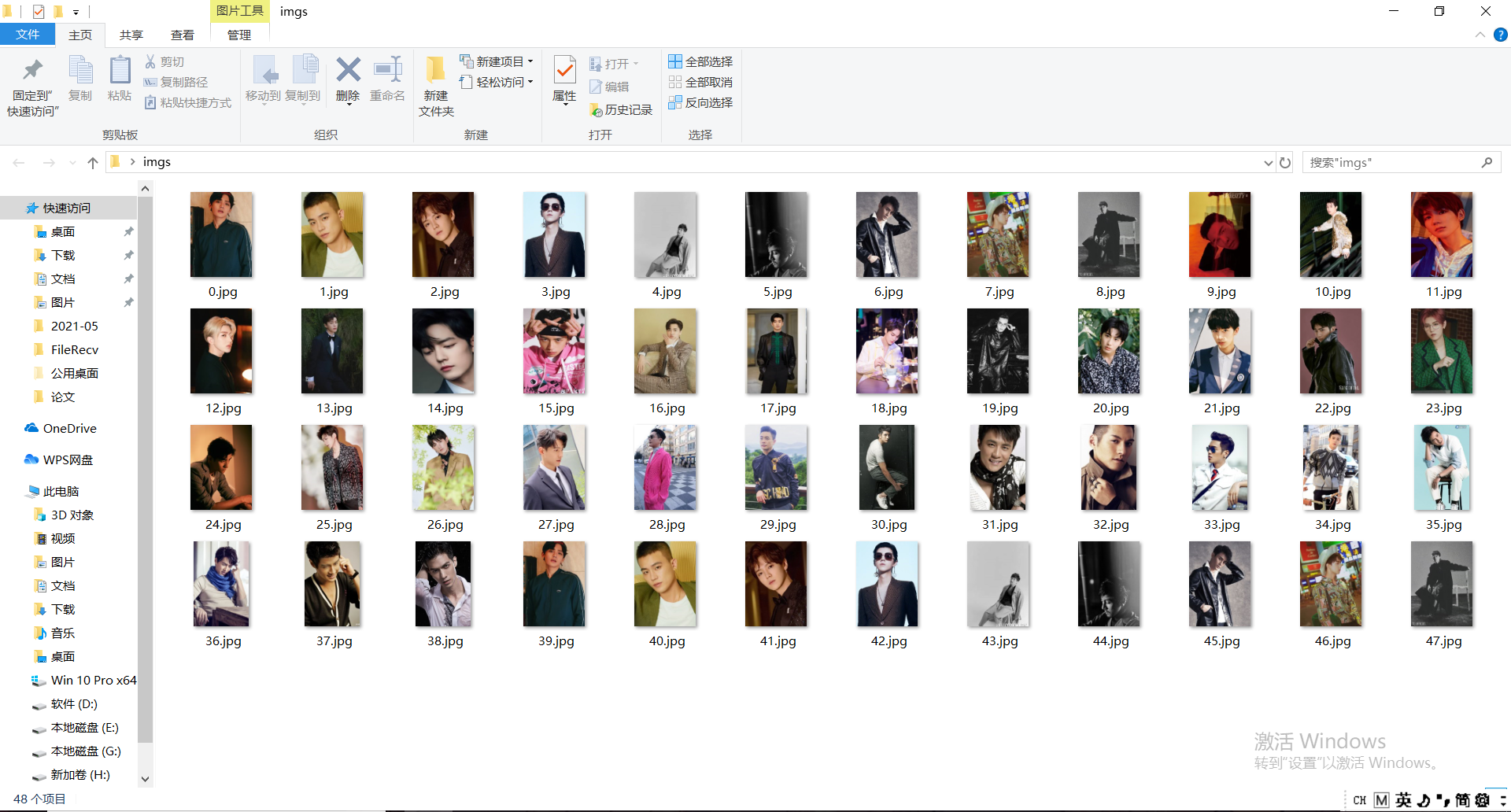 ok, at this time, we can see that the star handsome figure has climbed down! (chicken jelly)
ok, at this time, we can see that the star handsome figure has climbed down! (chicken jelly)
There is a problem with the main body of the code, that is, Ctrip has a 'Desktop' parameter when saving the file, which leads to only one file downloaded on the Desktop and not saved in the form of pictures. I thought there was a serious problem with my code. Thanks to the big guy Zax, I offered my knee to the big guy again. So let's take a look at the code of boss Zax about climbing the picture of the star handsome man on this page
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import os
url = "http://www.walltu.com/tuku/mingxingshuaige/"
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'lxml')
# Find the picture body by id
p = soup.find("p", {'id': 'l'})
imgs = p.find_all("img")
#create a file
if not os.path.exists('./imgs'):
os.mkdir('./imgs')
#Get src with for loop
for i in range(len(imgs)):
src = imgs[i]['src']
#Directly use get() Content gets the picture content and writes it to the file
try:
with open('./imgs/%s.jpg' % i, 'wb') as f:
f.write(requests.get(src).content)
except Exception as e:
continue
Relatively speaking, it is indeed very concise
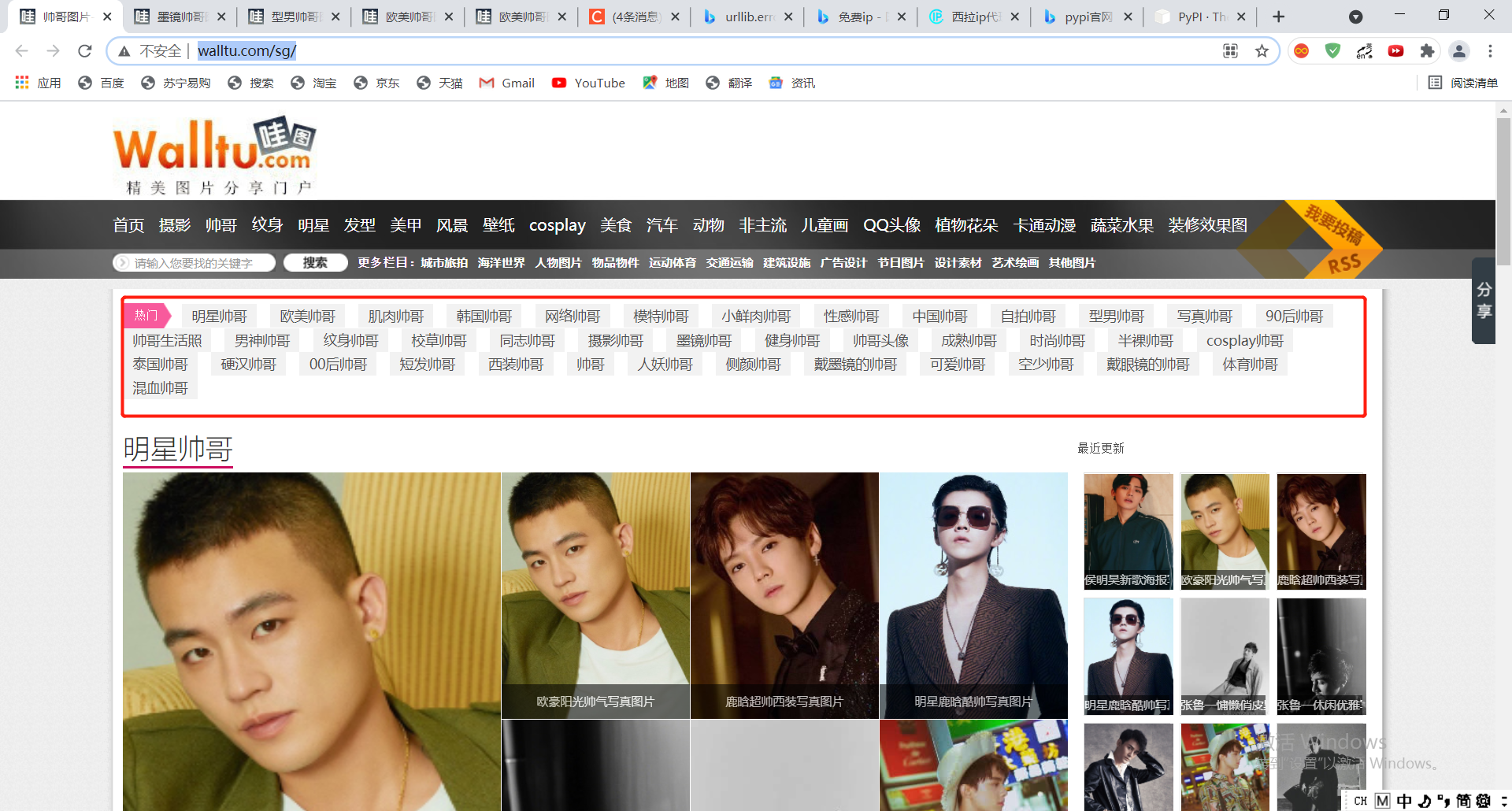
2.3 crawling multi page picture links
Although it's successful to climb one page, can the handsome guy on this page meet us (laugh). Our goal is the handsome guy on the front page of all labels (see the figure below)
 Let's first look at the source code:
Let's first look at the source code:
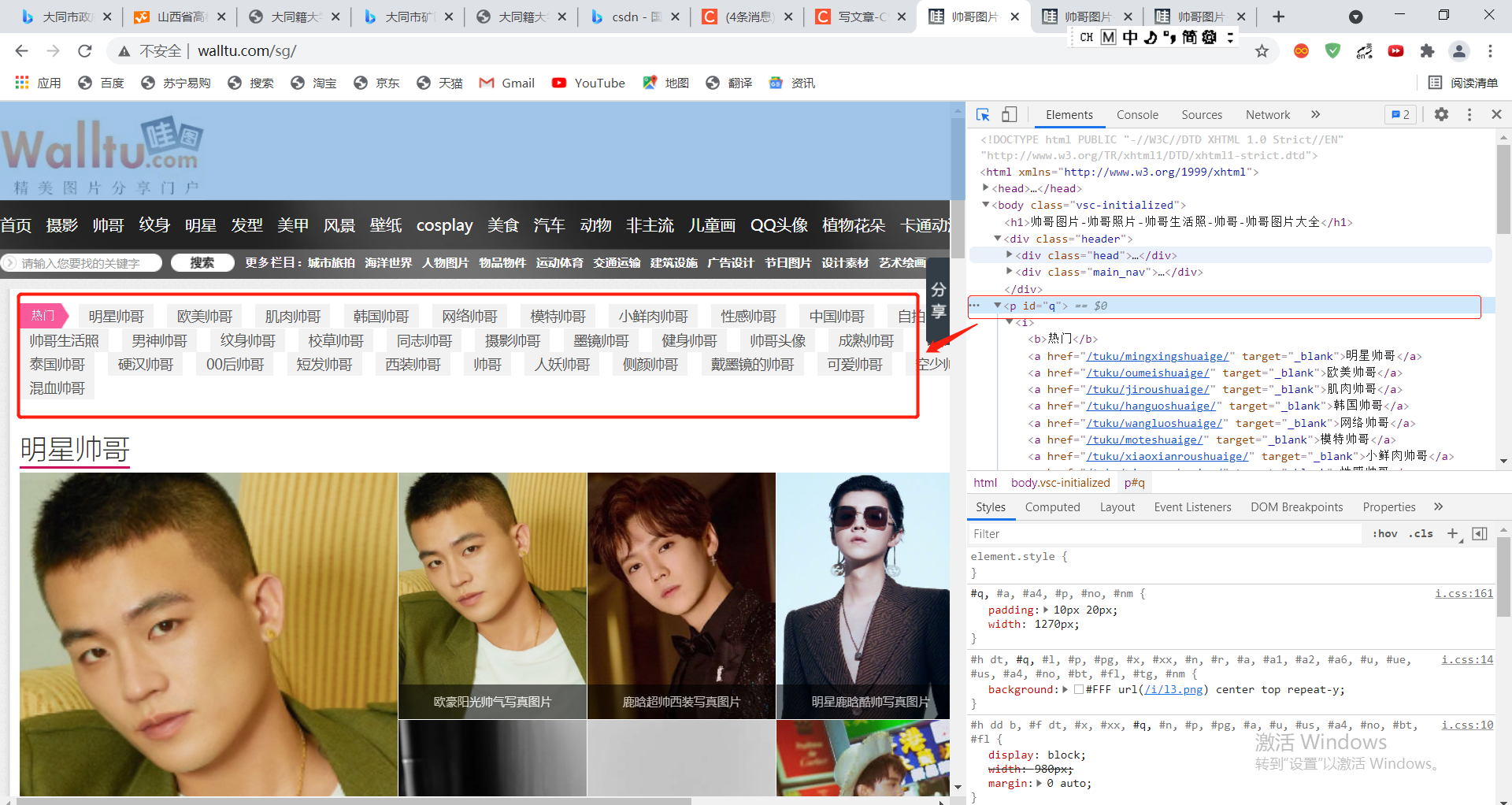 Through the code, we can see that < p id = "Q" > is the main body of the above link, so we have the idea of writing the code:
Through the code, we can see that < p id = "Q" > is the main body of the above link, so we have the idea of writing the code:
#Import required libraries
from bs4 import BeautifulSoup
import requests
import os
from urllib.request import urlretrieve
n = 0
s = 0
list_url = []
url_1 = []
url = 'http://www.walltu.com/sg/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"
}
req = requests.get(url=url, headers=headers)
req.encoding = 'utf-8'
html = req.text
soup = BeautifulSoup(html, 'lxml')
#Get the url of the tag body through id
p = soup.find("p", {'id': 'q'})
content = p.find_all('a')
for i in content:
url_1.append(i.get('href'))
#Get the url of each page in the label above
while s < (len(url_1)):
url = url_1[s]
s = s + 1
real_url = 'http://www.walltu.com' + url
req = requests.get(url=real_url, headers=headers)
req.encoding = 'utf-8'
html = req.text
soup = BeautifulSoup(html, 'lxml')
img_url = soup.find_all("img")
for each in img_url:
list_url.append(each.get('src'))
#create a file
if not os.path.exists('./imgs'):
os.mkdir('./imgs')
#Get and download each picture
while n < (len(list_url)):
img_url = list_url[n]
try:
urlretrieve(img_url, './imgs/%s.jpg' % n)
except Exception as e:
print(img_url)
n = n + 1
print("Download complete")
ok, let's see the operation effect
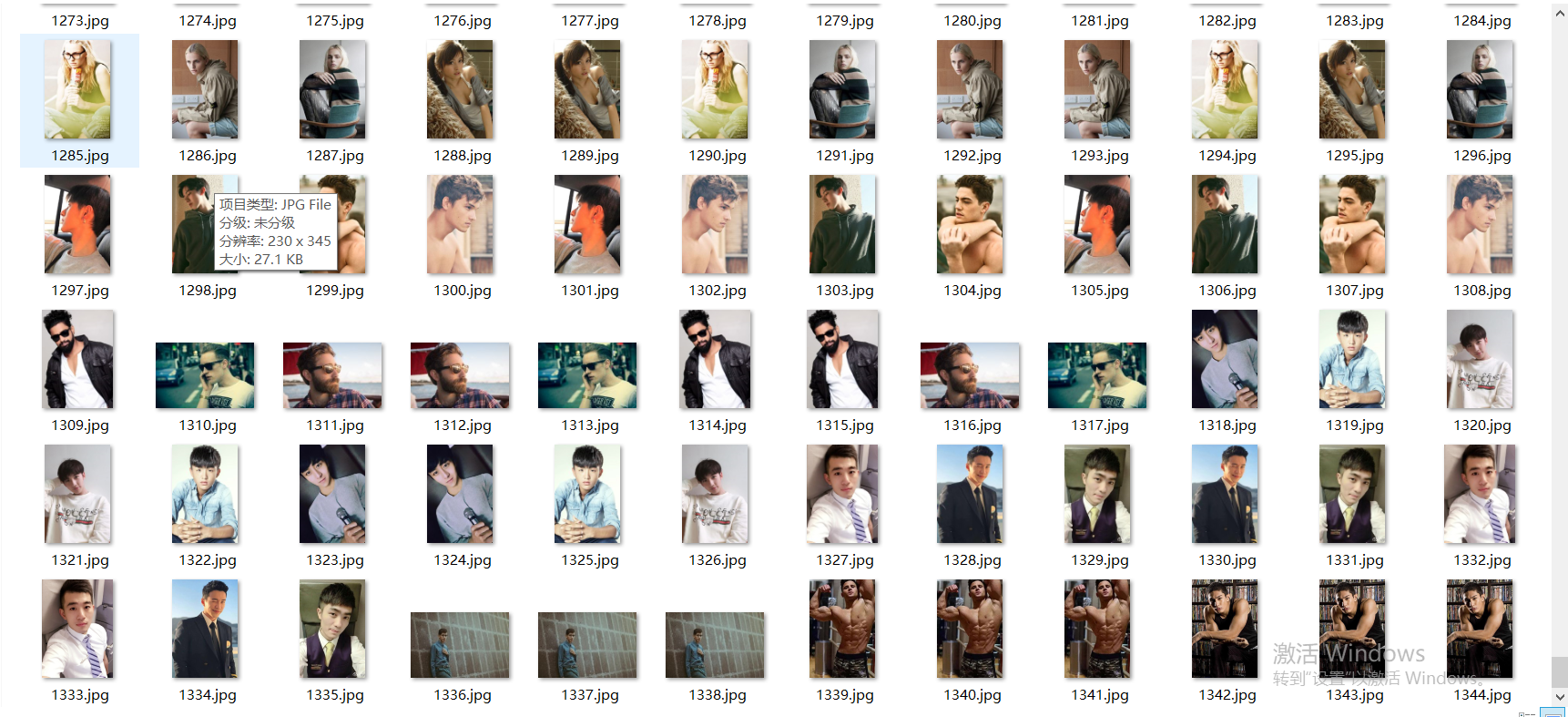
Oh, within 5 minutes, 1345 all kinds of handsome men are in place, and the effect is full!
summary
The overall structure of this website is relatively simple, and it does not involve anti crawling, proxy ip or sleep time In the process of writing, it is not recommended to use the loop. The loop involves the problem of coverage, and the loop is easy to halo itself. The value of the index also needs attention. Why don't you get it directly Content is relatively simple. In general, I'm still very happy to climb to my brothers. Life is lonely as snow. Only handsome men (picture) will always follow me!!!