Hello, everyone, first of all, this is a technical article, but also a not technical article. Today, I share the following results after I got more than 3,500 micro-credit household nicknames and age groups named in English by Weixin applet.
Let's get it
1. Basic information acquisition
1. Visit the basic user communication interface with English names, get the NickName, Count and ResponseData of English named users, and save the name of the Weixin into the file.
1# Get all user numbers and related information
2def get_json():
3 # Access Entrance
4 search_url = 'English Naming User Interface. Welcome to use English Naming to generate an English Name that is most suitable for you.'
5 # Send an http request to get the request page
6 search_response = requests.get(search_url)
7 # Setting Code
8 search_response.encoding = 'UTF-8'
9 # Converting pages to json code format
10 search_json = search_response.json()
11 # Getting the data we need is a list format
12 our_data = search_json['ResponseData']
13 list_len = len(our_data)
14 print('The total number of users is:' + str(list_len))
15 user_visit_numbers = 0
16 data_research = 0
17 NickName = []
18 for x in our_data:
19 user_numbers = x['Count'] + user_visit_numbers
20 if x['NickName'] == '':
21 data_research += 1
22 NickName.append(x['NickName'])
23 print("Wechat Name Acquisition Failure Quantity:"+str(data_research))
24 print(NickName)
25 name = ['Wechat Name']
26 file_test = pd.DataFrame(columns=name, data=NickName)
27 file_test.to_csv(r'I:/data.csv', encoding='utf-8',index=False)
28 print('Total visits:' + str(user_visit_numbers))
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
Operation results:
1 Total number of users: 3549 2 Wechat Name Acquisition Failure Quantity:0 3 Total visits: 4573
2. Read all micro-message names and classify data
(1) Read the Wechat Name
1# Read the file and take out the name of the tweet
2def get_name():
3 NickName = []
4 with open('I:/data.csv','r',encoding='utf8') as file :
5 i = 0
6 for line in file:
7 if i == 0: # Remove the header
8 i = 1
9 continue
10 line = line.strip() # Remove line breaks
11 NickName.append(line)
12 return NickName
(2) Data are divided into six categories
| Chinese name | Variable name | data type |
|---|---|---|
| All Chinese nicknames | ch_name | list |
| All English nicknames | en_name | list |
| Mixed Chinese and Digital Nicknames | ch_di_name | list |
| Contains pictorial facial nicknames | img_name | list |
| Other nicknames | other_name | list |
1# ch : Chinese 2ch_name_number = 0 3ch_name = [] 4# en : English 5en_name_number = 0 6en_name = [] 7# di : digtal 8di_name_number = 0 9di_name = [] 10# img : image 11img_name_number = 0 12img_name = [] 13# ch_di : Chinese and digtal 14ch_di_name = [] 15# other : other 16oth_name_number = 0 17oth_name = []
(3) Data classification and judgment
1# Chinese judgment of nicknames
2def is_all_ch(keyword):
3 for c in keyword:
4 # Contains common Chinese characters
5 if not ('\u4e00' <= c <= '\u9fa5'):
6 return False
7 return True
8
9# Judgment of nicknames in English
10def is_all_en(keyword):
11 # Not all spaces or first spaces
12 if all(ord(c) == 32 for c in keyword) or keyword[0] == ' ':
13 return False
14 # Allow space to coexist with English (e.g. Xist A)
15 if not all(65 < ord(c) < 128 or ord(c) == 32 for c in keyword):
16 return False
17 return True
18
19# Total Number Judgment of Nicknames
20def is_all_di(keyword):
21 for uchar in keyword:
22 if not (uchar >= '\u0030' and uchar <= u'\u0039'):
23 return False
24 return True
25
26# Nicknames include facial expression judgment
27def have_img(keyword):
28 # Here's a unicode encoding set for most of the pictures
29 # See: https://en.wikipedia.org/wiki/Emoji
30 img_re = re.compile(u'['
31 u'\U0001F300-\U0001F64F'
32 u'\U0001F680-\U0001F6FF'
33 u'\u2600-\u2B55]+',
34 re.UNICODE)
35 if img_re.findall(keyword) :
36 return True
37 return False
38
39# Chinese + Digital Nickname Judgment
40def is_ch_di(keyword):
41 for c in keyword:
42 if not ('\u4e00' <= c <= '\u9fa5') and not (c >= '\u0030' and c <= u'\u0039'):
43 return False
44 return True
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
(4) Data classification and calculation of various quantities
1list_name = get_name()
2print("In total:"+str(len(list_name))+"A Wechat Name")
3for i in range(len(list_name)):
4 result = classification_name(list_name[i])
5 if result == 'ch': # Chinese
6 ch_name_number +=1
7 ch_name.append(list_name[i])
8 if result == 'en': # English
9 en_name_number +=1
10 en_name.append(list_name[i])
11 if result == 'di': # number
12 di_name_number +=1
13 di_name.append(list_name[i])
14 if result == 'img': # Expressive
15 img_name_number +=1
16 img_name.append(list_name[i])
17 if result == 'ch_di': # Chinese and Numbers
18 ch_di_name_number +=1
19 ch_di_name.append(list_name[i])
20 if result == 'other': # Other
21 oth_name_number +=1
22 oth_name.append(list_name[i])
23
24print("Number of Chinese nicknames:"+ str(ch_name_number))
25# print(ch_name)
26print("Number of English nicknames:"+ str(en_name_number))
27#print(en_name)
28print("Number of pure digital nicknames:"+ str(di_name_number))
29# print(di_name)
30print("Contains the number of facial nicknames:"+ str(img_name_number))
31# print(img_name)
32print("Number of Chinese and Digital Mixed Nicknames:"+ str(ch_di_name_number))
33print(ch_di_name)
34print("Number of other nicknames:"+ str(oth_name_number))
35# print(oth_name)
Operation results:
1 Total: 3549 Wechat Names 2 Number of Chinese nicknames: 1514 Number of English nicknames: 569 4 Number of pure digital nicknames: 9 5 Contains the number of facial nicknames: 400 6 Number of Chinese and Digital Mixed Nicknames: 19 7 Number of other nicknames: 1038
3. Get user drawings (only user age)
3. Visit the portrait interface of English named users to get the age range of active and new users for nearly 30 days.
1# Getting User Age Segment
2def get_data():
3 # Get token and process it
4 t = get_token().strip('"')
5 # Then, the token value and other parameters after processing are used as parameters of post mode, and the user portrait api is invoked.
6 post_user_api = " https://api.weixin.qq.com/datacube/getweanalysisappiduserportrait?access_token="
7 post_user_url = post_user_api + t
8 # Access access to profile data (data for the past month)
9 data = json.dumps({
10 "begin_date" : "2018-07-21",
11 "end_date" : "2018-08-19"})
12 # pick up information
13 user_portrait_data = get_info(post_user_url, data)
14 # Time slot
15 ref_date = user_portrait_data['ref_date']
16 # new user
17 visit_uv_new = user_portrait_data['visit_uv_new']
18 Active Users
19 visit_uv = user_portrait_data['visit_uv']
20 # Age group
21 print(ref_date )
22 print((visit_uv_new['ages']))
23 print((visit_uv['ages']))
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
Operation results:
1# id: for age group number name: age group name value: number of people in that age group
220180721-20180819
3[{'id': 0, 'name': 'Unknown', 'value': 6}, {'id': 1, 'name': '17 Under age', 'value': 18}, {'id': 2, 'name': '18-24 year', 'value': 118}, {'id': 3, 'name': '25-29 year', 'value': 75}, {'id': 4, 'name': '30-39 year', 'value': 81}, {'id': 5, 'name': '40-49 year', 'value': 14}, {'id': 6, 'name': '50 Age and above', 'value': 7}]
4[{'id': 0, 'name': 'Unknown', 'value': 6}, {'id': 1, 'name': '17 Under age', 'value': 20}, {'id': 2, 'name': '18-24 year', 'value': 147}, {'id': 3, 'name': '25-29 year', 'value': 88}, {'id': 4, 'name': '30-39 year', 'value': 95}, {'id': 5, 'name': '40-49 year', 'value': 20}, {'id': 6, 'name': '50 Age and above', 'value': 10}]
3. Interesting data cleaning and analysis
1. Visualization Analysis of Weixin Name Type Data
Core code:
1# 1. Classification of Wechat Names: Rose Pie Charts
2from pyecharts import Pie
3# Data acquisition from the above code
4attr = ["Pure Chinese nicknames", "Pure English nickname", "Pure digital nickname", "Contains emoticon nicknames", "Mixed Chinese and Digital Nicknames", "Other nicknames"]
5v1 = [1514, 569, 9, 400, 19, 1038]
6pie = Pie("Wechat Name Classification Pie Map", title_pos='center', width=900)
7pie.add(
8 "Proportion",
9 attr,
10 v1,
11 center=[50, 50],
12 is_random=True,
13 radius=[30, 75],
14 rosetype="area",
15 is_legend_show=False,
16 is_label_show=True,
17)
18pie.render("render_01.html")
Operation effect:
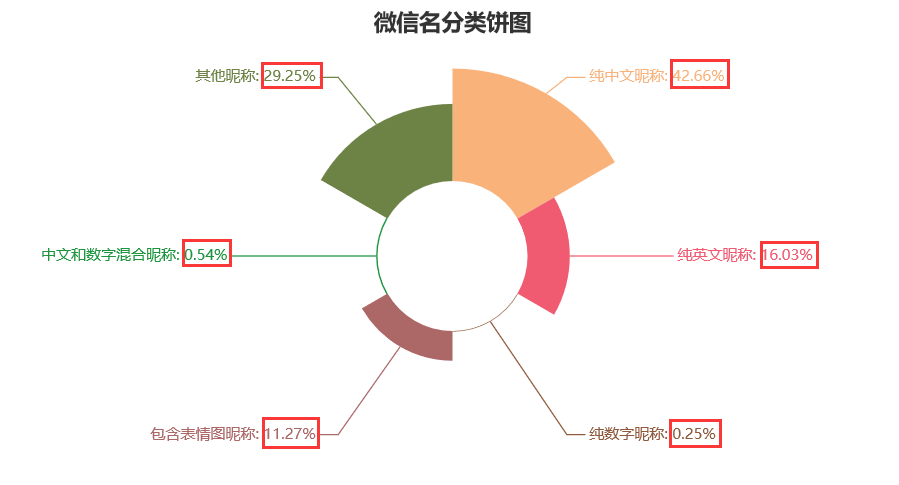
It can be seen from this that the proportion of Weixin nicknames in Chinese is the largest, accounting for 42.66%, followed by other nicknames (Chinese-English mixed, character and other types), accounting for 29.25%, and the larger category is pure English nicknames, accounting for 16.03%, and includes facial packages nicknames, accounting for 11.27%, such as pure digital nicknames and Chinese digital mixed nicknames. For a relatively small proportion, the most common Chinese and digital mixed nicknames are organization name/name+contact method, some marketing numbers are commonly used. By contrast, most people prefer to use pure Chinese as nicknames, which not only reflects a kind of cultural feelings, but also briefly introduces themselves, such as my Wechat Name is an old watch. This is a nickname of my junior high school. When my friends talk about my cousin, they are not necessarily talking about relatives. They may be talking about me, haha.
2. Visualization analysis of age group of micro-credit households
Core code:
1# 2. User Age: Rose Pie Chart
2from pyecharts import Pie
3# Data acquisition from the above code
4attr = ["Unknown", "17 Under age", "18-24 year", "25-29 year", "30-39 year", "40-49 year","50 Age and above"]
5v1 = [12, 38, 265, 163, 176, 34,17]
6pie = Pie("Pie chart of age group of micro-credit households", title_pos='center', width=900)
7pie.add(
8 "Proportion",
9 attr,
10 v1,
11 center=[50, 50],
12 is_random=True,
13 radius=[30, 75],
14 rosetype="area",
15 is_legend_show=False,
16 is_label_show=True,
17)
18pie.render("render_02.html")
Operation effect:
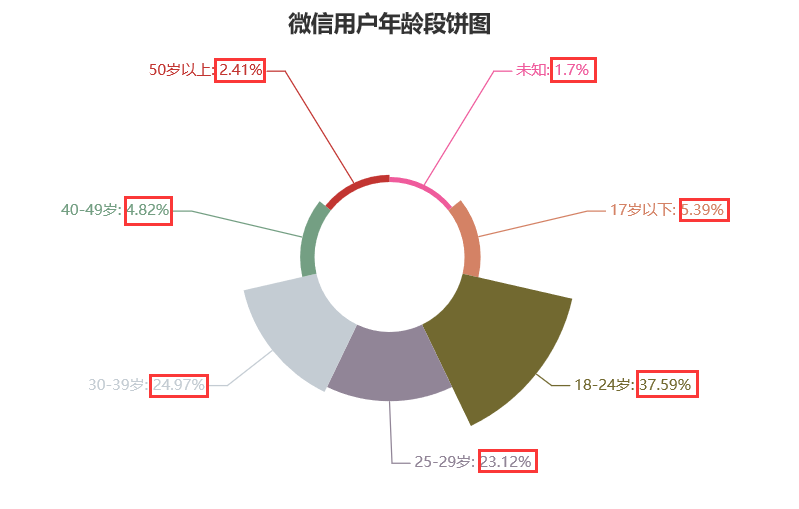
It can be seen that among the age group, the proportion of the post-95-00 aged 18-24 is the largest, reaching 37.59%, followed by the post-80-90 aged 30-39, reaching 24.97%, followed by the post-90-95 aged 25-29, reaching 23.12%. Other age groups can be roughly divided into two categories: children-biased and elderly-biased, with a total of 10.21%. My personal perception The reason for the small number of people is that children and the elderly play little Weixin, let alone the Weixin applet. For children, the role of Weixin is to play games (login accounts). For the elderly, Weixin is mainly used for chatting, which is already more complex, and the use of the applet may be more complex for the elderly. There is also a lack of necessity.
3. Word Cloud Analysis of Which Words and Expression Packets Wechat Names Are More Popular
(1) Continue to use pyecharts to generate word clouds
Core code:
1# Clean up data and generate word clouds
2def split_word(test_str):
3 test_str = re.sub('[,,. . \r\n]', '', test_str)
4 # jieba
5 segment = jieba.lcut(test_str)
6 words_df = pd.DataFrame({'segment': segment})
7 # quoting=3 means that the contents in stopwords.txt are not quoted at all
8 stopwords = pd.read_csv(r"H:\PyCoding\ Analysis_wx_name\stopwords.txt", index_col=False, quoting=3, sep="\t", names=['stopword'], encoding='utf-8')
9 words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
10 words_stat = words_df.groupby(by=['segment'])['segment'].agg({"count": numpy.size})
11 words_stat = words_stat.reset_index().sort_values(by=["count"], ascending=False)
12 test = words_stat.head(200).values
13 codes = [test[i][0] for i in range(0,len(test))]
14 counts = [test[i][1] for i in range(0,len(test))]
15 wordcloud = WordCloud(width=1300, height=620)
16 wordcloud.add("Wechat nickname", codes, counts, word_size_range=[20, 100])
17 wordcloud.render('render_03.html')
Operation effect:

(2) Using wordcloud+matplotlib to generate higher-level nephogram
Core code:
1# It's interesting to talk about matplotlib graphics visualization next time.
2# Call the get_name function to get all the tweets
3text = get_name()
4# Call the jiebaclearText function to clean up the data (this function is the same as the above word-cutting idea)
5text1=jiebaclearText(text)
6#Generating word nephogram
7bg = plt.imread(r"G:\small_pig.jpg")
8#Generative Cloud
9wc=WordCloud(
10 background_color="wathet", #Set the background to white and default to black
11 mask=bg, # Set the content range of the word cloud (all areas except the white area of the specified image will cover the content of the word cloud)
12 margin=10, #Set the edges of the picture
13 max_font_size=70, #Maximum font size displayed
14 random_state=20, #Return a PIL color for each word
15 font_path='G:\simkai.ttf' #Chinese processing, with the system's own font
16 # You can download this font here: http://www.font5.com.cn/font_download.php?Id=534&part=1245067666
17 ).generate(text1)
18#Set fonts for pictures
19my_font=fm.FontProperties(fname='G:\simkai.ttf')
20# Picture Background
21bg_color = ImageColorGenerator(bg)
22# Start drawing
23plt.imshow(wc.recolor(color_func=bg_color))
24# Remove the coordinate axis for the cloud image
25plt.axis("off")
26# Preserve the Cloud Map
27wc.to_file("render_04.png")
The original outline of the word cloud:

Operation effect:

Because the second method can't parse the expression map, there is no expression. Besides, the content of the nephogram displayed by the two methods is almost the same.
Through the word cloud, we can see at a glance that you use the most, except for Chinese, it is the expression map. Whether there are such big red lips in your Wechat circle of friends, it seems to me that there are, hahaha ~When we simply look at the Chinese in the word cloud, we find that it is like the sun, sunshine, smile, lovely, happy, love, future. The more positive and upward words are liked by everyone, which also reflects the positive and optimistic of everyone's heart. Of course, there are names like Lili, Xu and Chen, which are also used more in nicknames, and there is no lack of cold words like sadness and coldness.
4. Emotional analysis through nicknames (bold guess)
01 | Weixin nickname in Chinese
Wechat nicknames can be divided into two categories: their real names and other nicknames.
People who use their own names directly as Weixin nicknames are mostly straight-forward and frank.
Their tweets are generally used for acquaintances'social intercourse and daily office work. They usually do not add unfamiliar people casually. Even if they use their real names, they are not afraid to reveal personal information. This is an inappropriate metaphor: they do not do things in a bad mood, they are not afraid of ghosts knocking at the door, haha ha.
Most people with other nicknames have their own opinions. Perhaps nicknames are their expectations for the future. Perhaps nicknames are their attitudes towards life, or some irrelevant words, cool words. (Guess)

02 | Weixin nickname in English
Out of personal preferences or job needs, some people will give themselves an easy-to-remember and pleasant English name, such as Tom, Abby, Jason, and often let you use English names when introducing yourself.
For them, the English name is equivalent to their second name. It is not much different from their original name when they use it as a micro-message name.
Others will deliberately avoid those common English names and choose a smaller group. They are more concerned about improving their "pushing style", like to be innovative, and pursue fashion and avant-garde. (Guess)

03 | Wechat nicknames with emoticons
Many girls will add various emoticons to the name of the Wechat. From the above analysis of the word nebula, we can see that one big red lip is most used, the other may be a love, a rose, a star, or emoji expression of the system itself.
They may feel that this is a special decoration that can make their names distinct from others.
Most of these girls have delicate carefulness, romantic life style and a vigorous girl heart. (Guess)

04 | Wechat nicknames are professional
Generally speaking, those who take the initiative to bring a letter "A" in front of their micro-letters are mostly micro-dealers or purchasers who advertise in the circle of friends all day long.
More formally, they are all in the form of "company name + name". These people are basically salesmen or real estate intermediaries... Or the real big man.~
Others change their suffixes from time to time according to their different stages of work.
Know a friend who works as a human resource in a real estate company. In order to enjoy the holidays, she will change the name of Weixin to "during the holidays" in order to remind those who believe in her work during the holidays.
Others, on the contrary, changed the name of Wechat directly to "working overtime" in order to show their special enthusiasm. emmm is mainly for the boss to see it. (Conjecture)

05 | Wechat nickname with idol name
Needless to say, these are typical star-chasers, and most of them are girls, such as Mrs. Wu Yifan, Cai Xukun's secret girlfriend, Hu Ge's little wife... Not surprisingly, their heads are usually their beloved beans themselves.
They usually call their idols on Weibo, and their circle of friends will send many related recommendations. If someone praises their love for beans, they will feel that they have met a bosom friend. On the contrary, if someone says something bad about their love for beans, they will immediately blacken up...
Keep in mind that in front of the star-chaser, don't lift the bar lightly and point fingers at her beans... (Conjecture)
Python resource sharing qun 784758214, including installation packages, PDF, learning videos, here is the gathering place of Python learners, zero foundation, advanced, are welcome.

06 | Wechat nickname is a four-character word
Looking carefully at the Weixin names of the elders, we can see that they especially like to use four-character words as nicknames.
The greatest common feature of these four words is that they convey a quiet and good atmosphere of years: "life is like tea", "flowers are fragrant", "good is like water", "people's heart is still", "clouds are light and breeze is light"...
Young people mark themselves with unique micro-letters. Older uncles and aunts just want to place a pure life ideal on them. (Conjecture)

It is said that the name is the second face of a person. The success of Wechat Name often gives people a better impression.
Does your Wechat Name have any special meaning? Talk in the comments section.