This paper mainly discusses the following issues:
- What is Asynchronous programming?
- Why use asynchronous programming?
- What are the ways to implement asynchronous programming in Python?
- Python 3.5 how to use async/await to implement asynchronous web crawler?
The so-called asynchrony is relative to the concept of Synchronous. Is it easy to cause confusion because when I first came into contact with these two concepts, it is easy to regard synchronization as simultaneous, rather than Parallel? However, in fact, synchronization or asynchrony is aimed at the concept of time axis. Synchronization means sequential and unified time axis, while asynchrony means disordered and efficiency first time axis. For example, when the crawler is running, first grab page a, and then extract the link of page B of the next layer. At this time, the operation of the crawler program can only be synchronized, and page B can only be grabbed after page a is processed; However, for the two independent pages A1 and A2, during the processing of A1 network request, instead of letting the CPU idle and A2 wait behind, it is better to process A2 first and wait until who completes the network request first. In this way, the CPU can be used more fully, but the execution order of A1 and A2 is uncertain, that is, asynchronous.
Obviously, in some cases, using asynchronous programming can improve program operation efficiency and reduce unnecessary waiting time. The reason why this can be done is that the CPU of the computer operates independently of other devices, and the operation efficiency of the CPU is much higher than the reading and writing (I/O) efficiency of other devices. In order to take advantage of asynchronous programming, people have come up with many methods to reschedule and Schedule the running sequence of programs, so as to maximize the utilization of CPU, including processes, threads, collaborations, etc. (for details, please refer to< Process, thread, coroutine, synchronous, asynchronous and callback in Python >). Before Python 3.5, @ types Coroutine transforms a Generator into a coroutine as a modifier. In Python 3.5, a coroutine is defined by the keyword "async/await". At the same time, it also brings "asyncio" into the standard library for asynchronous programming based on coroutine.
To use asyncio, you need to understand the following concepts:
- Event loop
- Coroutine
- Future & Task
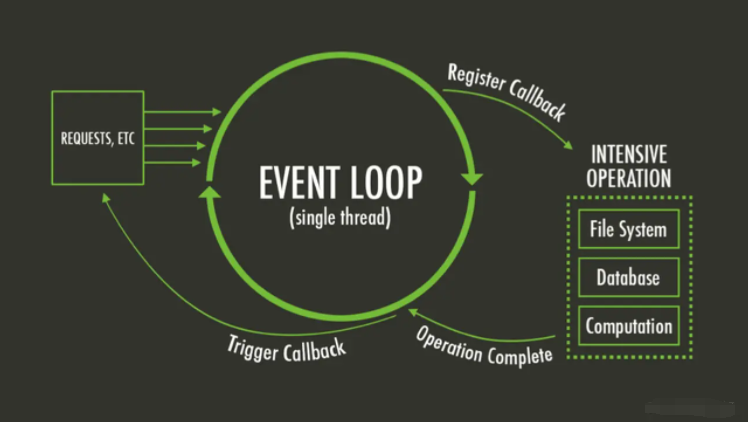
Event loop
Understand JavaScript or node JS is certainly familiar with event loop. We can regard it as a loop scheduling mechanism. It can arrange the operations that need to be executed by the CPU to be executed first, and the behaviors that will be blocked by I/O will enter the waiting queue:
asyncio # comes with an event loop:
import asyncio loop = anscio.get_event_loop() # loop.run_until_complete(coro()) loop.close()Copy code
Of course, you can also choose other implementation forms, such as those adopted by the "Sanic" framework uvloop , it's also very simple to use (I haven't verified whether the performance is better, but at least it's more convenient to use "uvloop" on Jupyter Notebook):
import asyncio import uvloop loop = uvloop.new_event_loop() asyncio.set_event_loop(loop)Copy code
Coroutine
After Python 3.5, it is recommended to use the keyword "async/await" to define the coprocessor. It has the following characteristics:
- Suspend the behavior that may be blocked through , await , and continue to execute until there is a result. Event loop also schedules the execution of multiple processes based on this;
- Unlike ordinary functions, a coroutine cannot be executed by calling coro(), but only by placing it in the Event loop for scheduling.
A simple example:
import uvloop
import asyncio
loop = uvloop.new_event_loop()
asyncio.set_event_loop(loop)
async def compute(a, b):
print("Computing {} + {}...".format(a, b))
await asyncio.sleep(a+b)
return a + b
tasks = []
for i, j in zip(range(3), range(3)):
print(i, j)
tasks.append(compute(i, j))
loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
### OUTPUT
"""
0 0
1 1
2 2
Computing 0 + 0...
Computing 1 + 1...
Computing 2 + 2...
CPU times: user 1.05 ms, sys: 1.21 ms, total: 2.26 ms
Wall time: 4 s
"""Copy code
Because we can't know when the coroutine will be called and returned, asyncio , provides the object , Future , to track its execution results.
Future & Task
Future , which is equivalent to , Promise in , JavaScript , is used to save the results that may be returned in the future. Task is a subclass of future. Different from future, it contains a collaborative process to be executed (thus forming a task to be scheduled). Also take the above program as an example. If you want to know the calculation results, you can use {asyncio ensure_ The future () method wraps the collaboration into a task, and finally reads the results:
import uvloop
import asyncio
loop = uvloop.new_event_loop()
asyncio.set_event_loop(loop)
async def compute(a, b):
print("Computing {} + {}...".format(a, b))
await asyncio.sleep(a+b)
return a + b
tasks = []
for i, j in zip(range(3), range(3)):
print(i, j)
tasks.append(asyncio.ensure_future(compute(i, j)))
loop.run_until_complete(asyncio.gather(*tasks))
for t in tasks:
print(t.result())
loop.close()
### OUTPUT
"""
0 0
1 1
2 2
Computing 0 + 0...
Computing 1 + 1...
Computing 2 + 2...
0
2
4
CPU times: user 1.62 ms, sys: 1.86 ms, total: 3.49 ms
Wall time: 4.01 s
"""Copy code
Asynchronous network request
Python's best library for handling network requests is requests (there should be no one), but because its request process is synchronously blocked, it has to choose aiohttp . In order to compare the difference between synchronous and asynchronous cases, first forge a fake asynchronous processing server:
from sanic import Sanic
from sanic.response import text
import asyncio
app = Sanic(__name__)
@app.route("/<word>")
@app.route("/")
async def index(req, word=""):
t = len(word) / 10
await asyncio.sleep(t)
return text("It costs {}s to process `{}`!".format(t, word))
app.run()Copy code
The processing time of the server is directly proportional to the length of the request parameter (word). The synchronous request mode is adopted. The operation results are as follows:
import requests as req
URL = "http://127.0.0.1:8000/{}"
words = ["Hello", "Python", "Fans", "!"]
for word in words:
resp = req.get(URL.format(word))
print(resp.text)
### OUTPUT
"""
It costs 0.5s to process `Hello`!
It costs 0.6s to process `Python`!
It costs 0.4s to process `Fans`!
It costs 0.1s to process `!`!
CPU times: user 18.5 ms, sys: 2.98 ms, total: 21.4 ms
Wall time: 1.64 s
"""Copy code
Using asynchronous request, the running results are as follows:
import asyncio
import aiohttp
import uvloop
URL = "http://127.0.0.1:8000/{}"
words = ["Hello", "Python", "Fans", "!"]
async def getPage(session, word):
with aiohttp.Timeout(10):
async with session.get(URL.format(word)) as resp:
print(await resp.text())
loop = uvloop.new_event_loop()
asyncio.set_event_loop(loop)
session = aiohttp.ClientSession(loop=loop)
tasks = []
for word in words:
tasks.append(getPage(session, word))
loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
session.close()
### OUTPUT
"""
It costs 0.1s to process `!`!
It costs 0.4s to process `Fans`!
It costs 0.5s to process `Hello`!
It costs 0.6s to process `Python`!
CPU times: user 61.2 ms, sys: 18.2 ms, total: 79.3 ms
Wall time: 732 ms
"""Copy code
In terms of running time, the effect is obvious.
Unfinished to be continued
Next, we will simply encapsulate aiohttp, which is more conducive to the access of users disguised as ordinary browsers, so as to serve the crawler to send network requests.