1, Request library usage
1. Overview
HTTP Requests need to be sent for interface testing. The most basic HTTP libraries in python include urlib, Httplib2, Requests, Treq, etc. Here we recommend using the Request library for interface testing.
Requests is based on urllib and uses the HTTP Library of Apache 2 licensed open source protocol. It is more convenient than urllib, which can save us a lot of work and fully meet the needs of HTTP testing. At present, many python crawlers also use the requests library.
Functional features:
- Keep alive & connection pool
- Internationalized domain names and URL s
- Session with persistent Cookie
- Browser based SSL authentication
- Automatic content decoding
- Basic / digest authentication
- Elegant key/value Cookie
- Automatic decompression
- Unicode response body
- HTTP (S) proxy support
- File block upload
- Stream Download
- connection timed out
- Block request
- support. Netrc (user configuration script file)
2. Requests installation
The pip installation command is as follows:
pip install requests
Installation inspection
Open the cmd window, enter python, and then import requests. If the installation is successful, there is no prompt
import requests
3. Requests basic application
Send different types of HTTP requests
Different methods are built in the requests library to send different types of http requests. The usage is shown in the following figure:
request_basic.py
import requests
base_url='http://httpbin.org/' #Send GET type request r=requests.get(base_url+'/get') print(r.status_code) #Send post type request r=requests.post(base_url+'/post') print(r.status_code) #Send a put type request r=requests.put(base_url+'/put') print(r.status_code) #Send a delete type request r=requests.delete(base_url+'/delete') print(r.status_code)
As a result of execution, 200 is a status code indicating that the transmission request was successful.
4. Parameter transfer
Pass URL parameters
Generally, in GET requests, we use query string to pass parameters. The methods used in the requests library are as follows:
request_basic.py
import requests
base_url='http://httpbin.org'
param_data={'user':'zxw','password':'6666'}
r=requests.get(base_url+'/get',params=param_data)
print(r.url)
print(r.status_code)
results of enforcement

Pass body parameter
In a post request, general parameters are passed in the request body. In Requests, the usage is as follows:
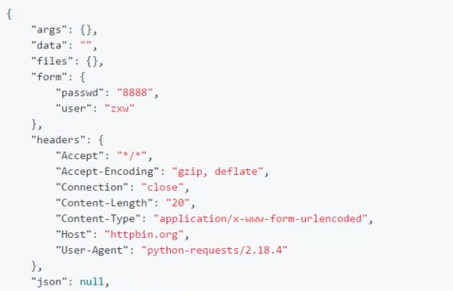
form_data={'user':'zxw','passwd':'8888'}
r=requests.post(base_url+'/post',data=form_data)
print(r.text)
Execution results:
5. Request header settings
If you want to add an HTTP header to the request header, simply pass a dict to the header parameter.
The usage is as follows:
form_data={'user':'zxw','passwd':'8888'}
header={"user-agent":"Mozilla/5.0"}
r=requests.post(base_url+'/post',data=form_data)
print(r.text)
- Accept, request header field, used to specify what types of information the client can accept.
- Accept language, which specifies the language type acceptable to the client.
- Accept encoding, which specifies the content encoding acceptable to the client.
- Host, used to specify the host IP and port number of the requested resource. Its content is the location of the original server or gateway of the requested URL. From http1 From version 1, the Request must contain this content.
- Cookie s, also commonly used in the plural, are data stored locally by the website to identify users for Session tracking. The attention function of Cookies is to maintain the current access Session.
- Referer, this content is used to identify the page from which the request is sent. The server can get this information and do corresponding processing, such as source statistics, anti-theft chain processing, etc.
- User agent, referred to as UA, is a special string header, which enables the server to identify the operating system and version, browser and version and other information used by the customer. Adding this information when doing a crawler can disguise as a browser. If it is not added, it is likely to be recognized as a crawler.
- Content type, i.e. Internet Media Type, also known as MIMI type, is used to represent the media type information in the specific request in the HTTP protocol message header. For example, application/x-www-form-urlencoded represents form data, text/html represents HTML format, image/gif represents GIF picture, and application/json represents JSON type.
6. Cookie settings
Cookies can be set through the Cookie parameter
request_advance.py
import requests
cookie= {'user':'admin'}
r=requests.get(base_url+'/cookie',cookies=cookie)
print(r.text)
Get cookie
Request Baidu home page, and then obtain the cookie. The implementation is as follows:
#Get cookie
r=requests.get('http://www.baidu.com')
print(type(r.cookies))
print(r.cookies)
for key,value in r.cookies.items():
print(key+':'+value)

7. Timeout
You can make requests stop waiting for a response after the number of seconds set with the timeout parameter, so as to prevent some requests from waiting without a response.
r=requests.get(base_url+'cookies',cookies=sookies,timeout=0.01) print(r.text)
8. File upload
Requests can use the parameter files to simulate submitting some file data. Adding some interfaces requires us to upload files. We can also use it to upload files. The implementation is very simple. Examples are as follows:
#Upload file
file={'file':open('logo.png','rb')}#r:resd b: it is read in binary mode
r=requests.post(base_url+'/post',files=file)
print(r.test)
9. Session object
In computers, especially in network applications, it is called "Session control". The Session object stores the attributes and configuration information required for a specific user Session. In this way, when the user jumps between the Web pages of the application, the variables in the object stored in the Session object will not be lost, but will exist throughout the user Session.
For example, you first log in and then open the personal center details page. How can the personal center details page know that the information of the user who just logged in is displayed? Then you need to use Session to store relevant information.
During interface testing, there are often dependencies between interfaces. For example, one of the following two requests is to set cookies and the other is to obtain cookies. Without Session saving mechanism, the second interface cannot obtain the cookie value set by the first interface.
#Set cookie s r=requests.get(url+'/cookies/set/user/zxw') print(r.text) #Get cookie r=requests.get(url+'/cookie') print(r.text)
The Session object of Requests allows you to maintain certain parameters across Requests. It also maintains cookie s between all Requests issued by the same Session instance The specific use is as follows:
#Generate session object s=requests.Session() #Set cookies r=s.get(url+'/cookies/set/user/zxw') print(r.text) #Get cookie r=s.get(url+'/cookies') print(r.text)
Therefore, using Session, we can simulate the same Session without worrying about Cookies. It is usually used to simulate the next operation after successful login.
10. SSL certificate validation
Requests can validate SSL certificates for HTTPS requests, just like web browsers. SSL authentication is enabled by default. If the certificate authentication fails, requests will throw SSLError: if you don't want to verify SSL, you can use the verify parameter to turn off SSL authentication
The following is the certificate to verify the 12306 website.
r=requests.get('https://www.12306.cn')
#Turn off authentication SSL
#r=requests.get('https://www.12306.cn',verifg=False)
print(r.text)
Tips: the certificate of 12306 is issued to yourself, so authentication failure will occur.
11. Proxy settings
Agent, also known as network agent, is a special network service that allows a network terminal (generally a client) to connect indirectly with another network terminal (generally a server) through this service.
The proxy server is located between the client and accessing the Internet. The server receives the request from the client and then sends the request to the target website instead of the client. All traffic routes come from the ip address of the proxy server, so as to obtain some resources that cannot be obtained directly.
For some interfaces, request several times during testing, and the content can be obtained normally. However, once large-scale and frequent Requests (such as performance testing) are started, the server may turn on authentication or even block the IP directly. In order to prevent this from happening, we need to set up an agent to solve this problem. We need to use the parameter proxies in Requests, and agents are often used in crawlers.
Western thorn free proxy IP
#Proxy settings
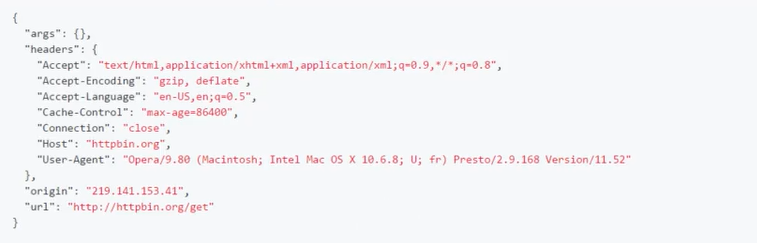
proxies={'http':'http://219.141.153.41:80'}
r=requests.get(url+'/get',proxies=proxies)
print(r.text)
The running results are as follows: you can see that the origin parameter is the proxy ip set for us
12. Identity authentication
Many interfaces require identity authentication: Requests supports multiple identity authentication. The specific use methods are as follows:
The following cases mainly verify two identity types: BasicAuth and DigestAuth
from requests.auth import HTTPBasicAuth
from requests.auth import HTTPDigestAuth
#Authentication BasicAuth
r=requests.get(url+'/basic-auth/admin1/8888',auth=HTTPBasicAuth('admin','8888'))
print(r.text)
#Identity authentication DigestAuth
r=requests.get(url+'/digest-auth/admin2/8888',auth=HTTPDigestAuth('admin','8888'))
print(r.text)
Operation results:
{"authenticated":true,"user":"admin1"}
{"authenticated":true,"user":"admin2"}
13. Streaming request
Some interfaces have special return values, which do not simply return one result, but multiple results. For example, for a query interface, the return value is the product information in the top 10 of the ranking list.
For this type of interface, we need to use the iterative method ITER to process the result set_ Lines(), as follows:
import json r=requests.get(base_url+'/staream/10',stream=True) #If no encoding is set for the response content, the default setting is utf-8 if r.encoding is None: r.encoding='utf-8' #Iterative processing of response results for line in r.iter_lines(decode_unicode=True) if line: data=json.loads(line) print(data['id'])
14. Integrate into Unittest
The actual interface test needs to be tested for different parameter scenarios. In addition
Set assertions and generate test reports.
Use case design
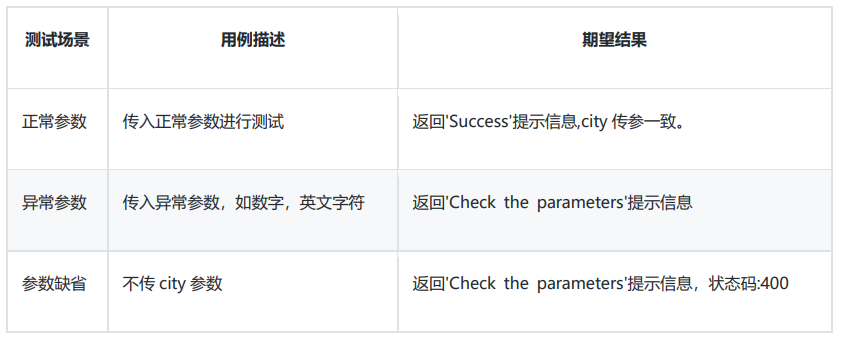
code implementation
text_api_unittest.py
import unittest
import requests
from urllib import parse
from time import sleep
class WeatherTest(unittest.TestCase):#unitest framework syntax
def setUp(self):#Equivalent to init
self.url='https://www.sojson.com/open/api/weather/json.shtml'
#Proxy settings to avoid ip blocking
# self.proxies={'http':'http://125.118.146.222:6666'}
def test_weather_beijing(self):
'''Test Beijing Weather'''
data = {'city': 'Beijing'}
city = parse.urlencode(data).encode('utf-8')
# r=requests.get(self.url,params=city,proxies=self.proxies)
r=requests.get(self.url,params=city)
result=r.json()
#Assertion (built-in method of unitest)
self.assertEqual(result['status'],200)
self.assertEqual(result['message'],'Success !')
self.assertEqual(result['city'],'Beijing')
#Set the interval to avoid ip blocking
sleep(3)#Stop 3 seconds after execution
def test_weather_param_error(self):
'''Parameter exception'''
data={'city':'666'}
# r=requests.get(self.url,params=data,proxies=self.proxies)
r=requests.get(self.url,params=data)
result=r.json()
self.assertEqual(result['message'],'Check the parameters.')
sleep(3)
def test_weather_no_param(self):
'''Parameter default'''
# r=requests.get(self.url,params=data,proxies=self.proxies)
r=requests.get(self.url)
result=r.json()
self.assertEqual(result['message'],'Check the parameters.')
self.assertEqual(result['status'],400)
sleep(3)
if __name__ == '__main__':
unittest.main()#unitest framework syntax; Execute only the functions starting with test
15. Generate test report
- First create the folders common and reprot
- download HTMLTestRunner , put it in the common folder
- Create run The PY module is at the same level as the case directory where the package interface test files are stored
run.py
import unittest,os
from commen import HTMLTestRunner#Introducing HTMLTestRunner
def all_case():
dir = os.getcwd()#Get current path
result_path = os.path.join(dir, 'reprot') + '\\reprot.html'#Directory for generating test reports
fb = open(result_path, "wb")#Open the html file of the test report
runner = HTMLTestRunner.HTMLTestRunner(
stream=fb,
title="Test report",#Test report title
description="Automated test case execution"#describe
)
case_dir=os.path.join(dir,'case')#Get the path of the case, that is, the use case directory to be executed
discover=unittest.defaultTestLoader.discover(
case_dir,#Address of case file to be executed
pattern='test*.py'#All py files starting with test in the case directory
)
runner.run(discover)#Generate test report
fb.close()#Close file
if __name__=='__main__':
#Return instance
all_case()