When understanding basic data types, we need to know what basic data types are? Number int, Boolean bool, string str, list, tuple, dictionary dict, etc., including their basic usage and common methods, which will be listed here for reference. Then we need to know some operators, because these basic data types are often used for some operations and so on.
1, Operator
Operations can usually be divided into two types according to the final value, that is, the result is a specific value and the result is a bool value. Which results are specific values – > arithmetic operations, assignment operations, and which results are bool values? - > Comparison operation, logic operation and member operation.
If you are interested in software testing and want to know more about testing, solve testing problems, and get started guide to help you solve the confusion encountered in testing, we have technical experts here. If you are looking for a job, just come out of school, or have worked, but often feel that there are many difficulties, feel that you don't study well enough in testing, and want to continue to study, if you want to change careers, you are afraid you won't learn, you can join us
, you can get the latest software testing factory interview materials and Python automation, interface and framework building learning materials in the group!
1. Arithmetic operation
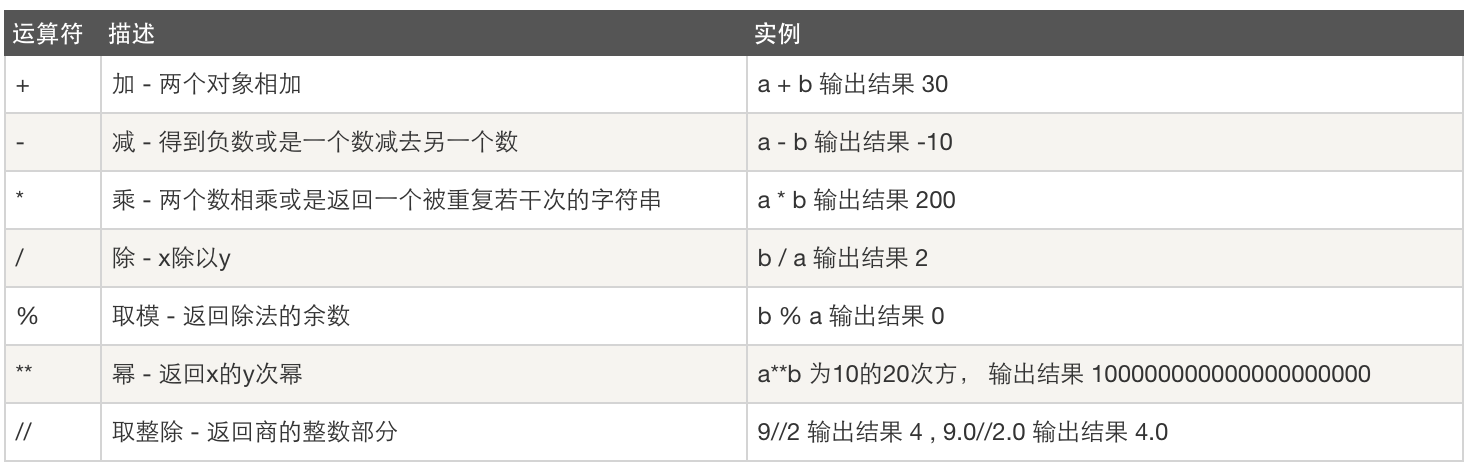
2. Assignment operation

3. Comparison operation
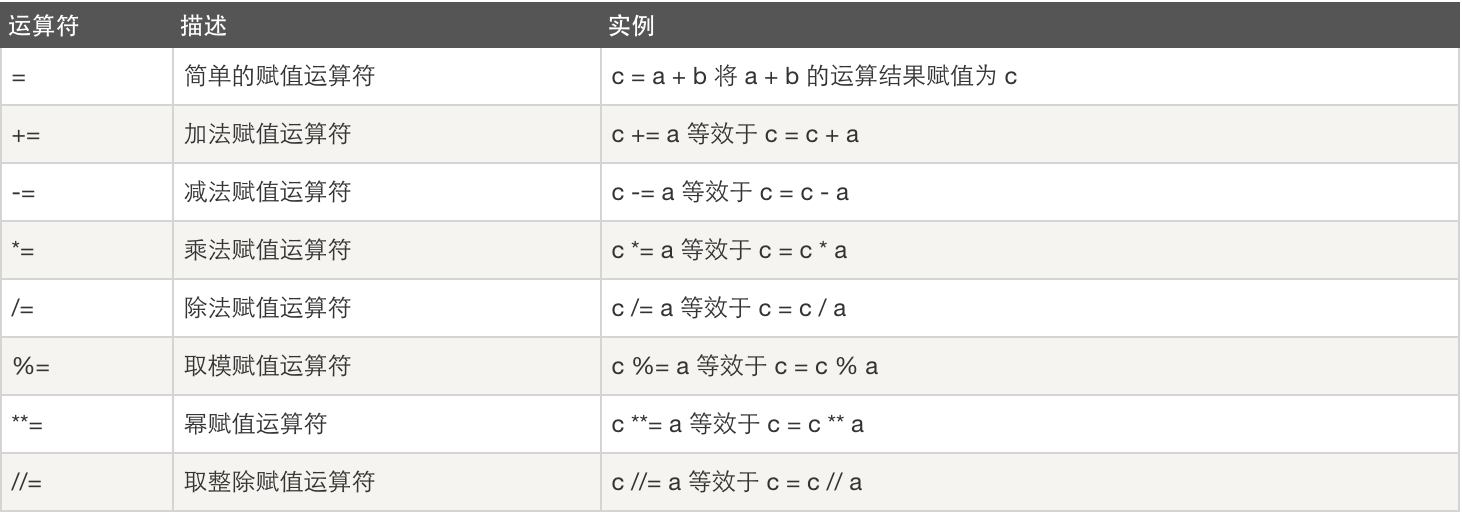
4. Logical operation

5. Member operation

2, Basic data type
1. Number - > int class
Of course, for numbers, Python's number types include int integers, long integers, float floating-point numbers, complex complex numbers, and Boolean values (0 and 1). Only int integers are introduced here.
In Python 2, the size of integers is limited, that is, when the number exceeds a certain range, it is no longer an int type, but a long long integer. In Python 3, regardless of the size and length of integers, they are collectively referred to as integer ints.
There are two main methods:
Int -- > convert the string data type to int type. Note: the contents in the string must be numbers
#!/usr/bin/env python # -*- coding:utf-8 -*- s = '123' i = int( s ) print( i)
bit_ Length() -- > converts a number to binary and returns the least number of bits
#!/user/bin/env python #-*- coding:utf-8 -*- i =123 print( i.bit_length() ) #The output result is: >>>5
2. Boolean - > bool class
For Boolean values, there are only two results, True and False, which correspond to 0 and 1 in binary, respectively. There are too many True or True values. We only need to know the values of False or False - None, empty (i.e. [] / () / "" / {}), 0;
#The following results are false: None, '' [], (), {} and 0
>>> bool(None)
False
>>> bool('')
False
>>> bool([])
False
>>> bool(0)
False
>>> bool(())
False
>>> bool({})
False
3. String - > STR class
String is the most commonly used data type in Python and has many uses. We can use single quotation marks' 'or double quotation marks'' to create string.
The string is not modifiable. For all characters, we can introduce the string from the aspects of index, slice, length, traversal, deletion, segmentation, clearing white space, case conversion, judging what starts with, etc.
Create string
#!/usr/bin/env python # -*- coding:utf-8 -*- #String form: use '' or '' to create a string name ='little_five' print(name)
section
#Get the slice. The complex number represents the penultimate, starting from 0 >>> name ="little-five" >>> name[1] 'i' >>> name[0:-2] #From the first to the penultimate, excluding the penultimate 'little-fi'
Index – > index(), find()
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Revised edition
name = "little_five"
#Index -- > get index, syntax - > str.index (STR, beg = 0, end = len (string)), the second parameter specifies the start index beg, and the third parameter ends the index end, which refers to getting the index of the substring from the start index to the end index
print(name.index("l",2,8)) #Look for 'l' before index interval 2-8. The second 'l' is found, and its index is 4
#Find -- > is similar to index
print(name.find("l",2)) #The result is also 4
The difference between index() and find() is that if the character or sequence of the index is not in the string, it returns - 1 for index – "ValueError: substring not found, and - 1 for find -- >.
#!/usr/bin/env python
# -*- coding:utf-8 -*-
name = "little_five"
print(name.index("q",2))
#index -- "output is:
>>>Traceback (most recent call last):
File "C:/Users/28352/PycharmProjects/learning/Day13/test.py", line 5, in <module>
print(name.index("q",2))
ValueError: substring not found
print(name.find("q",2))
#find -- "output is:
>>> -1
Length -- > len ()
name = "little_five" #Gets the length of the string print(len(name)) #Output is: >>> 11
Note: len() method – > can also be used for other data types, such as viewing the number of elements in lists, tuples and dictionaries.
Delete -- > del
#Deleting a string is also deleting a variable >>> name ="little-five" >>> del name >>> name Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'name' is not defined
Determine the string content -- > isalnum(), isalpha(), isdigit()
#Judge whether all are numbers >>> a ="123" >>> a.isdigit() True >>> b ="a123" >>> b.isdigit() False #Determine whether it is all letters >>> d ="alx--e" >>> d.isalpha() False >>> c ="alex" >>> c.isalpha() True #Judge whether it is all numbers or letters >>> e ="abc123" >>> e.isalnum() True
Case conversion -- > capitalize(), lower(), upper(), title(), casefold()
#!/usr/bin/env python # -*- coding:utf-8 -*- #Case conversion >>> name ="little_five" #Initial capital -- > capitalize >>> name.capitalize() 'Little_five' #Turn to title -- > title >>> info ="my name is little_five" >>> info.title() 'My Name Is Little_Five' #Convert all to lowercase -- > lower >>> name ="LITTLE_FIVE" >>> name.lower() 'little_five' #Convert all to uppercase -- > upper >>> name = "little_five" >>> name.upper() 'LITTLE_FIVE' #Case conversion -- > swapcase >>> name ="lIttle_fIve" >>> name.swapcase() 'LiTTLE_FiVE'
Determine what starts and ends -- > startswitch(), endswitch()
#Judge what to start and end with
>>> name ="little-five"
#Judge what ends
>>> name.endswith("e")
True
#What does judgment begin with
>>> name.startswith("li")
True
Expand – > expandtabs ()
#Expandtabs -- > returns a new string generated after the tab symbol ('\ t') in the string is converted to a space. It is usually used for tabular output
info ="name\tage\temail\nlittlefive\t22\t994263539@qq.com\njames\t33\t66622334@qq.com"
print(info.expandtabs(10))
#Output is:
name age email
little-five 22 994263539@qq.com
james 33 66622334@qq.com
Format output – > format (), format_map()
#Format output -- > format, format_map
#forma method
#Mode 1
>>> info ="my name is {name},I'am {age} years old."
>>> info.format(name="little-five",age=22)
"my name is little-five,I'am 22 years old."
#Mode II
>>> info ="my name is {0},I'am {1} years old."
>>> info.format("little-five",22)
"my name is little-five,I'am 22 years old."
#Mode III
>>> info ="my name is {name},I'am {age} years old."
>>> info.format(**{"name":"little-five","age":22})
"my name is little-five,I'am 22 years old."
#format_map method
>>> info ="my name is {name},I'am {age} years old."
>>> info.format_map({"name":"little-five","age":22})
"my name is little-five,I'am 22 years old."
jion method
#Join -- > join(): an array of connection strings. Connect the string, tuple and elements in the list with the specified character (separator) to generate a new string #character string >>> name ="littefive" >>> "-".join(name) 'l-i-t-t-e-f-i-v-e' #list >>> info = ["xiaowu","say","hello","world"] >>> "--".join(info) 'xiaowu--say--hello--world'
Split -- > split(), partition()
#There are two methods for segmentation - partition and split
#Partition -- > the string can only be divided into three parts to generate a list
>>> name ="little-five"
>>> name.partition("-")
('little', '-', 'five')
#Split -- > splits a string, and can specify how many times to split, and returns a list
>>> name ="little-five-hello-world"
>>> name.split("-")
['little', 'five', 'hello', 'world']
>>> name.split("-",2) #Specify how many times to split
['little', 'five', 'hello-world']
>>>
Replace -- > replace
#replace
>>> name ="little-five"
>>> name.replace("l","L")
'LittLe-five'
#You can also specify parameters to replace several
>>> name.replace("i","e",2)
'lettle-feve'
Clear blank --> strip(),lstrip(),rstrip()
#Remove spaces
>>> name =" little-five "
#Remove the spaces on the left and right sides of the string
>>> name.strip()
'little-five'
#Remove the space to the left of the string
>>> name.lstrip()
'little-five '
#Remove the space to the right of the string
>>> name.rstrip()
' little-five'
Replace -- > maketran, translate
#Replace one by one >>> a ="wszgr" >>> b="I am Chinese," >>> v =str.maketrans(a,b) #Create a corresponding relationship, and the length of the two strings should be consistent >>> info ="I'm a Chinese people,wszgr" >>> info.translate(v) "I'm a Chine yes e people,I am Chinese,"
4. List - > list class
A list is composed of a series of elements arranged in order. Its elements can be any data type, that is, numbers, strings, lists, tuples, dictionaries, Boolean values, etc. at the same time, its elements are modifiable.
Its form is:
1 names = ['little-five","James","Alex"] 2 #perhaps 3 names = list(['little-five","James","Alex"])
Index, slice
#Index -- > starts at 0, not at the beginning name =["xiaowu","little-five","James"] print(name[0:-1]) #Slice -- > the negative number is the penultimate, which is closed on the left and open on the right. If it is not written, the front indicates that it contains all the previous elements, and the back indicates all the subsequent elements m1 =name[1:] print(m1) #The output is -- > ['little five', 'James'] m2 =name[:-1] print(m2) #The output is -- > ['Xiaowu', 'little five']
Append – > append()
#Append element -- > append()
name =["xiaowu","little-five","James"]
name.append("alex")
print(name)
#The output is -- ['Xiaowu', 'little five', 'James',' Alex ']
Expand – > extend ()
#Extension -- it adds a string or a list element to the list
#1, Add additional list elements to the list
name =["xiaowu","little-five","James"]
name.extend(["alex","green"])
print(name)
#The output is -- > ['Xiaowu', 'little five', 'James',' Alex ',' green ']
#2, Adds a string element to the list
name =["xiaowu","little-five","James"]
name.extend("hello")
print(name)
#The output is -- > Xiaowu ',' little five ',' James', 'Alex', 'green', 'H', 'e', 'l', 'l', 'o']
#3, Add dictionary elements to the list. Note: the key of the dictionary.
name =["xiaowu","little-five","James"]
name.extend({"hello":"world"})
print(name)
Note: the difference between extending extend and appending append: – > the former is to add elements as a whole, and the latter is to decompose and add elements of data types to the list. Example:
#Extend -- > extension name =["xiaowu","little-five","James"] name.extend(["hello","world"]) print(name) Output as-->['xiaowu', 'little-five', 'James', 'hello', 'world'] #Append -- > append name.append(["hello","world"]) print(name) Output as -->['xiaowu', 'little-five', 'James', ['hello', 'world']]
Insert() -- > insert
1 #Insert() insert -- > you can specify a location in the insert list. As mentioned earlier, the list is ordered 2 name =["xiaowu","little-five","James"] 3 name.insert(1,"alex") #The index starts at 0, the second 4 print(name)
Pop() -- > fetch
#pop() -- fetching, you can assign the fetched value as a string to another variable name =["xiaowu","little-five","James"] special_name =name.pop(1) print(name) print(special_name,type(special_name)) #The output is: ['xiaowu ',' James'] # little-five <class 'str'>
remove() – > remove, del -- > delete
#Remove -- > remove, whose parameter is the name of the value of the list
name =["xiaowu","little-five","James"]
name.remove("xiaowu")
print(name)
#Its output is: ['little five ',' James']
#Del -- > delete
name =["xiaowu","little-five","James"]
#name.remove("xiaowu")
del name[1]
print(name)
#Its output is: ['xiaowu ',' James']
sorted() – > sort. The default is positive order. If reverse =True is added, it means reverse order
#positive sequence num =[11,55,88,66,35,42] print(sorted(num)) -->Numerical sorting name =["xiaowu","little-five","James"] print(sorted(name)) -->String sorting #Output is: [11, 35, 42, 55, 66, 88] # ['James', 'little-five', 'xiaowu'] #Reverse order num =[11,55,88,66,35,42] print(sorted(num,reverse=True)) #Output: [88, 66, 55, 42, 35, 11]
5. Tuple - > tuple class
Tuples are immutable lists. Its features are similar to list. It is identified by parentheses instead of square brackets.
#tuple
name = ("little-five","xiaowu")
print(name[0])
6. Dictionary - > dict class
The dictionary is a series of key value pairs. Each key value pair is separated by commas. Each key corresponds to a value. The corresponding value can be accessed by using the key. Disordered.
The definition of a key must be immutable, that is, it can be a number, a string, a tuple, a Boolean value, etc.
The definition of value can be any data type.
#Definition of dictionary
info ={
1:"hello world", #Keys are numbers
("hello world"):1, #Key is tuple
False:{
"name":"James"
},
"age":22
}
Traversal -- > items, keys, values
info ={
"name":"little-five",
"age":22,
"email":"99426353*@qq,com"
}
#key
for key in info:
print(key)
print(info.keys())
#Output as: dict_keys(['name', 'age', 'email'])
#Key value pair
print(info.items())
#Output as -- > Dict_ items([('name', 'little-five'), ('age', 22), ('email', '99426353*@qq,com')])
#value
print(info.values())
#Output as: dict_values(['little-five', 22, '99426353*@qq,com'])
7. Set -- > set class
On the definition of set: in my opinion, set is like a basket. You can store things in it or take things from it, but these things are disordered. It is difficult for you to specify to take something alone; At the same time, it can filter through certain methods to get the part of things you need. Therefore, a set can be created, added, deleted, and related operations.
Properties of the collection:
1. Weight removal
2. Disorder
3. Each element must be of immutable type, i.e. (hashable type, which can be used as the key of the dictionary).
Create: set, frozenset
#1. When created, it will be automatically de duplicated, and its elements are immutable data types, that is, numbers, strings and tuples
test01 ={"zhangsan","lisi","wangwu","lisi",666,("hello","world",),True}
#perhaps
test02 =set({"zhangsan","lisi","wangwu","lisi",666,("hello","world",),True})
#2. Creation of immutable sets -- > frozenset()
test =frozenset({"zhangsan","lisi","wangwu","lisi",666,("hello","world",),True})
Add: add, update
#Update single value -- > Add
names ={"zhangsan","lisi","wangwu"}
names.add("james") #Its parameter must be of type hashable
print(names)
#Update multiple values -- > Update
names ={"zhangsan","lisi","wangwu"}
names.update({"alex","james"})#Its parameters must be a collection
print(names)
Delete: pop, remove, discard
#Randomly delete -- > pop
names ={"zhangsan","lisi","wangwu","alex","james"}
names.pop()
print(names)
#Specifies to delete. If the element to be deleted does not exist, an error is reported -- > remove
names ={"zhangsan","lisi","wangwu","alex","james"}
names.remove("lisi")
print(names)
#Specifies to delete. If the element to be deleted does not exist, ignore the method -- > discard
names ={"zhangsan","lisi","wangwu","alex","james"}
names.discard("hello")
print(names)
Relational operations: intersection &, union |, difference set -, intersection complement ^, issubset, isupperset
For example, there are two classes, English class and mathematics class. We need to make statistics on the enrollment in these two classes, such as the names of students who have signed up for both English class and mathematics class. At this time, we can apply it to the relationship operation of the set:
english_c ={"ZhangSan","LiSi","James","Alex"}
math_c ={"WangWu","LiuDeHua","James","Alex"}
#1. Intersection -- > in a and in B
#Statistics of students in both English and mathematics classes
print(english_c & math_c)
print(english_c.intersection(math_c))
#The output is: {Alex ',' James'}
#2. Union -- > in a or in B
#Count all the students in the two classes
print(english_c | math_c)
print(english_c.union(math_c))
#The output is: {James', 'ZhangSan', 'LiuDeHua', 'LiSi', 'Alex', 'WangWu'}
#3. Difference set -- > in a not in B
#Statistics of students who only sign up for English class
print(english_c - math_c)
print(english_c.difference(math_c))
#The output is: {'LiSi', 'ZhangSan'}
4,Intersection complement
#Count the students who sign up for only one class
print(english_c ^ math_c)
#The output is: {'LiuDeHua', 'ZhangSan', 'WangWu', 'LiSi'}
Judge whether the relationship between two sets is subset, parent set -- > issubset, isupperset
#5. Issubset -- > whether n is a subset of m
# Issuperset -- > is n the parent set of m
n ={1,2,4,6,8,10}
m ={2,4,6}
l ={1,2,11}
print(n >= m)
#print(n.issuperset(m)) #Is n the parent set of m
#print(n.issuperset(l))
print(m <=n)
#print(m.issubset(n)) #Is m a subset of n
If you are interested in software testing and want to know more about testing, solve testing problems, and get started guide to help you solve the confusion encountered in testing, we have technical experts here. If you are looking for a job, just come out of school, or have worked, but often feel that there are many difficulties, feel that you don't study well enough in testing, and want to continue to study, if you want to change careers, you are afraid you won't learn, you can join us
, you can get the latest software testing factory interview materials and Python automation, interface and framework building learning materials in the group!