Foreword
Python is a high-level programming language with interpretive, object-oriented and dynamic data types. It was invented by Guido van Rossum at the end of 1989 and the first public release was released in 1991.
Since its launch, Python has been welcomed by the majority of developers. It has its excellence in the fields of website development, web crawler, data analysis, machine learning, artificial intelligence and so on.
In the "Python basic tutorial", I will introduce the usage of Python from various fields. Today, I will start with the most commonly used web crawler.
The main purpose of web crawler is to collect network information regularly, analyze and classify the information after saving, and finally display it to relevant users through reports as business reference. In recent years, I have also done a project to collect information from the government website of the tax bureau, analyze the collected tax policies, tax rate changes of various industries and the new tax law promulgated by the state, and integrate the analysis results into the financial and tax management platform for financial accounting.
In order to simplify the process, take the commonly used weather network as an example this time( http://www.weather.com.cn/ ), regularly collect the regional weather conditions, and finally display the data as a chart.
catalogue
4, Using matplotlib to display data
1, Page download
Here we use the request class in the urllib library, which has two commonly used
method:
1. urlretrieve is used to download web pages
1 def urlretrieve(url: str, 2 filename: Optional[str] = ..., 3 reporthook: Optional[(int, int, int) -> None] = ..., 4 data: Optional[bytes] = ...)
Parameter description
url: Web page address url
filename: Specifies the path to save the data locally (if this parameter is not specified, urllib will generate a temporary file to save the data);
reporthook: it is a callback function, which will be triggered when the server is connected and the corresponding data block is transmitted. We can use this callback function to display the current download progress.
Data: refers to the data post ed to the server. This method returns a tuple (filename, headers) containing two elements. Filename represents the path saved to the local, and header represents the response header of the server.
2. urlopen can directly open the remote page like opening a document. The difference is that urlopen is in read-only mode
1 def urlopen(url: Union[str, Request], 2 data: Optional[bytes] = ..., 3 timeout: Optional[float] = ..., 4 *, 5 cafile: Optional[str] = ..., 6 capath: Optional[str] = ..., 7 cadefault: bool = ..., 8 context: Optional[SSLContext] = ...)
Parameter description
URL: the location of the target resource in the network. It can be a string representing the URL or a urllib Request object. Please go to for details
Data: data is used to indicate the additional parameter information in the request sent to the server (such as the content submitted by online translation, online answer, etc.). By default, data is None. At this time, the request is sent in the form of GET; When the user gives the data parameter, the request is sent in POST mode.
Timeout: set the access timeout of the website
cafile, capath, cadefault: HTTP request used to implement trusted CA certificate. (basically rarely used)
context parameter: realize SSL encrypted transmission.
1 class Weather():
2
3 def __init__(self):
4 #Determine the download path and take the date as the file name
5 self.path='E:/Python_Projects/Test/weather/'
6 self.filename=str(datetime.date.today()).replace('-','')
7
8 def getPage(self,url):
9 #Download page and save
10 file=self.path+self.filename+'.html'
11 urlretrieve(url,file,None,None)After running the method, you can see that the whole static page has been saved in the folder
2, Data reading
We can find the required html data through the html code of re.
Here are some re common methods
1,re.compile(pattern,flags = 0 )
Compile regular expression patterns into regular expression objects, which can be used for matching using match(), search(), and other methods described below
2,re.search(pattern,string,flags = 0 )
Scan the string to find the first location where the regular expression pattern produces a match, and then return the corresponding match object. None if no position in the string matches the pattern, return; Otherwise, false is returned. Note that this is different from finding a zero length match at a point in the string.
3,re.match(pattern,string,flags = 0 )
If zero or more characters at the beginning of the string match the regular expression pattern, the corresponding matching object is returned. None if the string does not match the pattern, return; Otherwise, false is returned. Note that this is different from zero length matching.
4,re.fullmatch(pattern,string,flags = 0 )
If the entire string matches the regular expression pattern, the corresponding match object is returned. None if the string does not match the pattern, return; Otherwise, false is returned. Note that this is different from zero length matching.
5,re.split(pattern,string,maxsplit = 0,flags = 0 )
Splits strings by occurrence patterns. If capture parentheses are used in the pattern, the text of all groups in the pattern will also be returned as part of the result list. If maxplit is not zero, Max split occurs and the rest of the string is returned as the last element of the list.
6,re.findall(pattern,string,flags = 0 )
Returns all non overlapping matches of the pattern in a string in the form of a string list. Scan the string from left to right and return matches in the order found. If there are one or more groups in this mode, a group list is returned; Otherwise, a list is returned. If the schema contains multiple groups, this will be a list of tuples. Empty matches are included in the result.
7,re.finditer(pattern,string,flags = 0 )
Returns an iterator that produces matching objects in all non overlapping matches of the RE pattern of type string. Scan the string from left to right and return matches in the order found. Empty matches are included in the result.
This example is relatively simple. It can be seen that the temperature during the day / night in the area is included in < p class = "TEM" > < span > 30 < / span > < EM > ° C < / EM > < / P >, which can be directly through re Compile() found data.
However, in different pages, the data may be bound through the background or when the page is rendered. At this time, you need to carefully find the data source and obtain it through links.
1 def readPage(self):
2 #Read page
3 file=open(self.path+self.filename+'.html','r',1024,'utf8')
4 data=file.readlines()
5 #Find out the day temperature and night temperature
6 pat=re.compile('<span>[0-9][0-9]</span>')
7 data=re.findall(pat,str(data))
8 file.close()
9 #Filter the temperature value and return list
10 list1 = []
11 for weather in data:
12 w1 = weather.replace('<span>', '')
13 w2 = w1.replace('</span>', '')
14 list1.append(w2)
15 return list1Finally, the list array is returned, which contains the day temperature and night temperature of the day
3, Data saving
Save the day's date, daytime temperature and night temperature to the database
1 def save(self,list1):
2 #Save to database
3 db = MySQLdb.connect("localhost", "root", "********", "database", charset='utf8')
4 cursor = db.cursor()
5 sql = 'INSERT INTO weather(date,daytime,night) VALUES ('+self.filename+','+list1[0]+','+list1[1]+')'
6 try:
7 cursor.execute(sql)
8 db.commit()
9 except:
10 # Rollback on error
11 db.rollback()
12 # Close database connection
13 db.close()
4, Using matplotlib to display data
After accumulating data for several days in the database, the data is displayed through the matplotlib library
1 def display():
2 # Rotate the X axis 90 degrees
3 plt.xticks(rotation=90)
4 # Get data from database
5 db = MySQLdb.connect("localhost", "root", "********", "database", charset='utf8')
6 cursor = db.cursor()
7 sql = 'SELECT date,daytime,night FROM weather'
8 try:
9 cursor.execute(sql)
10 data=np.array(cursor.fetchall())
11 db.commit()
12 except:
13 # Rollback on error
14 db.rollback()
15 #Data is converted into date array, daytime temperature array and nighttime temperature array
16 if len(data)!=0:
17 date=data[:,0]
18 # y-axis data needs to be converted into int form, otherwise it will be arranged in string form
19 daytime=(np.int16(data[:,1]))
20 night=(np.int16(data[:,2]))
21 plt.xlabel('Date')
22 plt.ylabel('Temperature')
23 plt.title('Weather')
24 # Display data
25 plt.plot(date,daytime,label='day')
26 plt.plot(date,night,label='night')
27 plt.legend()
28 plt.show()Display results
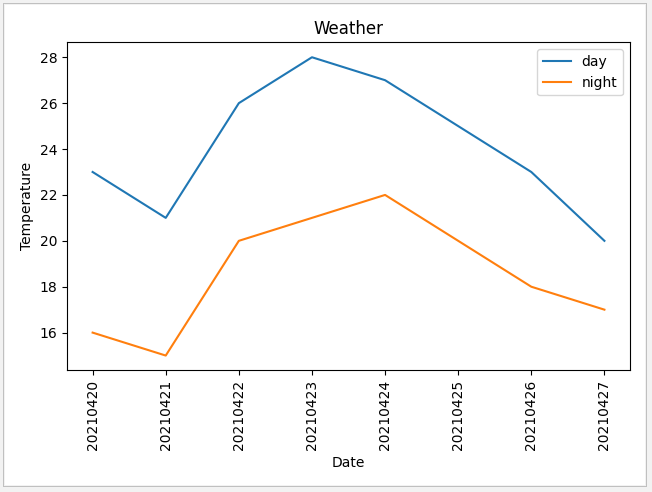
5, Timer
Use the Timer to execute once a day, download data, and then refresh the screen
1 def start(): 2 weather=Weather() 3 weather.getPage(url) 4 data=weather.readPage() 5 weather.save(data) 6 display() 7 t = threading.Timer(86400, start) 8 t.start() 9 10 url='http://www.weather.com.cn/weather1d/101280101.shtml' 11 if __name__ == '__main__': 12 start()
All source code
from urllib.request import urlretrieve,urlopen
from matplotlib import pyplot as plt
import numpy as np,threading,re,datetime,MySQLdb
class Weather():
def __init__(self):
#Determine the download path and take the date as the file name
self.path='E:/Python_Projects/Test/weather/'
self.filename=str(datetime.date.today()).replace('-','')
def getPage(self,url):
#Download page and save
file=self.path+self.filename+'.html'
urlretrieve(url,file,None,None)
def readPage(self):
#Read page
file=open(self.path+self.filename+'.html','r',1024,'utf8')
data=file.readlines()
#Find out the day temperature and night temperature
pat=re.compile('<span>[0-9][0-9]</span>')
data=re.findall(pat,str(data))
file.close()
#Filter the temperature value and return list
list1 = []
for weather in data:
w1 = weather.replace('<span>', '')
w2 = w1.replace('</span>', '')
list1.append(w2) # Save data
return list1
def save(self,list1):
#Save to database
db = MySQLdb.connect("localhost", "root", "********", "database", charset='utf8')
cursor = db.cursor()
sql = 'INSERT INTO weather(date,daytime,night) VALUES ('+self.filename+','+list1[0]+','+list1[1]+')'
try:
cursor.execute(sql)
db.commit()
except:
# Rollback on error
db.rollback()
# Close database connection
db.close()
def display():
# Rotate the X axis 90 degrees
plt.xticks(rotation=90)
# Get data from database
db = MySQLdb.connect("localhost", "root", "********", "database", charset='utf8')
cursor = db.cursor()
sql = 'SELECT date,daytime,night FROM weather'
try:
cursor.execute(sql)
data=np.array(cursor.fetchall())
db.commit()
except:
# Rollback on error
db.rollback()
#Data is converted into date array, daytime temperature array and nighttime temperature array
if len(data)!=0:
date=data[:,0]
# y-axis data needs to be converted into int form, otherwise it will be arranged in string form
daytime=(np.int16(data[:,1]))
night=(np.int16(data[:,2]))
plt.xlabel('Date')
plt.ylabel('Temperature')
plt.title('Weather')
# Display data
plt.plot(date,daytime,label='day')
plt.plot(date,night,label='night')
plt.legend()
plt.show()
def start():
weather=Weather()
weather.getPage(url)
data=weather.readPage()
weather.save(data)
display()
t = threading.Timer(86400, start)
t.start()
url='http://www.weather.com.cn/weather1d/101280101.shtml'
if __name__ == '__main__':
start()
summary
This example only introduces the use of crawlers from the simplest point of view. Corresponding to the actual application scenario, it is only the tip of the iceberg. In reality, we often encounter many problems, such as IP address being blocked, data binding unable to be obtained directly, data encryption and so on, which will be introduced in detail later.
Due to time constraints, please comment on some omissions in the article.
yes. Python # development interested friends welcome to join QQ group: 790518786 Discuss together!
Friends who are interested in Java development are welcome to join QQ group: 174850571 Discuss together!
Friends interested in C# development are welcome to join QQ group: 162338858 Discuss together!
Author: wind dust prodigal son
https://blog.csdn.net/Leslies2/article/details/116297306
For original works, please indicate the author and source when reprinting