The most basic crawler -- Python requests+bs4 crawling UIBE Academic Affairs Office
1. Use tools
1.Python 3.x
2. Third party library requests,bs4
3. Browser
2. Specific ideas
The website of UIBE academic affairs office is highly open and has no anti crawler measures. It only needs to use the most basic crawler means. Use the requests library to obtain the web page source code, use the beautiful soup Library in bs4 to parse the web page, and locate the target element.
First, the url of the Academic Affairs Office website is: http://jwc.uibe.edu.cn/
Import two third-party libraries:
import requests from bs4 import BeautifulSoup
Then get the url, send a request to it, get its text content, and use BeautifulSoup to transform it.
r = requests.get(r"http://jwc.uibe.edu.cn / ") # use the original string here to avoid character misreading soup = BeautifulSoup(r.text)#The "soup" is the object converted using beautifulsup
Then we locate the element where the crawling target is located. In this example, we plan to crawl the titles of all important notices on the home page
Open the web page, check F12, click the positioning logo in the upper left corner to open the positioning mode, and then click the first important notice
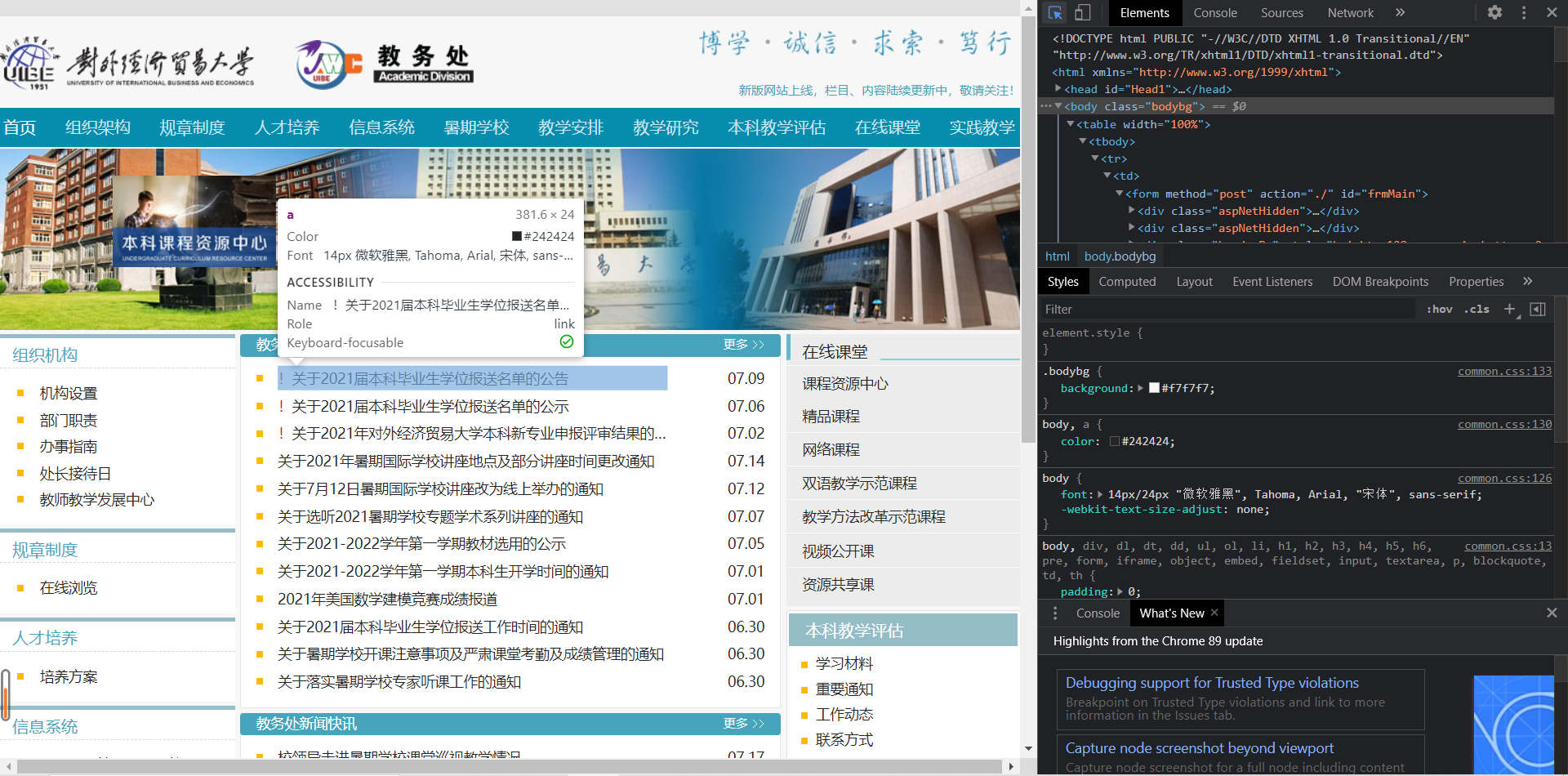
From the interface source code on the right, we can observe that each notification is displayed in each li element of the page ul(class = newsList) element, so we first use find to locate the ul element, and then use find in the element_ All found all li elements:
div_newslist = soup.find("ul", class_ = "newsList")#Since class is a python keyword, you need to underline it after class
li_lst = div_newslist.find_all("li")#Obtained li_lst is a list, and each element of the list is a li element
Further observation shows that the title of the notification is displayed in the a tag in li, and the title attribute is displayed in the tag, so li is traversed_ Lst list, print out the title attribute in the a tag of each element:
for li in li_lst:
a = li.find("a")
print(a["title"])#The print attribute is in brackets and the print content is in brackets Form of text
#If you want to store the crawled contents in a file, you can use a list here for temporary storage, and then write the list to the file
We can get all the notification titles we need:

3. Code
All codes are as follows:
import requests
from bs4 import BeautifulSoup
r = requests.get(r"http://jwc.uibe.edu.cn / ") # use the original string here to avoid character misreading
soup = BeautifulSoup(r.text)#The "soup" is the object converted using beautifulsup
div_newslist = soup.find("ul", class_ = "newsList")#Since class is a python keyword, you need to underline it after class
li_lst = div_newslist.find_all("li")#Obtained li_lst is a list, and each element of the list is a li element
for li in li_lst:
a = li.find("a")
print(a["title"])#The print attribute is in brackets and the print content is in brackets Form of text
#If you want to store the crawled contents in a file, you can use a list here for temporary storage, and then write the list to the file
4. Attention
1. Coding problem
Some websites may not use the default "ISO" of requests for encoding, and the content obtained by requests may appear garbled. In this case, you can view the encoding by viewing the approximate_encoding property of the requests object, and change the encoding method by setting its encoding property.
it_encoding = r.apparent_encoding print(it_encoding)#The encoding method of the web page determined according to the request header r.encoding = it_encoding
2. Dormancy
When you need to crawl multiple websites under a server, you may be prohibited from accessing them because the access speed is too fast. In this case, you generally need to sleep for a certain time during crawling.
import time import random #Import two libraries time.sleep(random.random())#Sleep a random time from 0 to 1, unit: s #This statement is usually added before each access #When the number of visits is large and the anti crawler measures of the target website are strict, the random interval can be extended
3. Request header problem
Some websites will determine whether the request is initiated by manual users by identifying the request header. If the crawler's default request header is used, the probability of refusing access is high.
For some websites with anti crawling measures but not very strict anti crawling measures, the simplest request header can be used:
header = {"user-agent" : "Mozilla/5.0"}
For some strict websites, it may be necessary to construct special request headers to simulate human access.
For other anti crawling methods, please refer to my other blogs