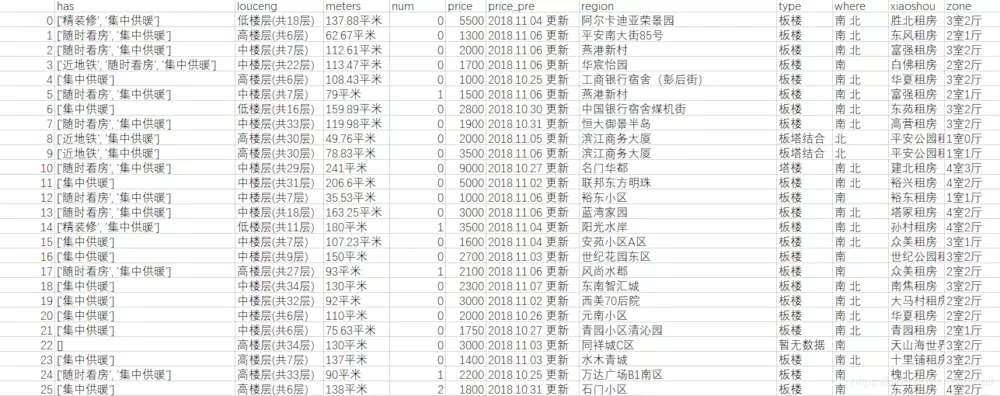
1. Write in front
As an active developer in Beijing, Tianjin and Hebei, we should take a look at some data of Shijiazhuang, an international metropolis. This blog crawls the rental information of Chain Home. The data can be used as data analysis material in the following blog.
The website we need to crawl is https://sjz.lianjia.com/zufang./
2. Analyzing Web Sites
First, determine which data we need
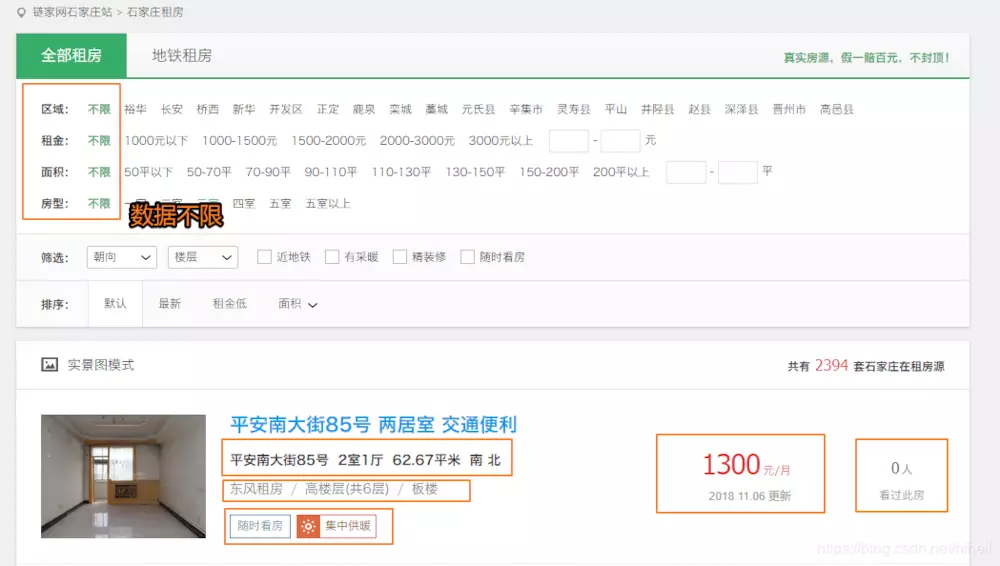
As you can see, the yellow box is the data we need.
Next, determine the page turning rule
https://sjz.lianjia.com/zufang/pg1/ https://sjz.lianjia.com/zufang/pg2/ https://sjz.lianjia.com/zufang/pg3/ https://sjz.lianjia.com/zufang/pg4/ https://sjz.lianjia.com/zufang/pg5/ ... https://sjz.lianjia.com/zufang/pg80/ Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
3. Analyzing Web Pages
With paging addresses, links can be spliced quickly. We use lxml module to parse the source code of web pages and get the desired data.
This encoding uses a new module, fake_user agent, which can randomly access a UA (user-agent). The module is relatively simple to use and can go to Baidu for many tutorials.
This blog mainly uses calling a random UA.
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random} # Call a random UA
Because the page numbers can be spliced out quickly, the pandas module is used to grab and write csv files by using a cooperative program.
from fake_useragent import UserAgent
from lxml import etree
import asyncio
import aiohttp
import pandas as pd
class LianjiaSpider(object):
def __init__(self):
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random}
self._data = list()
async def get(self,url):
async with aiohttp.ClientSession() as session:
try:
async with session.get(url,headers=self._headers,timeout=3) as resp:
if resp.status==200:
result = await resp.text()
return result
except Exception as e:
print(e.args)
async def parse_html(self):
for page in range(1,77):
url = "https://sjz.lianjia.com/zufang/pg{}/".format(page)
print("Crawling{}".format(url))
html = await self.get(url) # Getting Web Content
html = etree.HTML(html) # Analysis of Web Pages
self.parse_page(html) # Match the data we want
print("Storing data....")
######################### Data Writing
data = pd.DataFrame(self._data)
data.to_csv("Chain Home Net Rental Data.csv", encoding='utf_8_sig') # write file
######################### Data Writing
def run(self):
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(self.parse_html())]
loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
l = LianjiaSpider()
l.run()
The above code lacks a function to parse the web page, so let's fix it up next.
def parse_page(self,html):
info_panel = html.xpath("//div[@class='info-panel']")
for info in info_panel:
region = self.remove_space(info.xpath(".//span[@class='region']/text()"))
zone = self.remove_space(info.xpath(".//span[@class='zone']/span/text()"))
meters = self.remove_space(info.xpath(".//span[@class='meters']/text()"))
where = self.remove_space(info.xpath(".//div[@class='where']/span[4]/text()"))
con = info.xpath(".//div[@class='con']/text()")
floor = con[0] # floor
type = con[1] # style
agent = info.xpath(".//div[@class='con']/a/text()")[0]
has = info.xpath(".//div[@class='left agency']//text()")
price = info.xpath(".//div[@class='price']/span/text()")[0]
price_pre = info.xpath(".//div[@class='price-pre']/text()")[0]
look_num = info.xpath(".//div[@class='square']//span[@class='num']/text()")[0]
one_data = {
"region":region,
"zone":zone,
"meters":meters,
"where":where,
"louceng":floor,
"type":type,
"xiaoshou":agent,
"has":has,
"price":price,
"price_pre":price_pre,
"num":look_num
}
self._data.append(one_data) # Add data
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
Soon, the data will crawl almost.