
Character encoding
Introduction to character coding
Because the computer only recognizes binary, but users (Global humans) can see all kinds of languages when using the computer, so they must "translate" different languages in order for the computer to recognize them. The standard of this translation is the character coding table, and numbers and characters correspond one by one.
'translation 'process
-
User → computer → user
**character → Digital (01 binary)→ character**
Development history of string coding
👉[ASCII](ASCII_ Baidu Encyclopedia (baidu.com)
1. ASCII code
The computer was originally invented by Americans. In order to make the computer recognize English characters, Americans invented ASCII code, which records the corresponding relationship between English and numbers. As shown below:
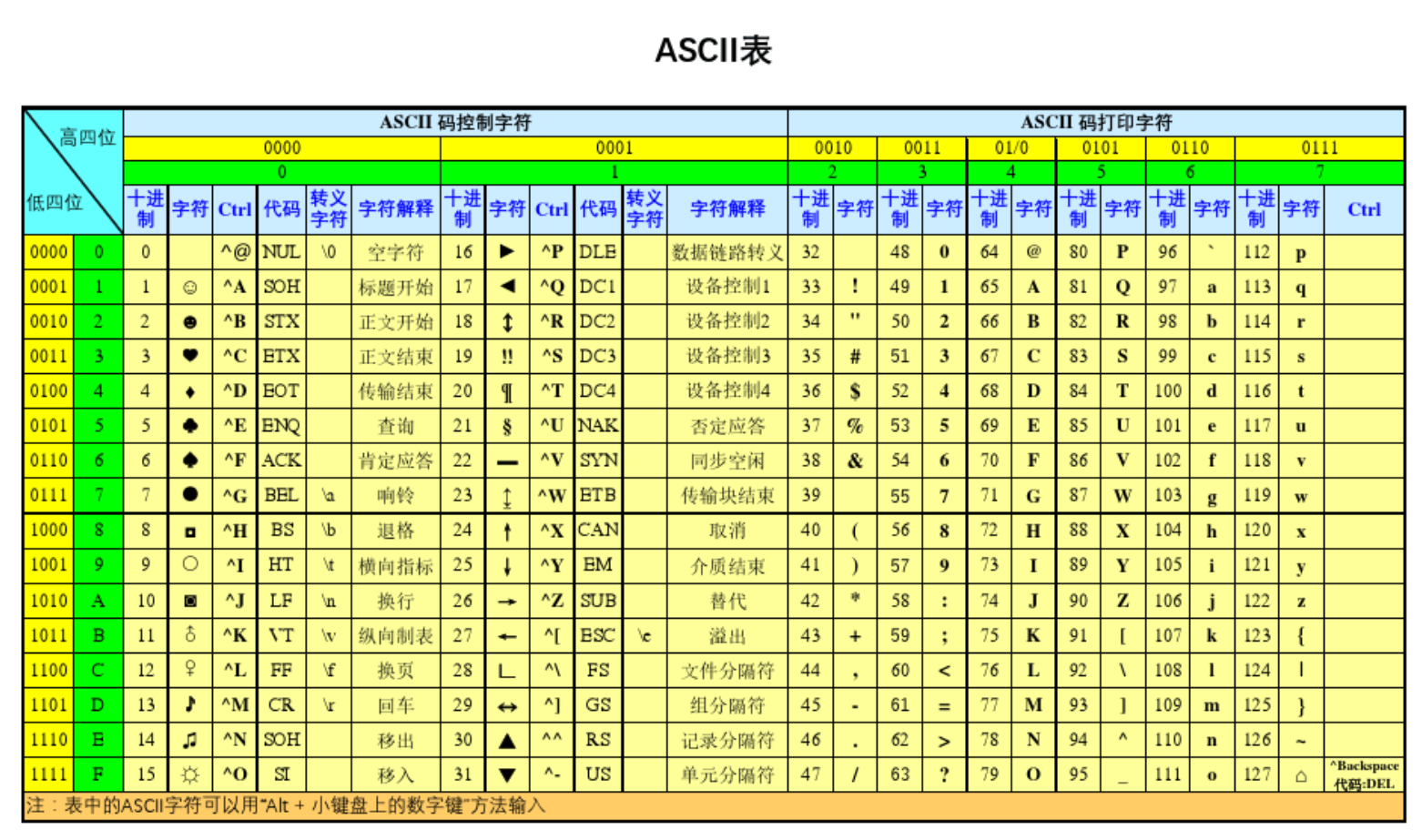
- The total number of English characters and symbols shall not exceed 127
- The eight bit representation is used to discover new languages later
Character correspondence
-
A-Z: 65-90
-
a-z: 97-122
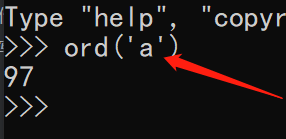
In python, use the ord () method to view the number (decimal) corresponding to the character
2. Chinese character coding - GBK
In order to enable the computer to recognize Chinese, another set of codes, GBK, was invented
The GBK code table records the corresponding relationship between Chinese and English and numbers.
- GBK uses one byte for English
- GBK uses two or more bytes for Chinese
Note · for example, the common encoding method for simplified Chinese is GB2312 , two bytes are used to represent a Chinese character, so theoretically, it can represent 256 x 256 = 65536 symbols at most. Therefore, two bytes are not enough to represent all Chinese. In case of rare words, more bits may be needed to represent them.
3. Japanese code - Shift_JIS
In order for computers to recognize Japanese, it is also necessary to invent a set of coding tables,
Shift_ The JIS code table records the correspondence between Japanese and English and numbers.
4. Korean code - EUC-KR
In order to enable the computer to recognize Korean, it is necessary to invent a set of coding table,
EUC_ The Kr code table records the corresponding relationship between Korean and English and numbers.
5. Universal code - Unicode
Introduction to Unicode:
Unicode is produced to solve the limitations of the traditional character coding scheme. It sets a unified and unique character for each character in each language Binary coding To meet the requirements of cross language and cross platform text conversion and processing.
Unicode It is an international organization that can accommodate all characters and symbols in the world Character encoding Programme. Unicode maps these characters with the number 0-0x10FFFF, which can hold up to 1114112 characters, or 1114112 code points. A code point is a number that can be assigned to a character. UTF-8,UTF-16,UTF-32 Both are coding schemes that convert numbers to program data, and use two or more characters to record the corresponding relationship between characters and numbers.
UTF-8
UTF-8 is an optimized version of the universal code, which stores English in one byte and Chinese in three bytes or more. The default encoding we use is UTF-8.
Character coding practice
1. How to solve the situation of garbled code
#The file was encoded according to what standard and decoded according to what standard when it was opened
2. Coding differences caused by different versions of python interpreter
- Since Python 2. X was invented earlier than Unicode, ASCII is used internally by default
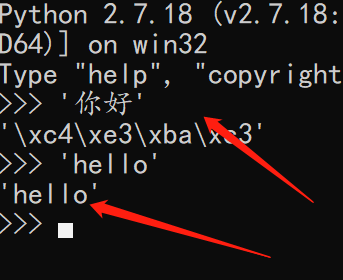
3. When programming with Python 2. X, you must add a file header. If you define a string, you need to add a small u before the string.
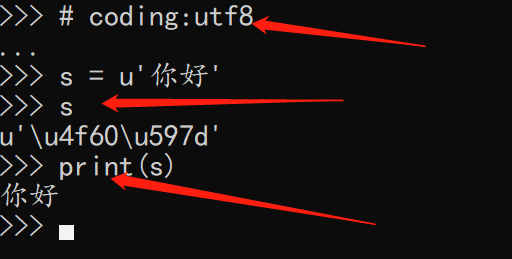
4. Python 3. X uses utf-8 internally
5. How to define a file header template in pycham (python2 version is available)
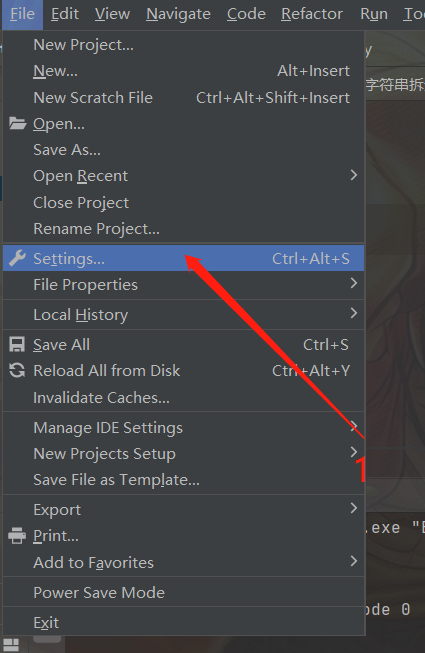
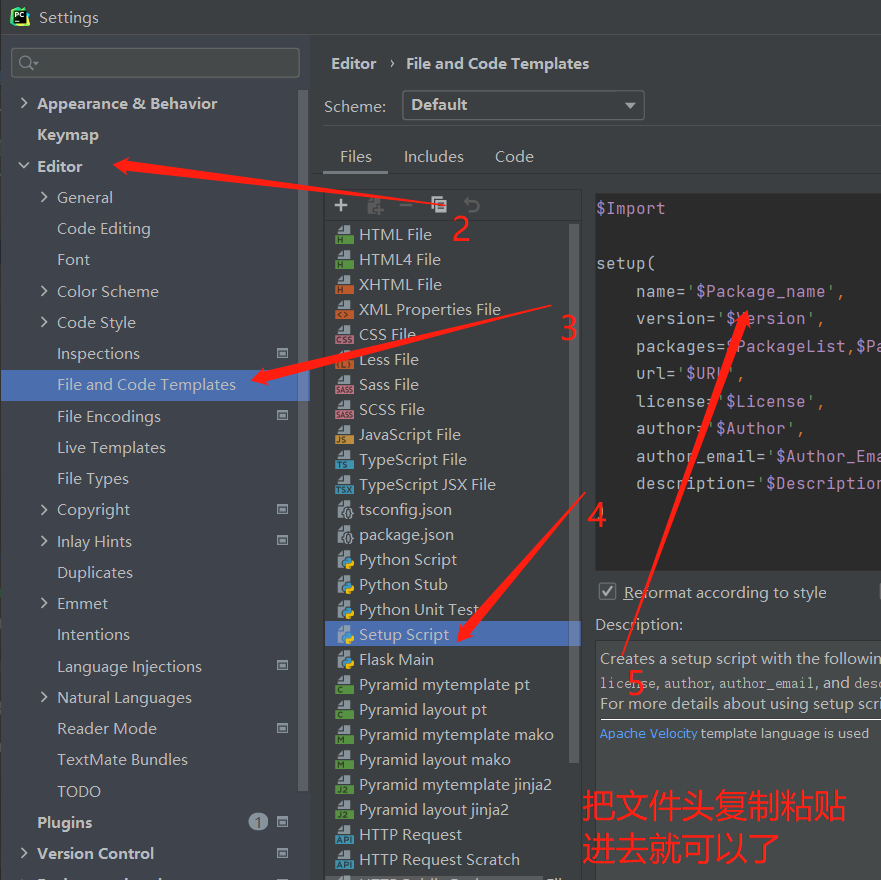
Steps: File > > Settings > > editor > > file and code templates > > Python script
Code drill
- Encoding and decoding process
- encode: convert human readable characters into numbers
- decode - Decoding: converting numbers into characters that humans can read
Examples are as follows:
s = 'I want to keep learning python!'
#code
res = s.encode('utf8')
print(res,type(res))
#decode
res1 = res.decode('utf8')
print(res1,type(res1))
#result
b'\xe6\x88\x91\xe8\xa6\x81\xe5\x9d\x9a\xe6\x8c\x81\xe5\xad\xa6python\xef\xbc\x81' <class 'bytes'>
I want to keep learning python! <class 'str'>
File operation
What is a file?
- The file is the 'interface' that the operating system exposes to the user to operate the hard disk.
How to manipulate files:
- Open file: open
- Close file: close()
route:
- Absolute path
- Relative path
How to cancel the function of special characters:
- Add 'r' before the path
- Add another one before \
Operations on files include: read and write
- r: The path exists read-only mode and cannot be modified. If the path does not exist, an error will be reported directly
- w: If the path exists, the contents of the file will be cleared every time it is opened. If the path does not exist, it will be created automatically
- a: The existence of the path moves the file pointer directly to the end of the file and creates an empty document when the file does not exist
Examples are as follows:
# 1. Open the a.txt file in the current path in read-only and utf8 encoding mode
#First, create a.txt file in the current path
res = open('a.txt',mode='r',encoding='utf8')
# View content
print(res.read())
# The file must be closed after operation to free up resources
res.close()
res1 = open(r'E:\python item\Old_BoyClass_second\a.txt',mode='r',encoding='utf8')
# Add r before the absolute path to cancel the original function of \ a
print(res1.read())
# The file must be closed after operation to free up resources
res1.close()
#As a result, the upper and lower operation results are the same
I want to keep learning python!
I want to keep learning python!
#2. Open the a.txt file in the current path in write and utf8 encoding mode
res = open('a.txt', mode='w', encoding='utf8')
# Input hello content, clear the previous, I want to insist on learning python!
res.write('hello')
# The file must be closed after operation to free up resources
res.close()
#The results are stored in a.txt file
hello
#3. Open the a.txt file in the current path in the add content, write function and utf8 encoding mode
res = open('a.txt', mode='a', encoding='utf8')
# Input hello content, clear the previous, I want to insist on learning python!
res.write(' world\n')
res.write('python\n')
# The file must be closed after operation to free up resources
res.close()
#As a result, world and python characters are appended to the a.txt file
world
python
with context management
It solves the problem of always forgetting to close the file. After executing the code with the keyword, the file will be closed automatically to release resources
- with syntax format:
with open('File name ',' r/w ') as f:
f. Read / F. write
-
with can also open multiple files at the same time:
with open('filename 1 ',' r/w ') as f1, open('filename 2') as f2:
pass
Examples are as follows:
# with keyword context management
# Opening a nonexistent file is equivalent to creating
with open('b.txt', mode='w') as f1:
f1.write('hello world!')
# Opening multiple files is equivalent to creating
with open('c.txt',mode='w') as f2,open('d.txt',mode='w') as f3:
#Store Hammer and python in c.txt file and d.txt file respectively
f2.write("Hammer")
f3.write('python')
#result
hello world!
Hammer
python
 Support reprint, indicate the source and continue to update~~~
Support reprint, indicate the source and continue to update~~~
Character encoding, file operations have this article!