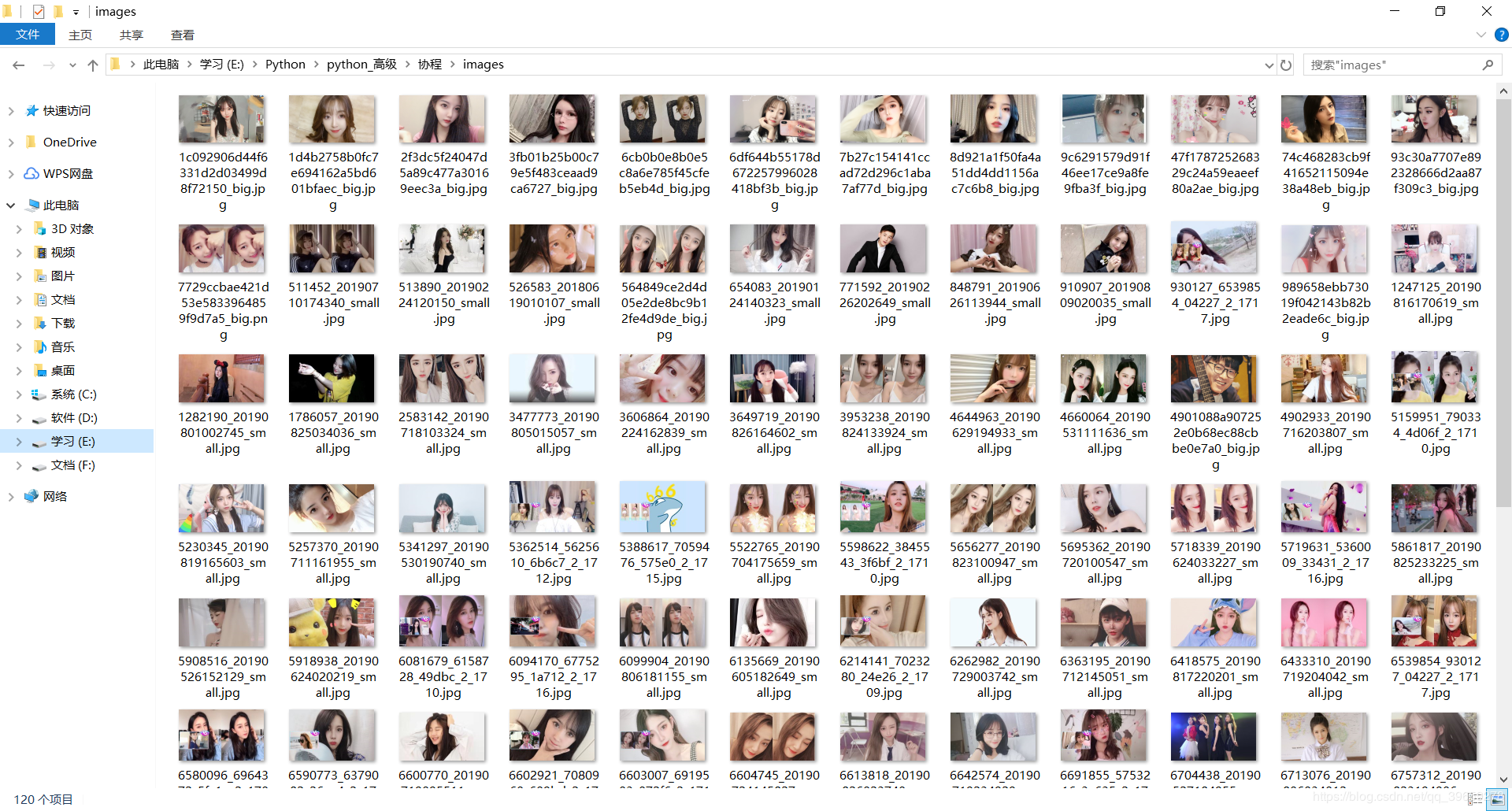
Links to the original text: https://www.cnblogs.com/lxy0/p/11413976.html
Analyse the Web Site to Find the Need Web Site
Use browser browser to press F12 to open developer tools, and then open the page of the fight fish classification page.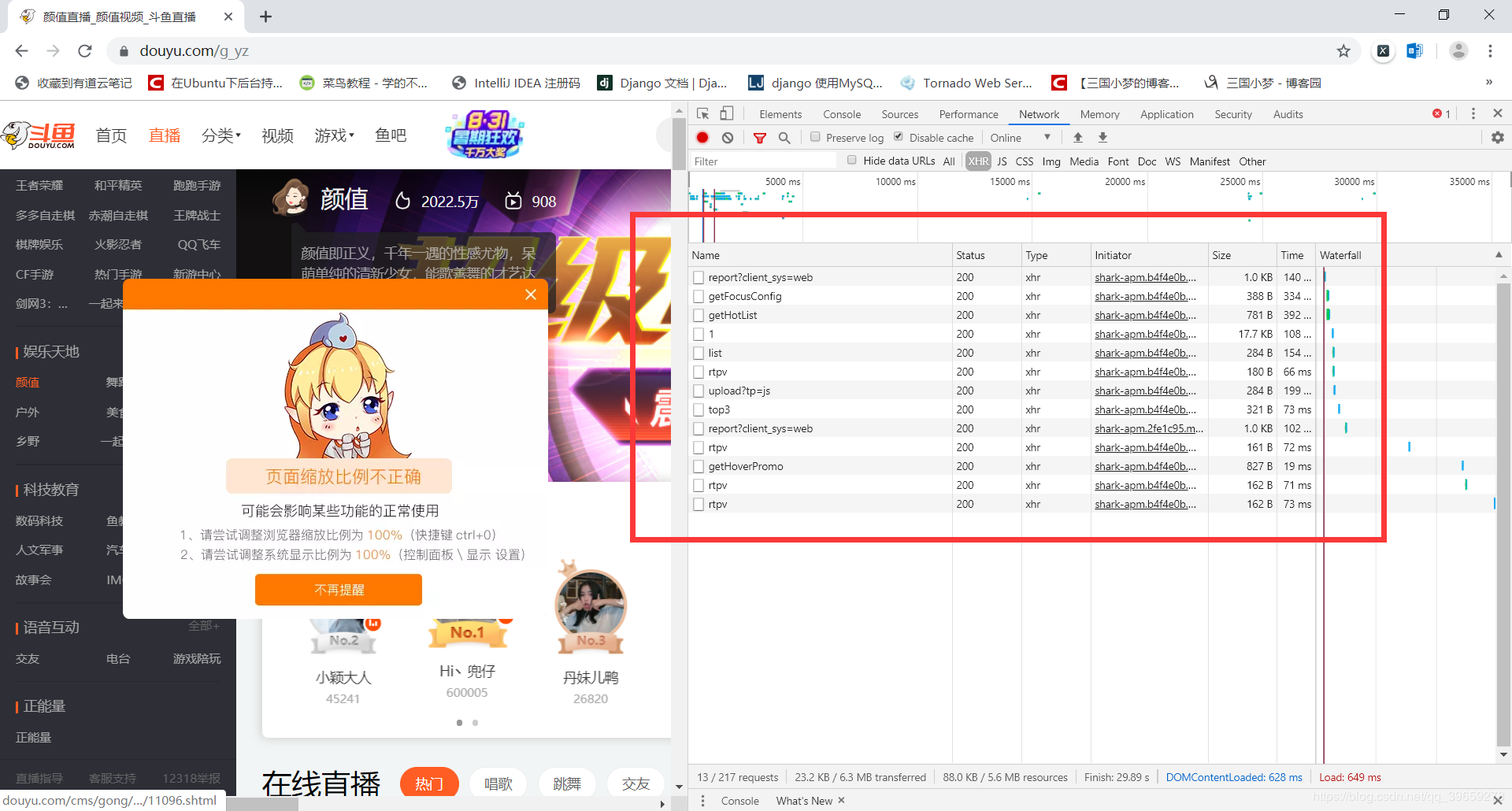
In the request, it is finally found that it is loaded with ajax in the form of json, as shown in the figure: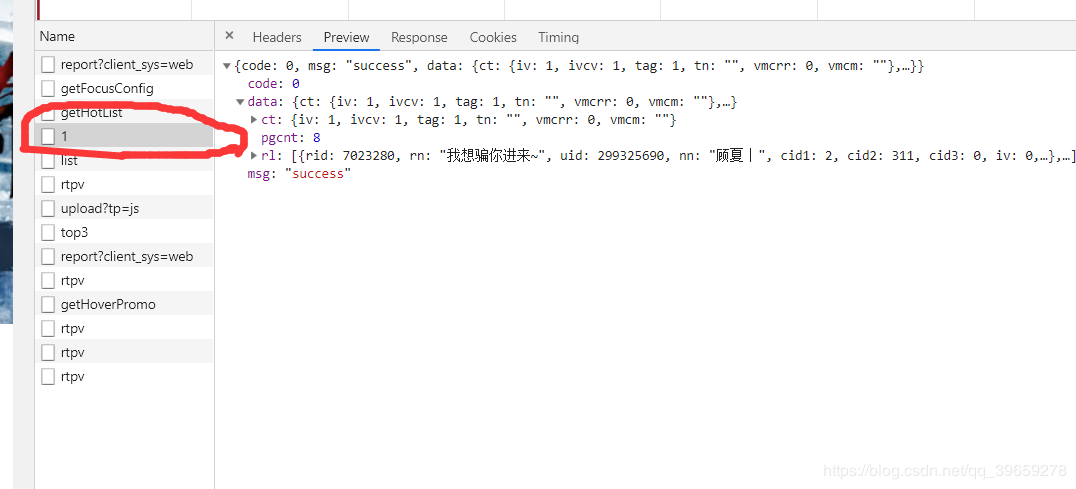
The enclosed part is the data we need, and then copy its website at https://www.douyu.com/gapi/rknc/directory/yzRec/1, crawling only the first page for learning purposes (reducing server pressure). Then put the website in the browser to test whether it is accessible. As shown in the picture: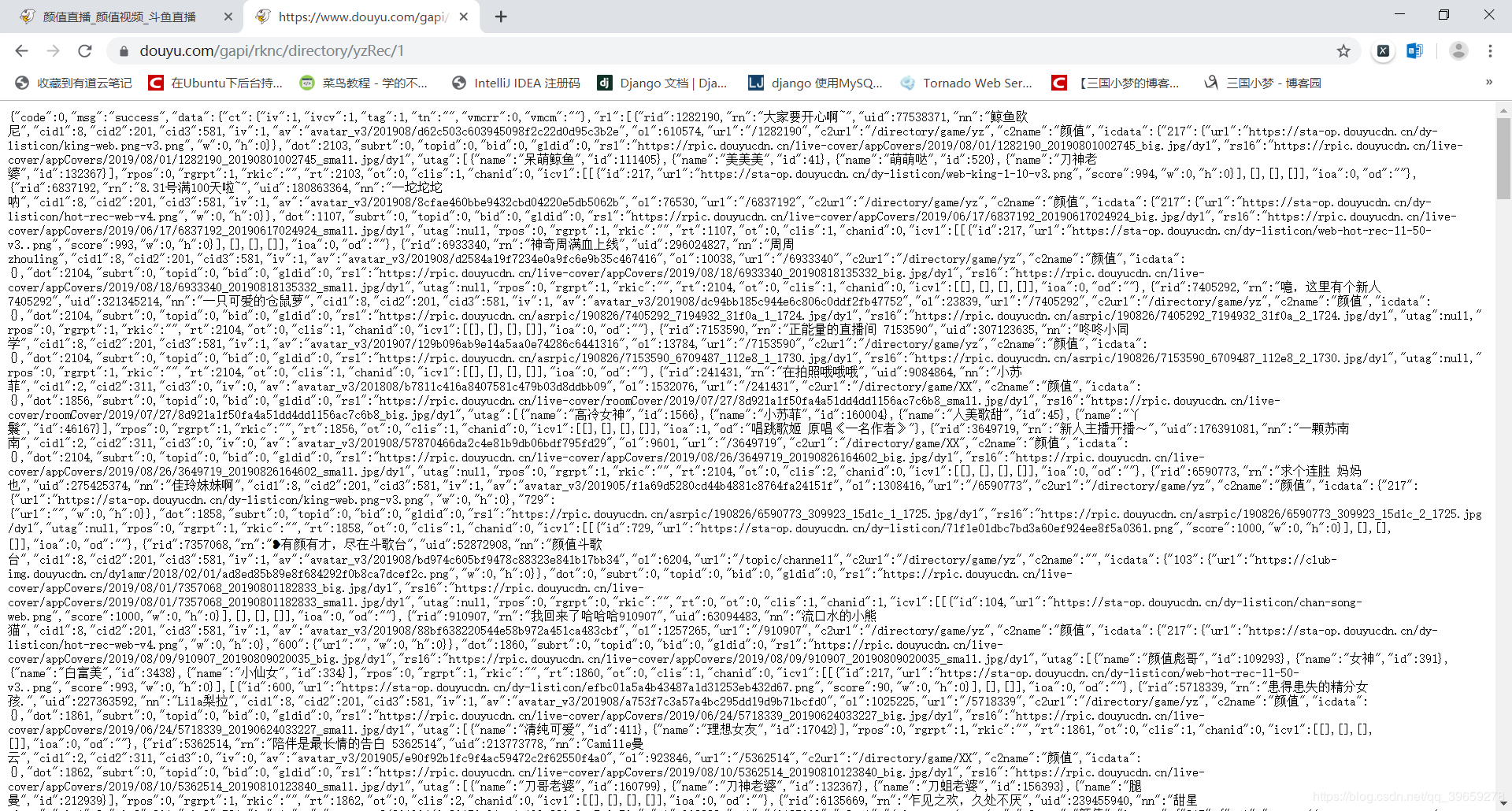
The results were normal.
Analyze json data and extract image links
{
"rid": 1282190,
"rn": "Let's be happy.~",
"uid": 77538371,
"nn": "Whale",
"cid1": 8,
"cid2": 201,
"cid3": 581,
"iv": 1,
"av": "avatar_v3/201908/d62c503c603945098f2c22d0d95c3b2e",
"ol": 610574,
"url": "/1282190",
"c2url": "/directory/game/yz",
"c2name": "Level of appearance",
"icdata": {
"217": {
"url": "https://sta-op.douyucdn.cn/dy-listicon/king-web.png-v3.png",
"w": 0,
"h": 0
}
},
"dot": 2103,
"subrt": 0,
"topid": 0,
"bid": 0,
"gldid": 0,
"rs1": "https://rpic.douyucdn.cn/live-cover/appCovers/2019/08/01/1282190_20190801002745_big.jpg/dy1",
"rs16": "https://rpic.douyucdn.cn/live-cover/appCovers/2019/08/01/1282190_20190801002745_small.jpg/dy1",
"utag": [
{
"name": "Dai Meng",
"id": 111405
},
{
"name": "America, America and America",
"id": 41
},
{
"name": "Adorable",
"id": 520
},
{
"name": "Sword wife",
"id": 132367
}
],
"rpos": 0,
"rgrpt": 1,
"rkic": "",
"rt": 2103,
"ot": 0,
"clis": 1,
"chanid": 0,
"icv1": [
[
{
"id": 217,
"url": "https://sta-op.douyucdn.cn/dy-listicon/web-king-1-10-v3.png",
"score": 994,
"w": 0,
"h": 0
}
],
[
],
[
],
[
]
],
"ioa": 0,
"od": ""
}
The test found that rs16 is a picture of the room. If the last / dy1 of the link is removed, the picture will be a big picture, and I feel happy.
code implementation
import gevent
import json
from urllib import request
from gevent import monkey
'''
//What problems do you not understand? Python Learning Exchange Group: 821460695 to meet your needs, information has been uploaded group files, you can download!
'''
# Using gevent patches, time-consuming operations are automatically replaced by modules provided by gevent
monkey.patch_all()
# Catalogue of Picture Storage
ROOT = "./images/"
# Setting the request header is the first step to prevent anti-crawlers
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36 "
}
def download(img_src):
# Remove the last / dy1 of each link
img_src: str = img_src.replace("/dy1", "")
# Extraction of picture names
file_name: str = img_src.split("/")[-1]
response = request.urlopen(request.Request(img_src, headers=header))
# Save it locally
with open(ROOT + file_name, "wb") as f:
f.write(response.read())
print(file_name, "Download completed!")
if __name__ == '__main__':
req = request.Request("https://www.douyu.com/gapi/rknc/directory/yzRec/1", headers=header)
# Converting json data into a dictionary in python
json_obj = json.loads(request.urlopen(req).read().decode("utf-8"))
tasks = []
for src in json_obj["data"]["rl"]:
tasks.append(gevent.spawn(download, src["rs16"]))
# Start downloading pictures
gevent.joinall(tasks)
Result