On Synergetic process
a collaboration is simply a more lightweight thread that is not managed by the operating system kernel and is completely controlled by the program (executed in user mode). A co program is interruptible within a subroutine, and then switches to other subroutines, returning when appropriate to continue execution.
Advantages of cooperation process? (the cooperation program has its own register context and stack. When scheduling the switch, the register context and stack are saved to other places. When switching back, the previously saved register context and stack are restored. The direct operation stack basically has no kernel switching overhead and can access global variables without locking, so the context is very fast.)
The use of yield in the process
1. yield in a collaboration usually appears to the right of the expression:
x = yield data
If there is no expression on the right side of yield, the default output value is None. Now there is an expression on the right side, so data is returned.
2. The coordinator can receive data from the call usage, call to provide data to the coordinator through send(x), and the send method contains the next method, so the program will continue to execute.
3. A process can interrupt execution to execute another process.
Classic example
code:
def hello():
data = "mima"
while True:
x = yield data
print(x)
a = hello()
next(a)
data = a.send("hello")
print(data)Code details:
When the program starts executing, the function hello does not actually execute, but returns a generator to a.
When the next() method is called, the hello function starts to execute, executes the print method, and continues to enter the while loop;
When the program encounters the yield keyword, the program interrupts again. At this time, when it executes to a.send("hello"), the program will continue to execute downward from the yield keyword, and then enter the while loop again. When it encounters the yield keyword again, the program interrupts again;
additional
There are four states in the running process of the cooperation process:
- Gen? Create: wait for execution to begin
- Gen? Running: interpreter executing
- Gen? Suspended: pause at yield expression
- Gen? Closed: end of execution
Producer consumer model (process)
import time
def consumer():
r = ""
while True:
res = yield r
if not res:
print("Starting.....")
return
print("[CONSUMER] Consuming %s...." %res)
time.sleep(1)
r = "200 OK"
def produce(c):
next(c)
n = 0
while n<6:
n+=1
print("[PRODUCER] Producing %s ...."%n)
r = c.send(n)
print("[CONSUMER] Consumer return: %s ...."%r)
c.close()
c = consumer()
produce(c) Code analysis:
- Call next(c) to start the generator;
- Once a consumer produces something, it switches to consumer for execution through c.send;
- consumer obtains the message through the yield keyword and executes the result through the yield keyword;
- The producer obtains the result processed by the consumer and continues to generate the next message;
- After jumping out of the cycle, the producer does not produce, and closes the consumer through close, and the whole process ends;
gevent third party library process support
Principle: gevent is based on the Python Network Library of the cooperation program. When a greenlet encounters IO operation (access to the network), it will automatically switch to other greenlets and wait until IO operation is completed, and then switch back to continue execution when appropriate. In other words, greenlet ensures that greenlet is running, rather than waiting for IO operations, by helping us automatically switch processes.
Classic code
Since the IO operation is automatically completed during the switch, gevent needs to modify the Python built-in library. Here you can put monkey patch (used to dynamically modify the existing code at run time, without the original code) monkey.patch_all
#!/usr/bin/python2
# coding=utf8
from gevent import monkey
monkey.patch_all()
import gevent
import requests
def handle_html(url):
print("Starting %s. . . . " % url)
response = requests.get(url)
code = response.status_code
print("%s: %s" % (url, str(code)))
if __name__ == "__main__":
urls = ["https://www.baidu.com", "https://www.douban.com", "https://www.qq.com"]
jobs = [ gevent.spawn(handle_html, url) for url in urls ]
gevent.joinall(jobs)Operation result:
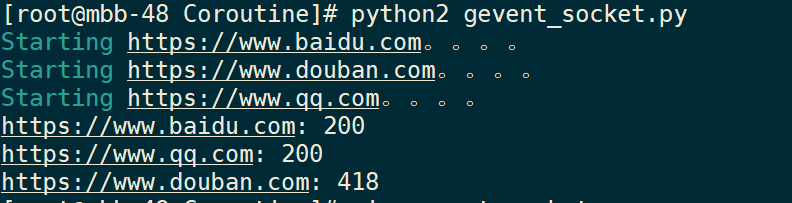
Results: three network connections were executed simultaneously, but the order of termination was different.
asyncio built in library collaboration support
Principle: the programming model of asyncio is a message loop. Get an application of event loop directly from asyncio module, and then put the required cooperation into the event loop to execute, to realize asynchronous IO.
Classic code:
import asyncio
import threading
async def hello():
print("hello, world: %s"%threading.currentThread())
await asyncio.sleep(1) #
print('hello, man %s'%threading.currentThread())
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait([hello(), hello()]))
loop.close()Code resolution:
- First get an EventLoop
- Then put the hello process into the EventLoop, run the EventLoop, and it will run until the future is completed
- In the hello process, await asyncio.sleep(1) simulates IO operations that take 1 second. During this period, the main thread does not wait, but executes other threads in the EventLoop to achieve concurrent execution.
Code result:
Asynchronous crawler instance:
#!/usr/bin/python3
import aiohttp
import asyncio
async def fetch(url, session):
print("starting: %s" % url)
async with session.get(url) as response:
print("%s : %s" % (url,response.status))
return await response.read()
async def run():
urls = ["https://www.baidu.com", "https://www.douban.com", "http://www.mi.com"]
tasks = []
async with aiohttp.ClientSession() as session:
tasks = [asyncio.ensure_future(fetch(url, session)) for url in urls] # Create task
response = await asyncio.gather(*tasks) # Concurrent task execution
for body in response:
print(len(response))
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
loop.close()Code resolution:
- Create an event loop, and then put the task into the time loop;
- In the run() method, the main task is to create a task, execute the task concurrently, and return the content of the web page read;
- The fetch() method sends the specified request through aiohttp and returns the waiting object;
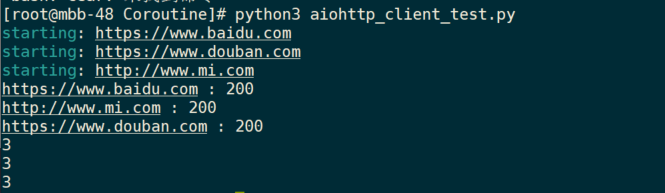
(the ending output URL is different from the URL in the list, proving asynchronous I/O operation in the process)
About aiohttp
Asyncio implements TCP, UDP, SSL and other protocols. aiohttp is an HTTP framework based on asyncio, which can be used to write a micro HTTP server.
code:
from aiohttp import web
async def index(request):
await asyncio.sleep(0.5)
print(request.path)
return web.Response(body='<h1> Hello, World</h1>')
async def hello(request):
await asyncio.sleep(0.5)
text = '<h1>hello, %s</h1>'%request.match_info['name']
print(request.path)
return web.Response(body=text.encode('utf-8'))
async def init(loop):
app = web.Application(loop=loop)
app.router.add_route("GET", "/" , index)
app.router.add_route("GET","/hello/{name}", hello)
srv = await loop.create_server(app.make_handler(), '127.0.0.1', 8000)
print("Server started at http://127.0.0.0.1:8000....")
return srv
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(init(loop))
loop.run_forever()Code resolution:
- Create an event loop and pass it into the init process;
- Create an Application instance, and then add a route to process the specified request;
- Create TCP service through loop, and finally start the event cycle;
Reference link
https://www.liaoxuefeng.com/wiki/1016959663602400/1017985577429536
https://docs.aiohttp.org/en/stable/web_quickstart.html
https://docs.python.org/zh-cn/3.7/library/asyncio-task.html