This article is reproduced from: https://blog.csdn.net/qq_52907353/article/details/112391518#commentBox
What I want to write today is to climb Baidu pictures
1, Analysis process
1. First, open Baidu, then search for keywords and click pictures
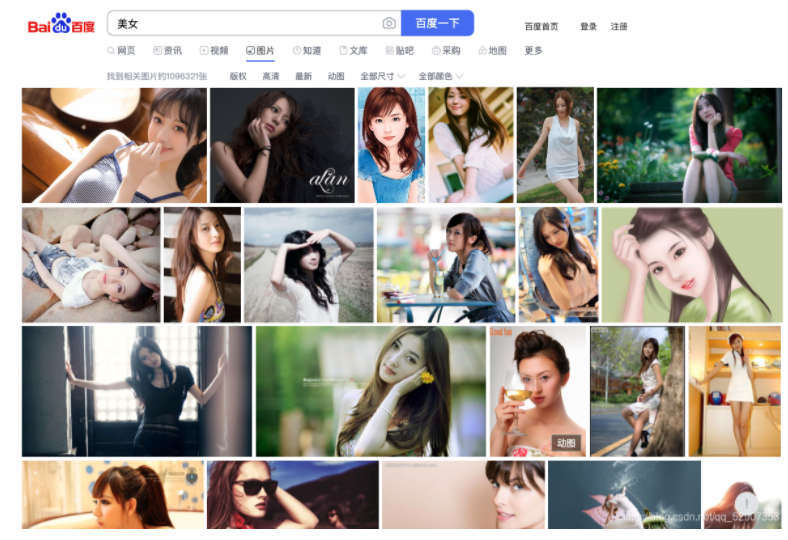
2. In the process of sliding down with the mouse wheel, it is found that the picture is dynamically loaded, which means that this is an ajax request.
3. Select the XHR option
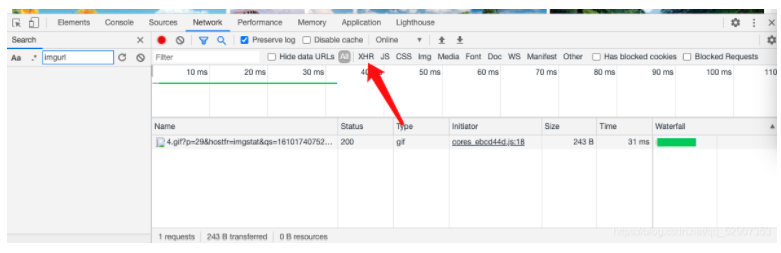
4. Then drag the mouse wheel down and we will find a packet.
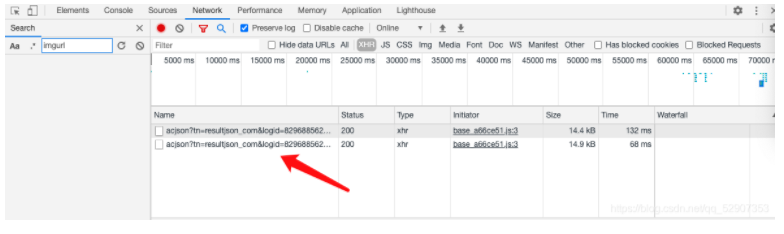
5. Copy the URL request of this packet
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8222346496549682679&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%BE%8E%E5%A5%B3&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%E7%BE%8E%E5%A5%B3&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=girl&pn=30&rn=30&gsm=1e&1610176483429=
6. Click this URL to see the parameters it carries
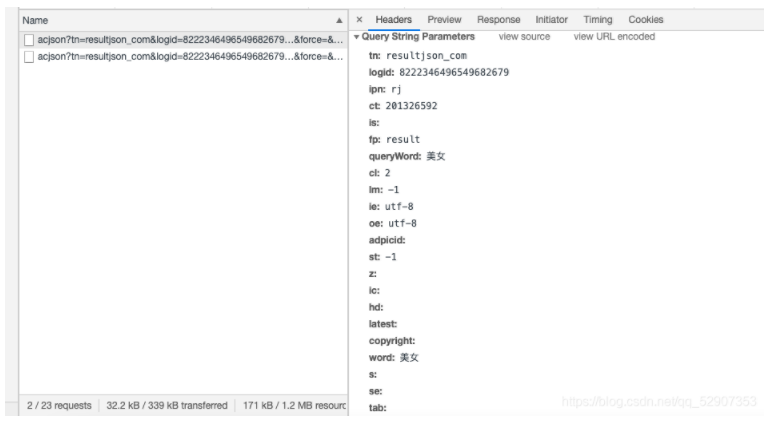
Then copy it, too
Start writing related code
2, Write code
1. First introduce the modules we need
import requests
2. Start coding
#Conduct UA camouflage
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': '8846269338939606587',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': 'beauty',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z':'' ,
'ic':'' ,
'hd': '',
'latest': '',
'copyright': '',
'word': 'beauty',
's':'' ,
'se':'' ,
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': '1',
'rn': '30',
'gsm': '1e',
}
#Convert encoding form to utf-8
page_text = requests.get(url=url,headers=header,params=param)
page_text.encoding = 'utf-8'
page_text = page_text.text
print(page_text)
At this step, let's visit it first to see if we can get the data returned by the page
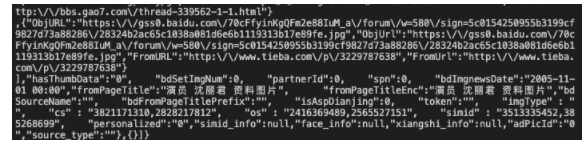
We successfully obtained the returned data
After that, we return to the web page to view the packet and its returned data
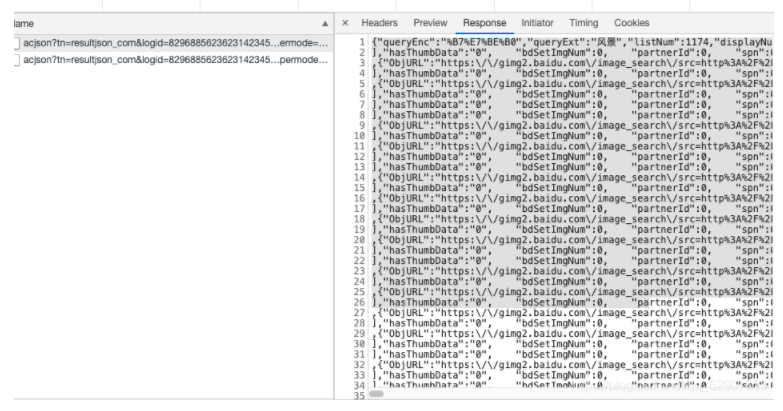
Then put it into the json online parsing tool and find the address corresponding to the image
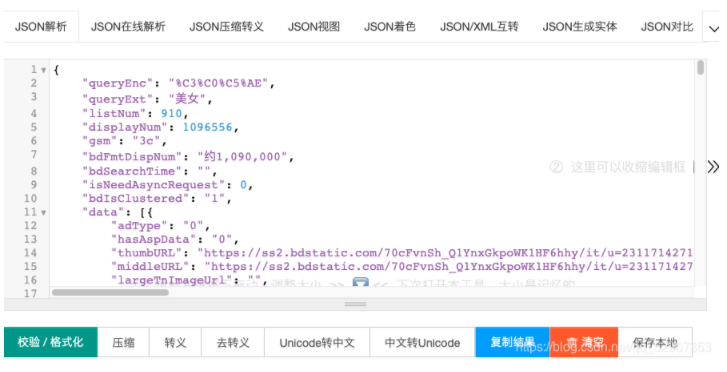
Then continue writing code
Convert the returned data into json format, and find that all the data is stored in a dictionary, and the address of the picture is also in a dictionary
Then take out the link address
page_text = page_text.json()
#First, take out the dictionary where all links are located and store it in a list
info_list = page_text['data']
#Since the last dictionary retrieved in this way is empty, the last element in the list is deleted
del info_list[-1]
#Define a list for storing picture addresses
img_path_list = []
for info in info_list:
img_path_list.append(info['thumbURL'])
#Then take out all the picture addresses and download them
#n will be the name of the picture
n = 0
for img_path in img_path_list:
img_data = requests.get(url=img_path,headers=header).content
img_path = './' + str(n) + '.jpg'
with open(img_path,'wb') as fp:
fp.write(img_data)
n += 1
After completing these, we also want to download multiple pages of Baidu pictures. After analysis, I found that in the parameters we submitted, pn represents the first few pictures to load. Along this idea, we can give the above code a big cycle, that is, the first download starts from the first one, Download 30 pictures, and the second download starts from the 31st one.
OK! The idea has been clear, and start to modify the above code
import requests
from lxml import etree
page = input('Please enter how many pages to crawl:')
page = int(page) + 1
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
n = 0
pn = 1
#pn is obtained from the first few pictures. When Baidu pictures decline, 30 are displayed at one time by default
for m in range(1,page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': '8846269338939606587',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': 'beauty',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z':'' ,
'ic':'' ,
'hd': '',
'latest': '',
'copyright': '',
'word': 'beauty',
's':'' ,
'se':'' ,
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': pn,#Which picture to start with
'rn': '30',
'gsm': '1e',
}
page_text = requests.get(url=url,headers=header,params=param)
page_text.encoding = 'utf-8'
page_text = page_text.json()
info_list = page_text['data']
del info_list[-1]
img_path_list = []
for i in info_list:
img_path_list.append(i['thumbURL'])
for img_path in img_path_list:
img_data = requests.get(url=img_path,headers=header).content
img_path = './' + str(n) + '.jpg'
with open(img_path,'wb') as fp:
fp.write(img_data)
n = n + 1
pn += 29