requests
Crawl the search result page corresponding to the specified term of Sogou (simple web page collector)
UA: user agent (identity of request carrier)
UA camouflage: the server of the portal website will detect the carrier identity of the corresponding request. If it is detected that the carrier identity of the request is a browser, it indicates that the request is a normal request. If the carrier identity of the detected request is not based on a browser, it indicates that the request is an abnormal request (crawler), and the server is likely to reject the request.
Therefore, normal crawling will fail, so we need to use UA camouflage.
UA camouflage
UA camouflage: disguise the identity of the request carrier corresponding to the crawler as a browser.
Note: the browser identity can be checked by right clicking the browser,
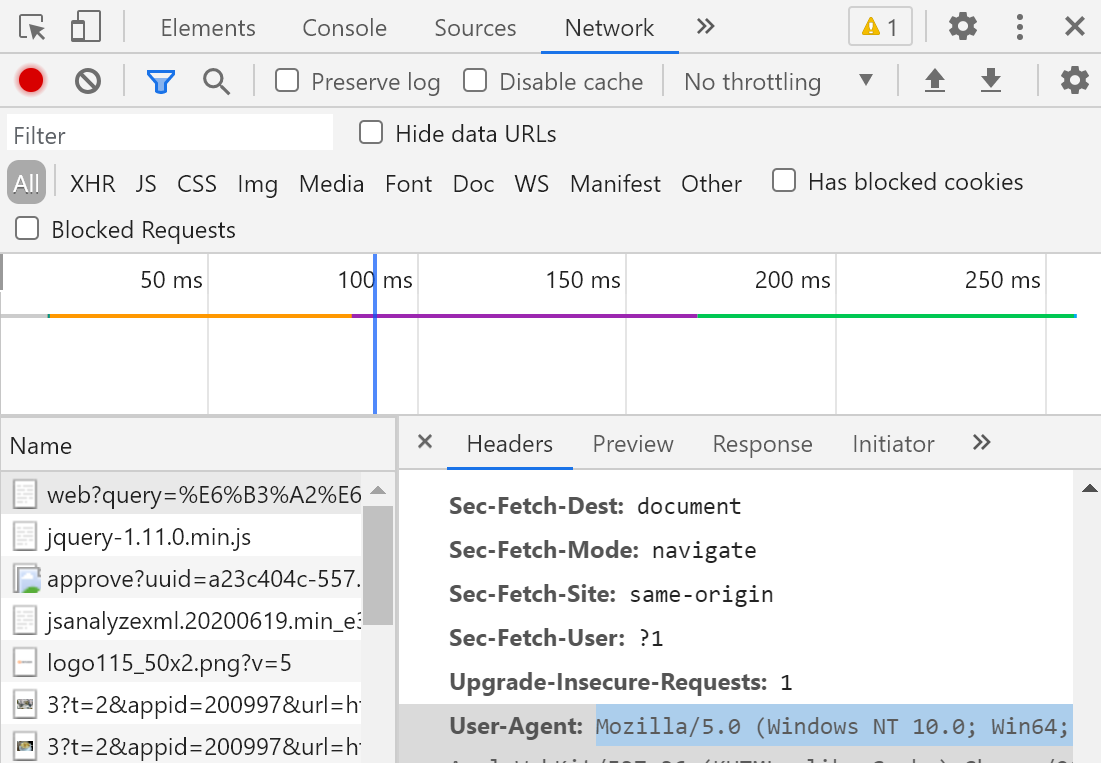
Locate the user agent.
Finally, we can write the code to crawl the specified data
import requests
#UA camouflage: encapsulate the corresponding user agent into a dictionary
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url='https://www.sogou.com/web?'
#Processing parameters carried by url: encapsulated in dictionary
kw = input('enter a word:')
param = {
'query':kw
}
response = requests.get(url=url,params=param,headers=headers)
page_text = response.text
fileName = kw+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName,'Saved successfully')
result

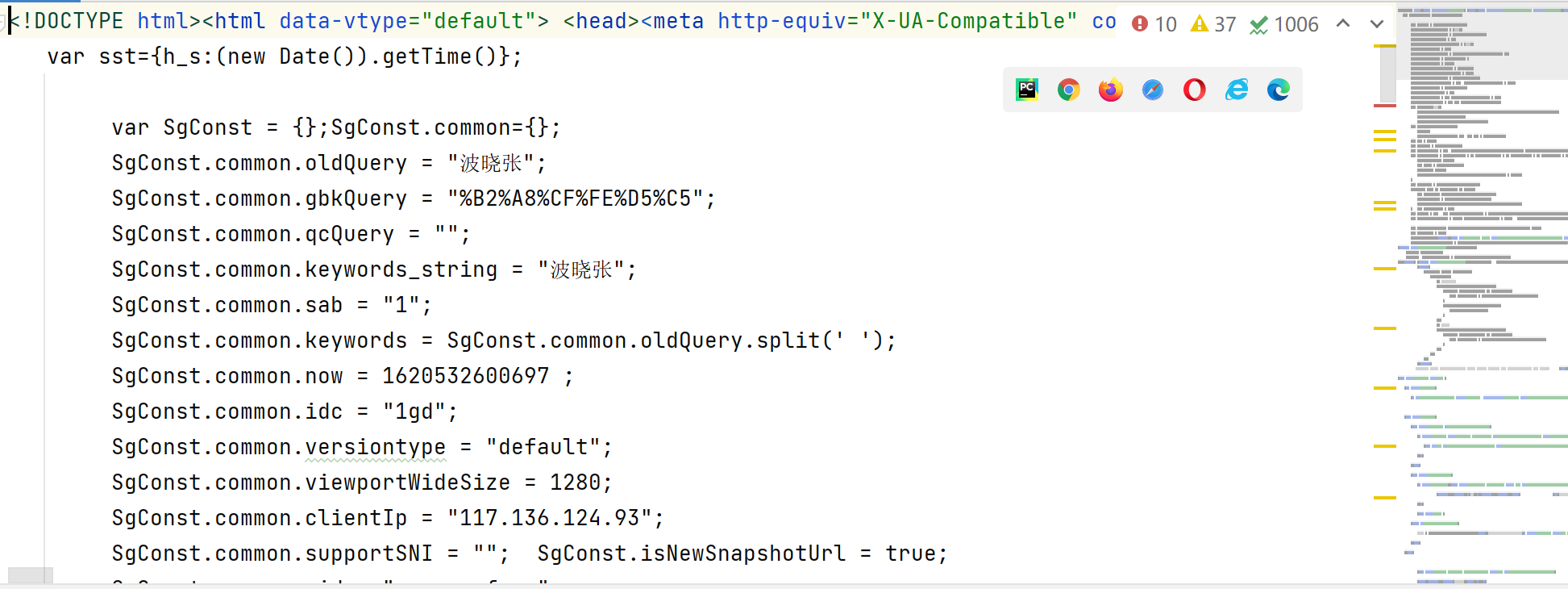
Baidu Translate
import json
import requests
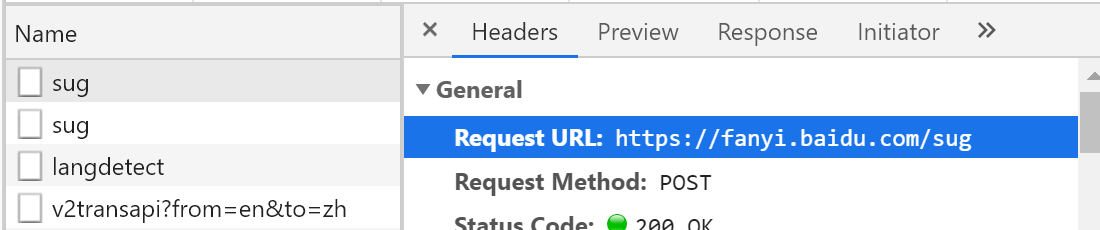
post_url='https://fanyi.baidu.com/sug'
#Conduct UA camouflage
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
#post request parameter processing (consistent with get request)
word = input('entry a word:')
data = {
'kw':word
}
#Send request
response = requests.post(url=post_url,data=data,headers=headers)
#Get response data: the json() method returns an object (json() can only be used if the response data is confirmed to be of json type)
dic_obc = response.json()
#Persistent storage
fileName = word+'.json'
fp = open(fileName,'w',encoding='utf-8')
json.dump(dic_obc,fp=fp,ensure_ascii=False)
print('end')

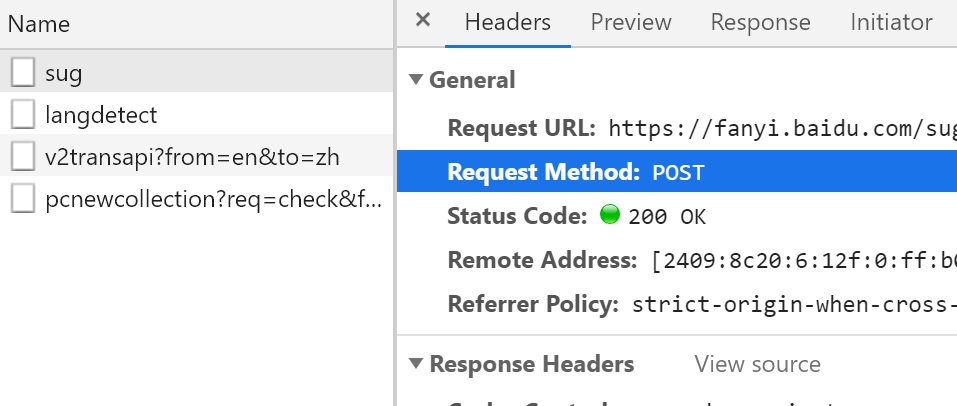
View url
View data type
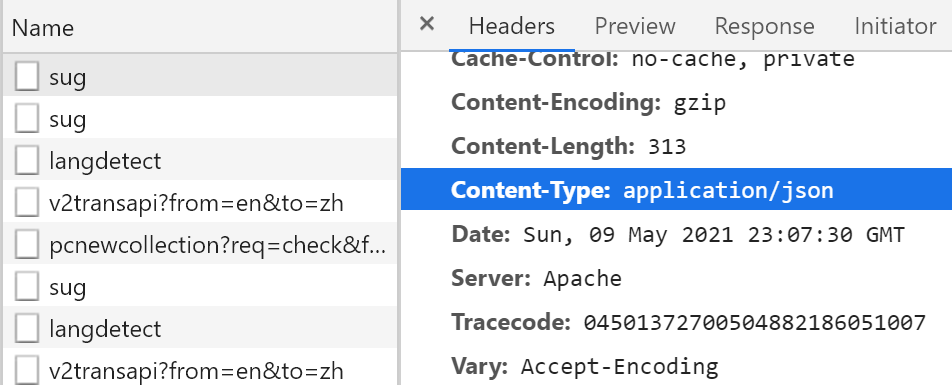
View parameter processing method
Crawling Douban film ranking
import json
import requests
url = 'https://movie.douban.com/j/chart/top_list'
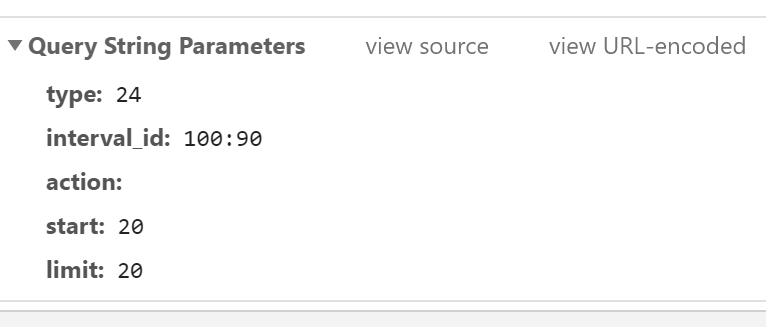
param = {
'type': '24',
'interval_id': '100:90',
'action':'',
'start': '0',#start indicates which movie to get from the library
'limit': '20',#limit indicates how many movies you can get at a time
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
reponse = requests.get(url=url,headers=headers,params=param)
list_data = reponse.json()
fp = open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
print('over')

Copy the data in the figure above to the json formatting tool BEJSON
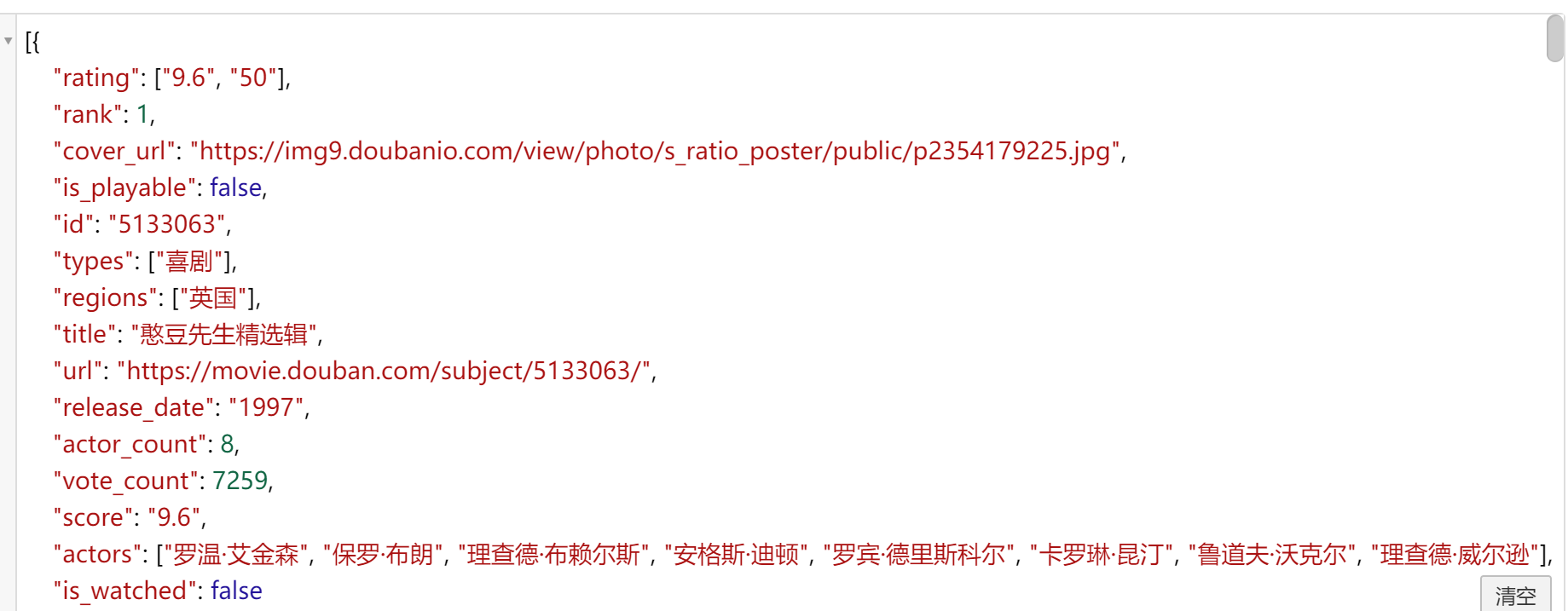
The first one is "Mr. Bean collection", which is the same as that in Douban film
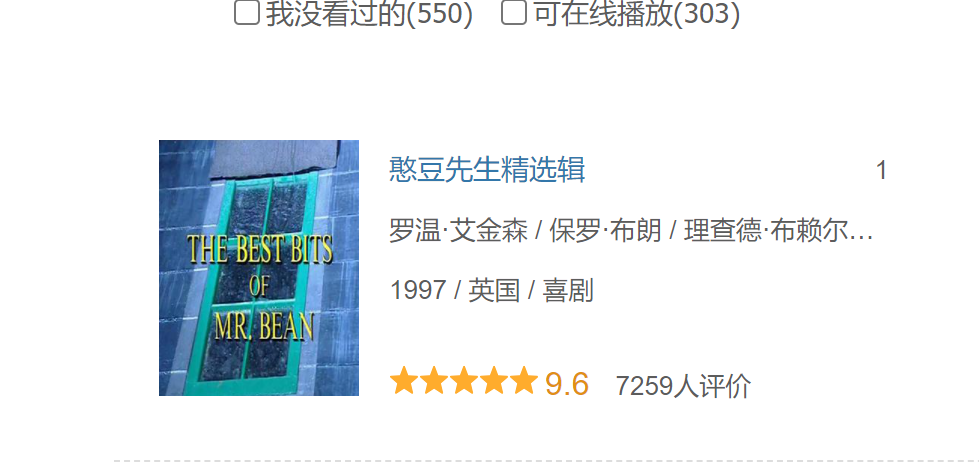
There are no errors.
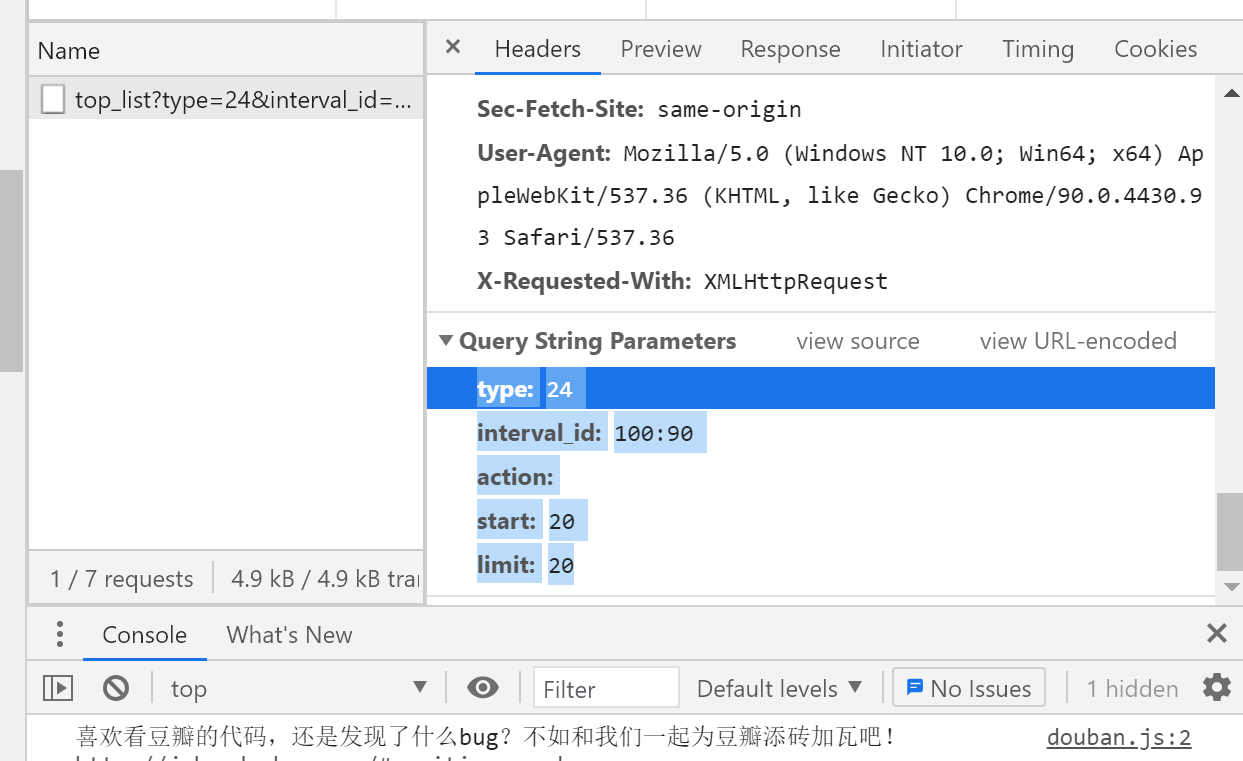
Location of parameters
Climb to the relevant data of the State Drug Administration Based on the cosmetics production license of the people's Republic of China
The corresponding enterprise information data in the home page is dynamically requested through ajax.
By observing the details page, it is found that the domain name of the url is the same, only the parameters (id) carried are different, and the id value can be obtained from the json string requested by the corresponding ajax on the home page.
The enterprise data of the details page is also dynamically loaded. After observation, it is found that the URLs of all post requests are the same, only the parameter IDs are different.
import json
import requests
#Get the id values of different enterprises in batch
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
#Key value of parameter
data = {
'on': 'true',
'page': '1',
'pageSize': '15',
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':'',
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
id_list = []#Add enterprise id
all_data_list = []#Store all business detail data
ison_ids = requests.post(url=url,data=data,headers=headers).json()
for dic in ison_ids['list']:
id_list.append(dic['ID'])
#Get enterprise details
post_url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
data ={
'id':id
}
detail_json = requests.post(url=url,headers=headers,data=data).json()
all_data_list.append(detail_json)
#Persistent storage all_data_list
with open('./allData.json','w',encoding='utf-8') as fp:
json.dump(all_data_list,fp=fp,ensure_ascii=False)
print('over


paging operation
import json
import requests
#Get the id values of different enterprises in batch
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
id_list = []#Add enterprise id
all_data_list = []#Store all business detail data
#Key value of parameter
for page in range(1,6):
page = str(page)
data = {
'on': 'true',
'page': page,
'pageSize': '15',
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':'',
}
ison_ids = requests.post(url=url,data=data,headers=headers).json()
for dic in ison_ids['list']:
id_list.append(dic['ID'])
#Get enterprise details
post_url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
data ={
'id':id
}
detail_json = requests.post(url=url,headers=headers,data=data).json()
all_data_list.append(detail_json)
#Persistent storage all_data_list
with open('./allData.json','w',encoding='utf-8') as fp:
json.dump(all_data_list,fp=fp,ensure_ascii=False)
print('over')