catalogue
I wrote some reptiles in the past few days. I will leave some pictures in the welfare section at the end of my official account. A big time ago, a big girl said that he put more Han clothes and sisters. Today, it was just a little time for Baidu to take a website of Hanfu, and then wrote a crawler to collect some photos.

1. Target site analysis
Target site: https://www.hanfuhui.com/
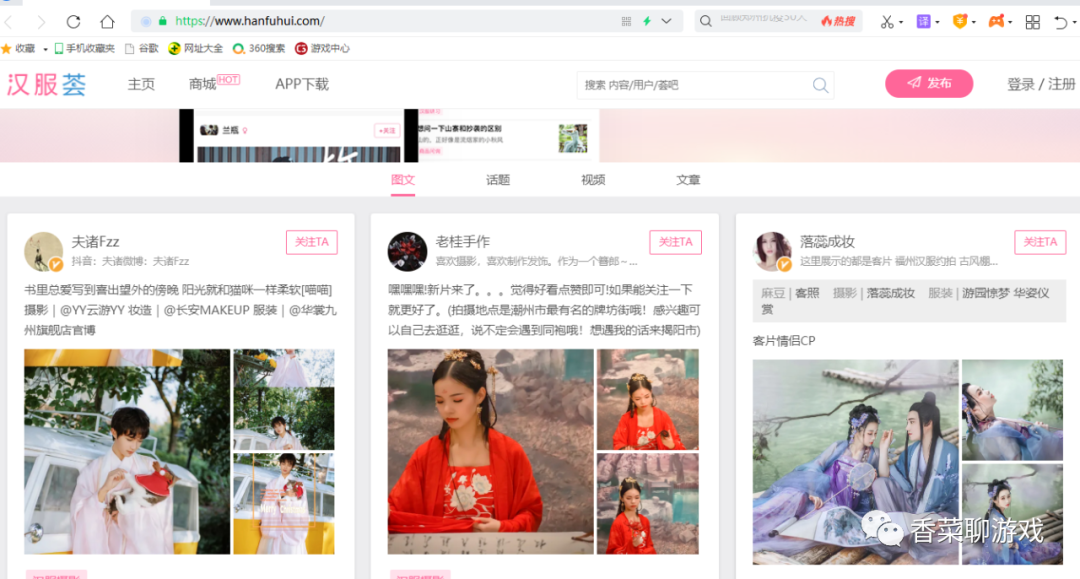
You can see that the home page is a flow layout. Dragging down will load new data.
Open a sub page to view the corresponding link information of each picture.

You can see the link information of this picture.
https://pic.hanfugou.com/ios/2019/12/27/17/30/157743904073740.jpg_700x.jpg

It seems a little simple. Once you locate the link information of the picture, just save the picture directly.
So far, we have the first scheme: open the home page, then slide, enter the sub interface, get all the picture link information, and save it all the time.
2. Page feed analysis
Keep sliding on the home page, open F12, clear all requests, and then switch to the Network tab to see how the page turns when sliding.
When dragging, two requests are sent first, and then a pile of json data is received.
API address:
https://api5.hanfugou.com/Trend/GetTrendListForHot?maxid=2892897&objecttype=album&page=3&count=20
Analyze the next parameter
Page is the page number,
count is the number of balloons per page
The objecttype object is an album

Since that's the guess, let's modify the parameters to request a new tab, and then request 30 data per page.
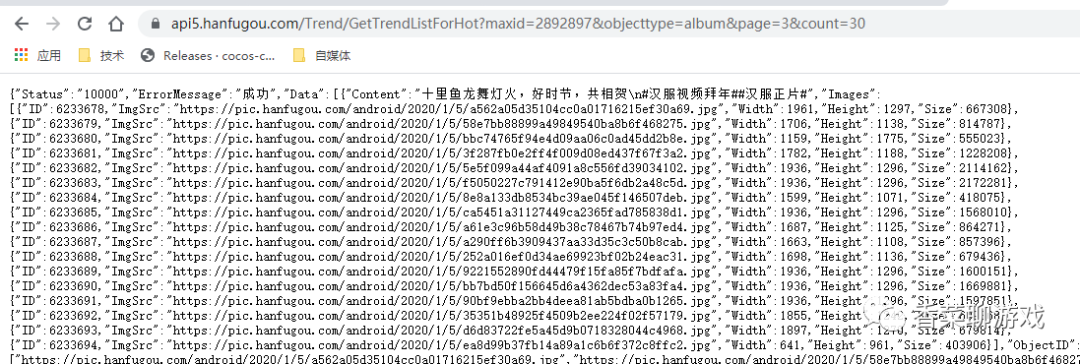
It seems that our guess is right.
3,show code
The analysis is over. Let's go directly to the code,
I chose the second solution because it is simple and can be done directly with an api
import requests
isQuick = False
# author: coriander
def get_content(url):
try:
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
response = requests.get(url, headers={'User-Agent': user_agent})
response.raise_for_status() # If the returned status code is not 200, an exception is thrown;
except Exception as e:
print("Crawl error")
else:
print("Crawl successful!")
return response.json()
def save_img(img_src):
if img_src is None:
return
imgName = img_src.split('/')[-1]
try:
print(img_src)
url = img_src
if isQuick:
url = url + "_700x.jpg"
headers = {"User-Agent": 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'}
# Note that the verify parameter is set to False and the website certificate is not verified
requests.packages.urllib3.disable_warnings()
res = requests.get(url=url, headers=headers, verify=False)
data = res.content
filePath = 'hanfu/' + imgName
with open(filePath, "wb+") as f:
f.write(data)
except Exception as e:
print(e)
def readAllMsg(jsonData):
allImgList = []
dataList = jsonData['Data']
for dataItem in dataList:
imgList = dataItem['Images']
allImgList.extend(imgList)
return allImgList
if __name__ == '__main__':
# url = "https://api5.hanfugou.com/Trend/GetTrendListForHot?maxid=2892897&objecttype=album&page=3&count=20"
url = "https://api5.hanfugou.com/trend/GetTrendListForMain?banobjecttype=trend&maxtime=0&page=2&count=10"
jsonData = get_content(url)
imgList = readAllMsg(jsonData)
for imgDict in imgList:
save_img(imgDict['ImgSrc'])
Note: you need to create a folder hanfu under the current code path
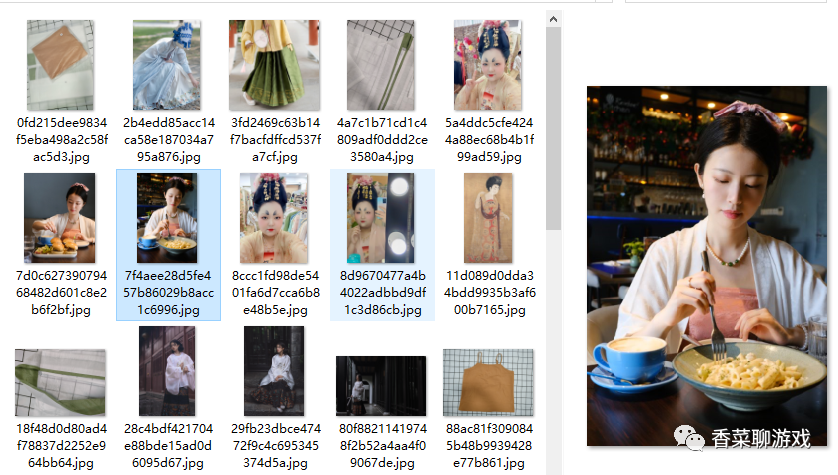
Look at our results:
4. Problem reply
1. Although the search process of page turning API is simple, it also takes some time, which should not be ignored.
2. In the process of analysis, it is found that the picture of the sub page is the reduced picture. On the original basis, "_700x.jpg" is added, and the obtained size is 700. After changing the mobile device, there is also a suffix of 200. The downloaded picture is not the original picture, which is a little fuzzy
3. Analysis of the original image. In the process of viewing js, I found a bigpic function. I checked the original image, but I didn't find the relevant button on the page, and I don't know what happened.

4. The original picture downloaded now is also found after a chaotic analysis. Otherwise, it may be the downloaded picture 404. I don't believe you try. It took some time, and I didn't analyze the reason for this later, because I have downloaded the picture
5. A switch isQuick = False is added to the code. If it can be set to True to speed up the download, 700 width photos will be downloaded. Otherwise, the original photos are too large and take a long time. Choose your own
5. Summary
It is suggested that students who have no needs do not use this crawler. After all, it will hurt the website and waste traffic. If students need it, they should not go too far to affect the normal operation of the website.
Regular benefits

