Write in front
Recently, many teachers in the school use cloud class. After a course, what should they do if they want to see the students' homework (submitted in the form of activities)? Cloud class does not provide batch download for students.
In addition, a teacher's newly released teaching task has set that the video is not allowed to drag or double the speed 😥, So I just have time. I want to write a reptile and practice my hand. I want to climb the cloud class resources and activities.
The following will introduce the activity crawling in detail. Here are the assignments in two formats (word and pdf), and finally give the complete activity crawling code and similar resource crawling code (i.e. video format).
Sign in
When I tried to directly use the request library to access the activity page of the cloud class, I returned 200 and climbed down an html, but I couldn't find the desired link, so I copied the html locally and found it as follows:
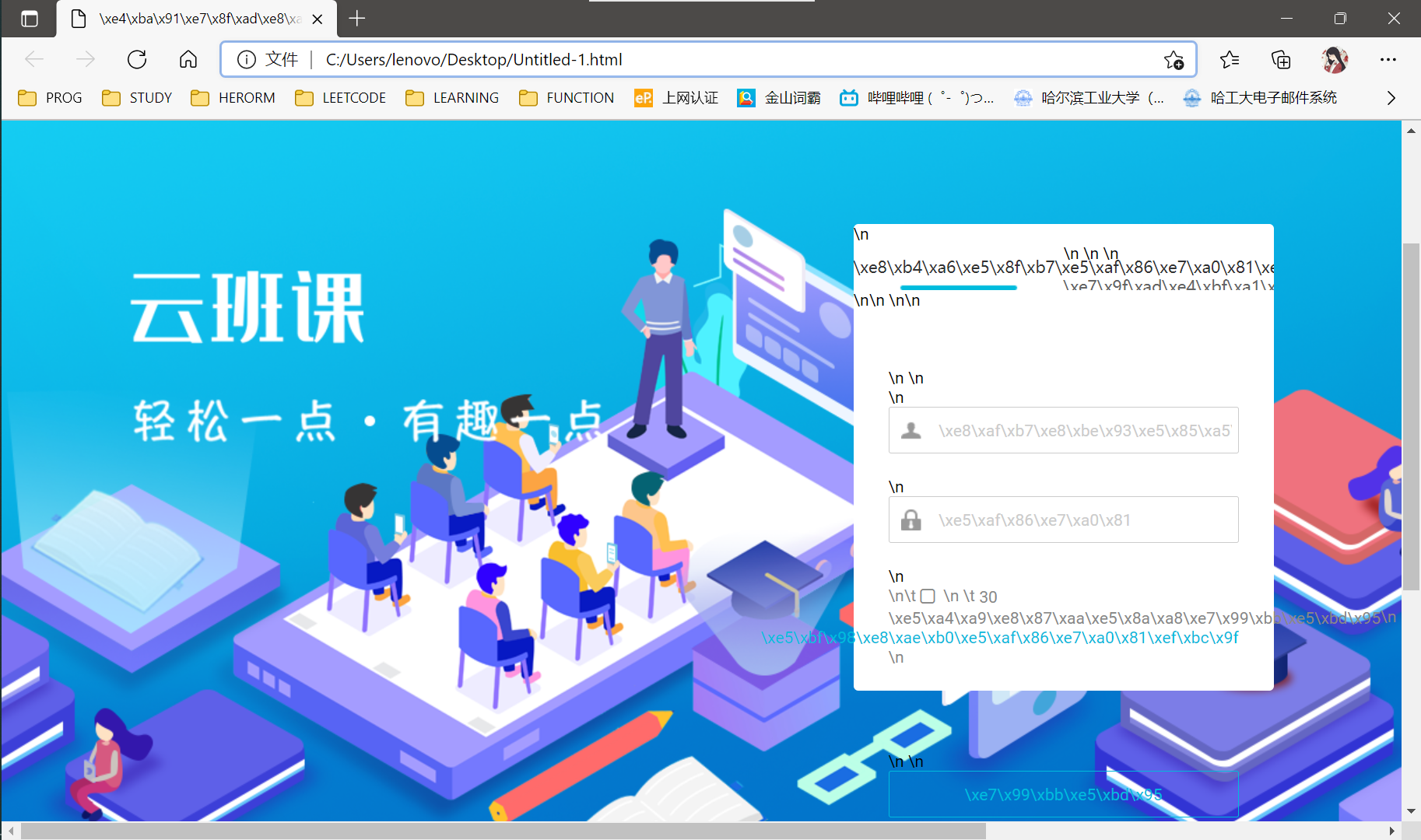
Well, I haven't logged in yet. We can imitate this login process in two ways: one is to obtain a session, and the other is to bring cookies (we won't introduce what these two things are. In fact, we will find that they are the same in essence, which is equivalent to your pass).
-
Get session: the method requests.session() has been encapsulated in the requests library. All we need to do is
- Get session
- According to the package sent during login (you need to capture the package and analyze the format yourself), package a data and header in the same way (it's not necessary. Some websites may have anti crawler mechanism)
- Let the session send this package to the login page (it must be the login page. Think that it will redirect to the login page when it is not logged in), that is, simulate login
def getsession(account_name, user_pwd): logURL = r'https://www.mosoteach.cn/web/index.php?c=passport&m=account_login' session = requests.session() logHeader = { 'Referer': 'https://www.mosoteach.cn/web/index.php?c=passport', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko' } logData = { 'account_name': account_name, 'user_pwd': user_pwd, 'remember_me': 'Y' } logRES = session.post(logURL, headers=logHeader, data=logData) return sessionAt this time, if you print the properties in the session, you will find that there is a field called cookies in the session, which looks like this:
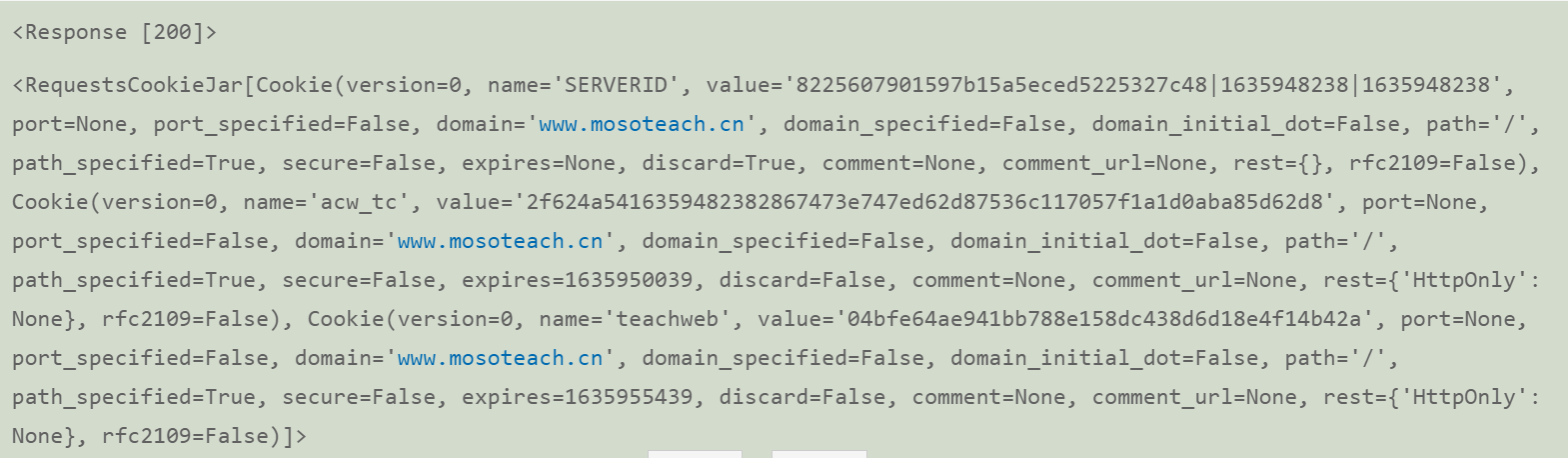
We simulate login to obtain the session so that it can carry the cookie to complete the following work. -
With cookies: you don't need to simulate login. After logging in directly on the web version, you can get your own cookies
- You can click this link to get cookies. It's very detailed
- Then take the cookie and package it into the header, which is equivalent to telling the server who you are
header = { "Cookie": cookie, 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko', 'Connection': 'Keep-Alive' }
Get job list
What I expect is a form, {"file name": "Download url"}, and pdf and word are downloaded separately. First, check (right click on the web page or F12) how to get these two information:
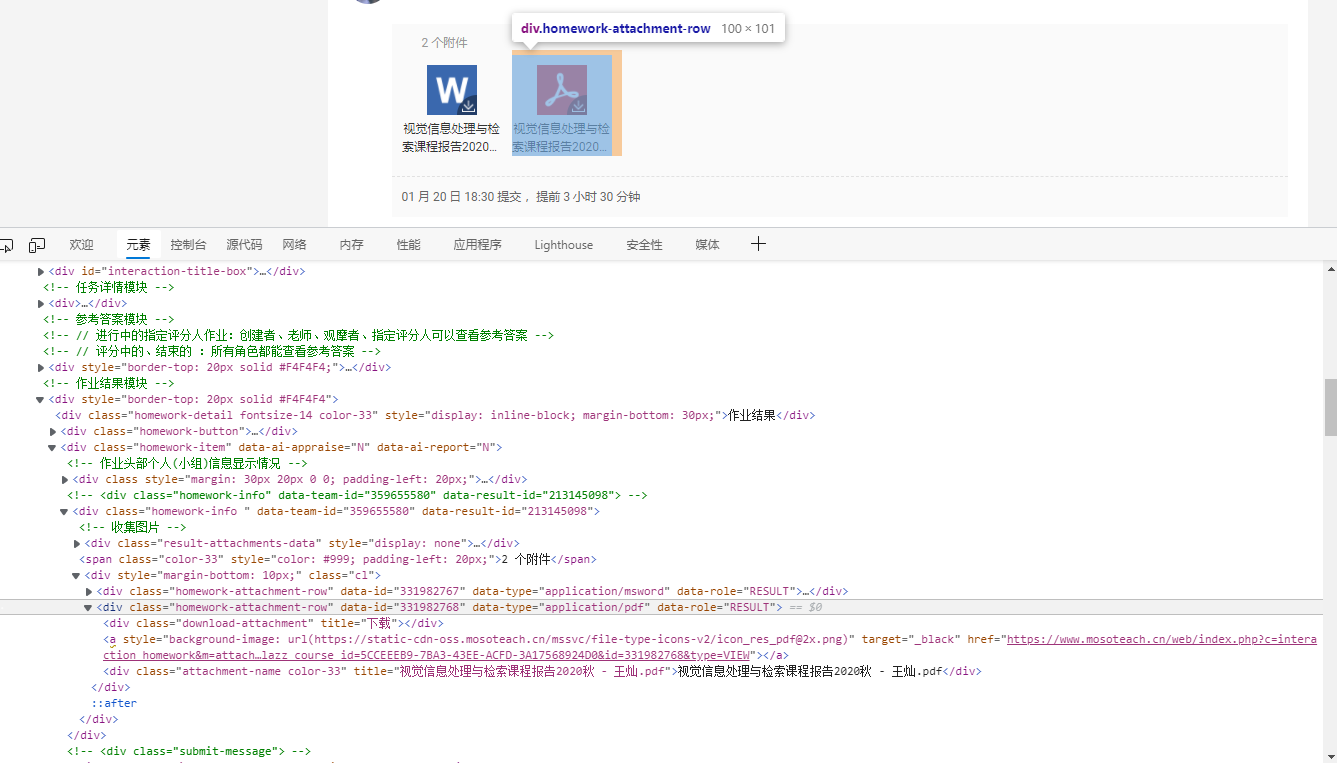
Maybe I can't see it clearly. I copied it here:
<div class="homework-attachment-row" data-id="331982768" data-type="application/pdf" data-role="RESULT">
<div class="download-attachment" title="download"></div>
<a style="background-image: url(https://static-cdn-oss.mosoteach.cn/mssvc/file-type-icons-v2/icon_res_pdf@2x.png)" target="_black" href="https://www.mosoteach.cn/web/index.php?c=interaction_homework&m=attachment_url&clazz_course_id=5CCEEEB9-7BA3-43EE-ACFD-3A17568924D0&id=331982768&type=VIEW"></a>
<div class="attachment-name color-33" title="Visual information processing and retrieval course report - name.pdf">Visual information processing and retrieval course report - name.pdf</div>
</div>
It can be found that each resource exists under < div > with a class of home attachment row, and we use two things under home attachment row:
- <a>The corresponding url is, but if you click this icon, it is actually browsed by default. Check the "network" page and click to DOWNLOAD the pdf. You will find that the real url is a large string of href. Change the last VIEW to DOWNLOAD (ha ha. In fact, I guessed it directly when I didn't look at the http package)
- Attachment name color-33 corresponds to the name. There's nothing to say
Then, use an element of the BeautifulSoup library to process and select. The above code:
def getdic(url):
pdfdic, worddic = {}, {}
# Change the human eye readable code
raw_data = session.get(url).content.decode('utf-8')
data = BeautifulSoup(raw_data, 'html5lib')
# Get each resource box
homeworks = data.select('.homework-attachment-row')
# Decompose each resource to obtain name and url
for homework in homeworks:
name = homework.select('.attachment-name')[0]['title']
url = homework.select('a')[0]['href']
if '.pdf' in name:
pdfdic[name] = url
elif ('.doc' in name):
worddic[name] = url
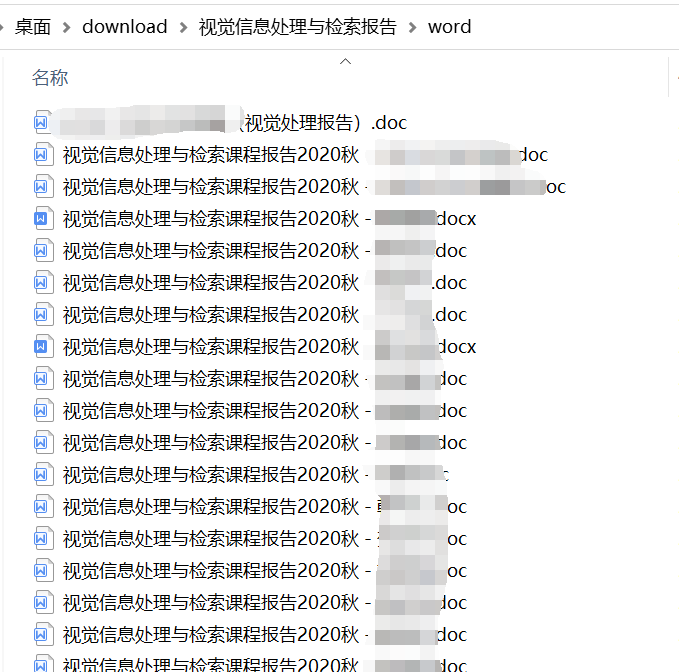
worddic.pop('Visual information processing and retrieval course report - XXX.doc')
return pdfdic, worddic
This is what we got. As a result, we found that the lengths of the two lists do not match (two more in worddic). We can find that the doc template uploaded by the teacher needs to be pop ped out in the first resource:

Another one... Because I used print(1 if ('.docx' or '.docx' in name) else 0) at that time, and the python execution logic is in first and then or, which is always True, I mixed in a video 'test1' handed in by my classmates in their homework_ face_ Result. MP4 ', I click to open it. It's an ai face changing function demonstration. I'm happy for a long time. Feel ha ha, it's outrageous.
download
Finally, download, contract the url of each element in the list, obtain bytes, and then write by block! Don't forget to deal with the url. After all, we directly analyze the VIEW mode.
def download(dic, dir):
os.makedirs(dir)
for name, url in tqdm(dic.items()):
url = url.replace("VIEW", "DOWNLOAD")
# Send a get request like the target url address and return a response object
data = session.get(url=url, stream=True)
with open(dir+"/"+name, "wb") as f:
for chunk in data.iter_content(chunk_size=512):
f.write(chunk)
Add an elegant progress bar to see the effect:
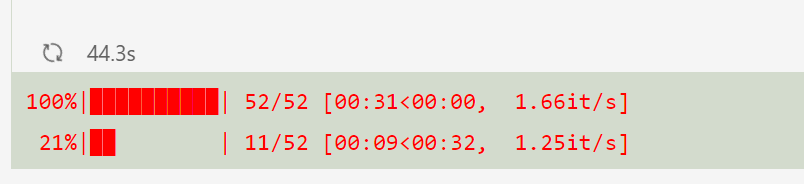
Well, very satisfactory.
code
Download resources (the function body has been given above)
import requests import os from bs4 import BeautifulSoup from tqdm import tqdm # Activity link inter_url = 'Fill in the link on your browser. It must be https://www.mosoteach.cn/web/index.php?c=interaction_ 'starting with 'homework' # user name account_name = 'Fill in your user name' # password user_pwd = 'Fill in your password' # The folder address you want to save in pdf_dir = "Visual information processing and retrieval report/pdf" word_dir = "Visual information processing and retrieval report/word" # Simulate login session = getsession(account_name, user_pwd) # Get resource list pdfdic, worddic = getdic(inter_url) # download download(pdfdic, pdf_dir) download(worddic, word_dir)
Download Video
This is still a little laborious, because the logic of receiving and contracting is as follows:

Click the video and a request is sent. The url of the m3u8 file is returned. Download the m3u8 file and open it with Notepad. It is found that:
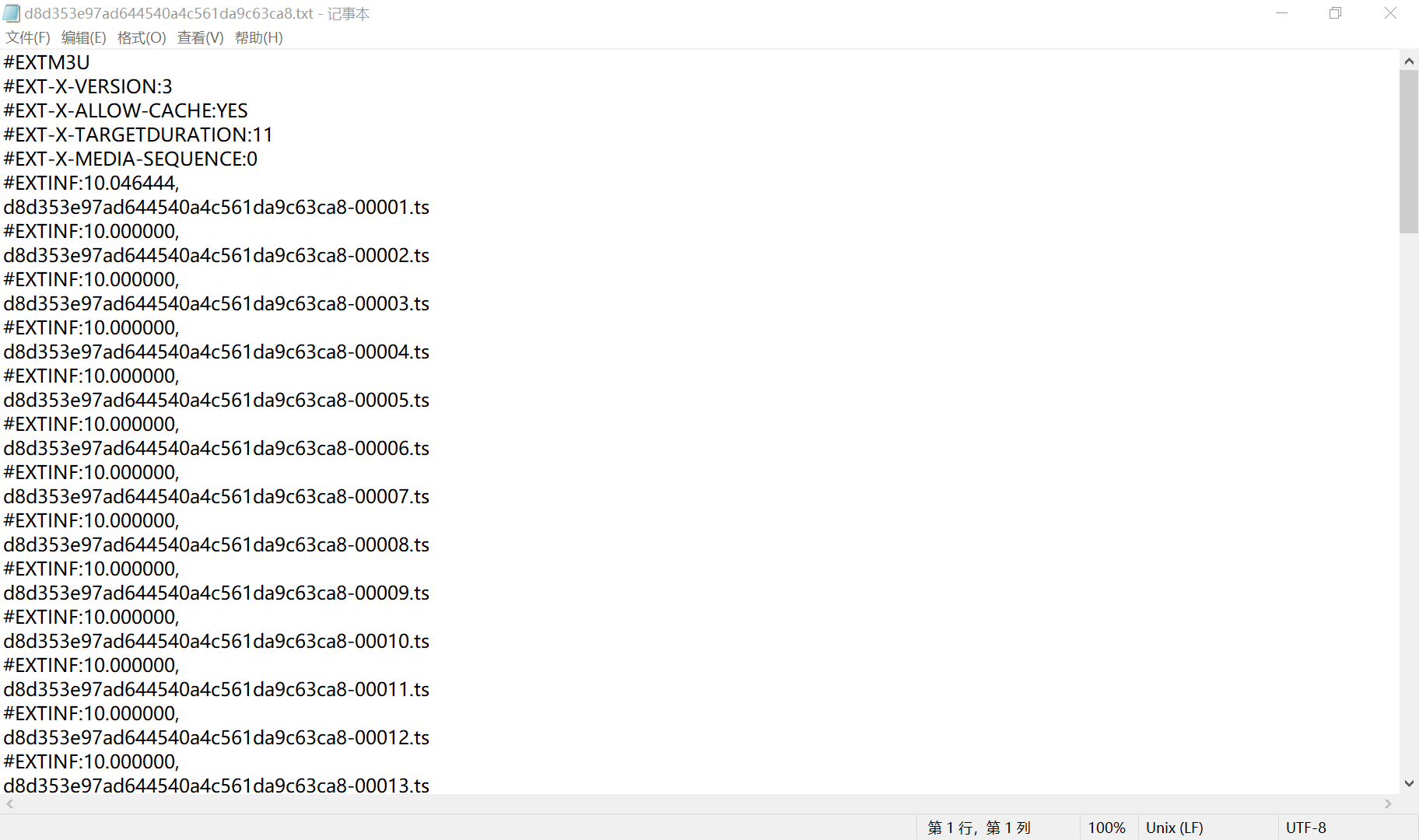
This is the corresponding video list. Each segment lasts about 10 seconds and is really speechless. It may be judged by whether the students see it or not by whether they request the last package.
Then the following is the continuous process of contracting and receiving packages, which is also written by this blogger Method of using m3u8 crawling cloud class video.
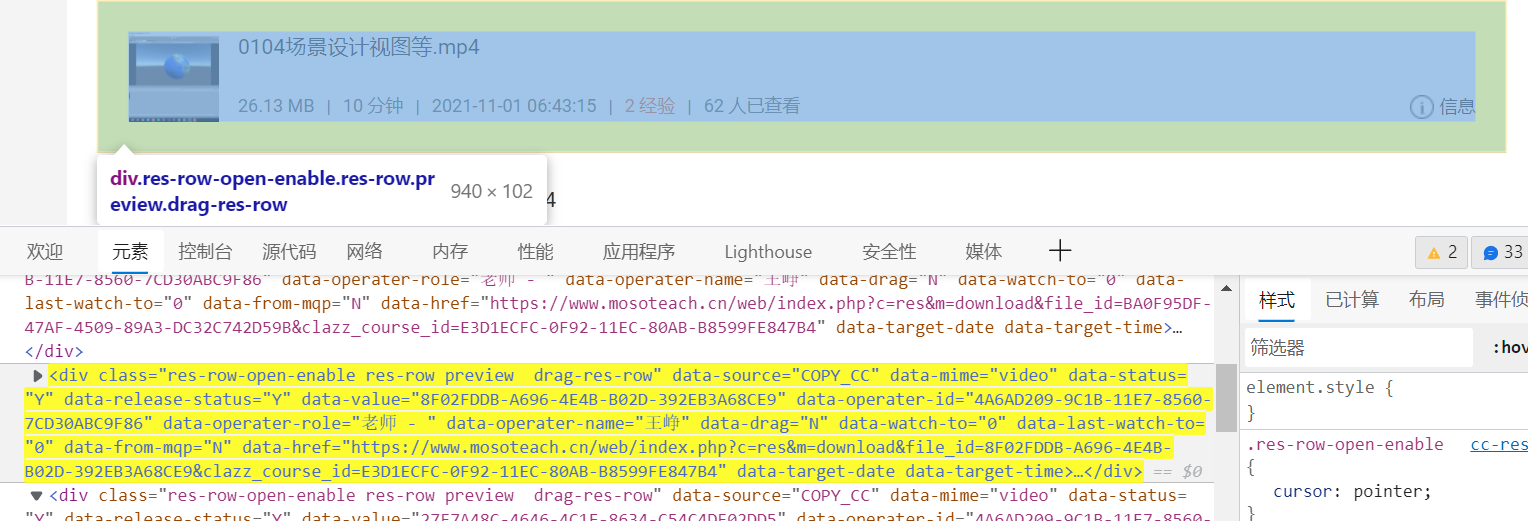
But I always think there must be a simpler way, such as... This paragraph is html. The reason why I can find it is because I have the experience of pickpocketing activities in front. I searched DOWNLOAD instead of checking according to the packets sent and received in the network. Hey hey.
Then, let's go.
import requests
import os
from bs4 import BeautifulSoup
from tqdm import tqdm
# Resource link
res_url = 'Fill in the link on your browser. It must be https://Www.mosoteach. CN / Web / index. PHP? C = res'
# user name
account_name = 'Fill in your user name'
# password
user_pwd = 'Fill in your password'
# The folder address you want to save in
mov_dir = "Virtual reality development technology"
def getsession(account_name, user_pwd):
logURL = r'https://www.mosoteach.cn/web/index.php?c=passport&m=account_login'
session = requests.session()
logHeader = {
'Referer': 'https://www.mosoteach.cn/web/index.php?c=passport',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
logData = {
'account_name': account_name,
'user_pwd': user_pwd,
'remember_me': 'Y'
}
logRES = session.post(logURL, headers=logHeader, data=logData)
return session
def getdic(url):
movdic = {}
# Change the human eye readable code
raw_data = session.get(url).content.decode('utf-8')
data = BeautifulSoup(raw_data, 'html5lib')
# Get each resource box
movs = data.select('.res-row-open-enable')
# Decompose each resource to obtain name and url
for mov in movs:
name = mov.select('.res-info .overflow-ellipsis .res-name')[0].text
url = mov['data-href']
movdic[name] = url
return movdic
def download(dic, dir):
os.makedirs(dir)
for name, url in tqdm(dic.items()):
# Send a get request like the target url address and return a response object
data = session.get(url=url, stream=True)
with open(dir+"/"+name, "wb") as f:
for chunk in data.iter_content(chunk_size=512):
f.write(chunk)
session = getsession(account_name, user_pwd)
movdic = getdic(res_url)
download(movdic, mov_dir)