brief introduction
Sometimes, when we naively download HTML pages using urllib libraries or Scrapy, we find that the elements we want to extract are not in the HTML we download, although they seem to be readily available in browsers.
This shows that the elements we want are dynamically generated through js events under some of our operations. For example, when we brush QQ space or microblog comments, we keep brushing down. The webpage is getting longer and longer, and the content is getting more and more. This is the dynamic loading that makes people love and hate.
There are currently two ways to crawl dynamic pages
- Analysis of page requests (this article describes this)
- selenium simulates browser behavior
To get back to the point, here's the idea of crawling dynamically loaded pages by analyzing page requests. The central idea is to find the request from the javascript file that sent the request.
Take two examples, Jingdong Review and Shanghai Stock Exchange.
Jingdong review
This is a relatively simple example.
First of all, we randomly look for a hot commodity, comment more.
This is it. ADATA SU800 256G 3D NAND SATA3 Solid State Hard Disk.
Click in to see the current status of this page
The scrollbar gives the first impression that the page seems to have little content.
Keyboard F12 opens the developer's tool, chooses the Network tab, and chooses JS
Following chart
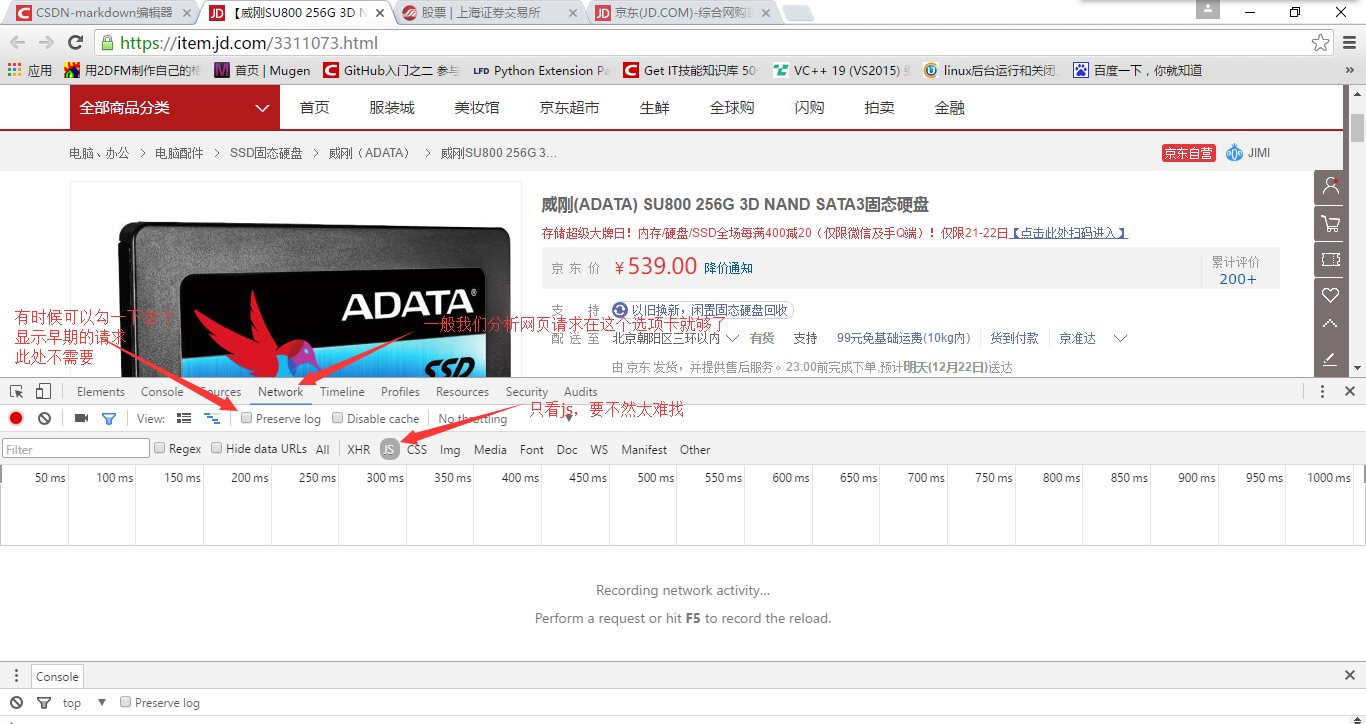
Then, we drag the scrollbar on the right, and you'll see that there are new js requests in the developer's tool (quite a few), but with a cursory translation, it's easy to see which ones are taking comments, as shown below.
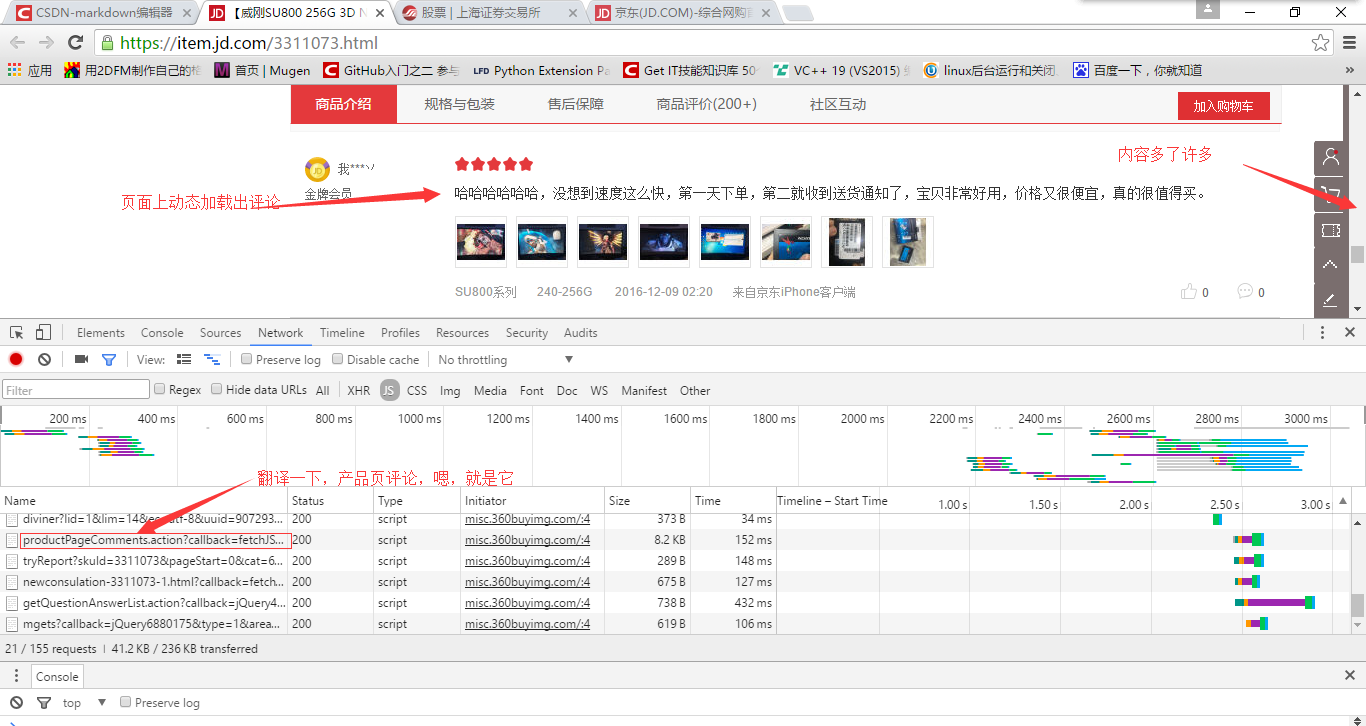
Okay, duplicate it. Target url of js request

Open it in the browser and find that the data we want is right here, as shown below.
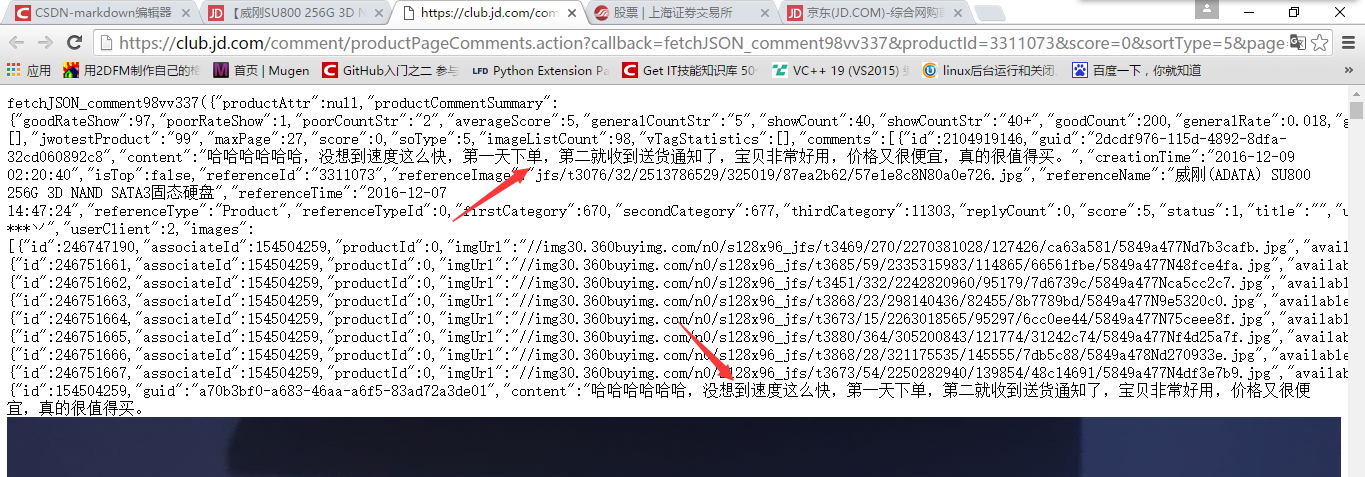
This whole page is a data in json format. For Jingdong, when the user drops down the page, triggers a js event, sends the request to the server to fetch the data, and then fills these json data into the HTML page through a certain js logic. For Spider, what we need to do is to sort out and extract these json data.
In practical application, of course, we can not find the target address of the request initiated by js in every page, so we need to analyze the rules of the request address. Generally, the rules are easy to find, because the rules are too complex for the server to maintain. Let's take a look at Jingdong's request:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv337&productId=3311073&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0
It's a long GET request, but the parameter naming is very standard, product ID, comment page number and so on, because I'm just giving an example here, I don't have to study one by one.~
If you have the idea, just write according to the normal crawler, send requests, get responses, parse data, follow-up processing and so on...
Shanghai Stock Exchange
This is a question asked by a Taoist friend some time ago. I still feel chewy, which is more difficult than the previous example.
Target website: Shanghai Stock Exchange
The aim is to get stock information on every page. It seems very simple, but by looking at the source code, it is found that the links on every page are invisible in the source code. Following chart
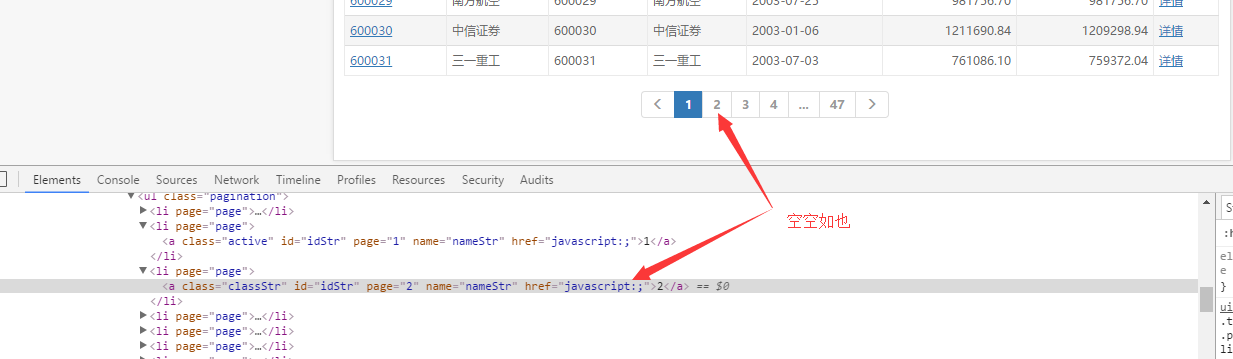
ok, is also js dynamic loading, not shown in the source code, but certainly can not hide our developer tools, according to the above Jingdong idea, cut to the Network, js tab, click on the page number, get the request address, all the flow of clouds, as shown below.
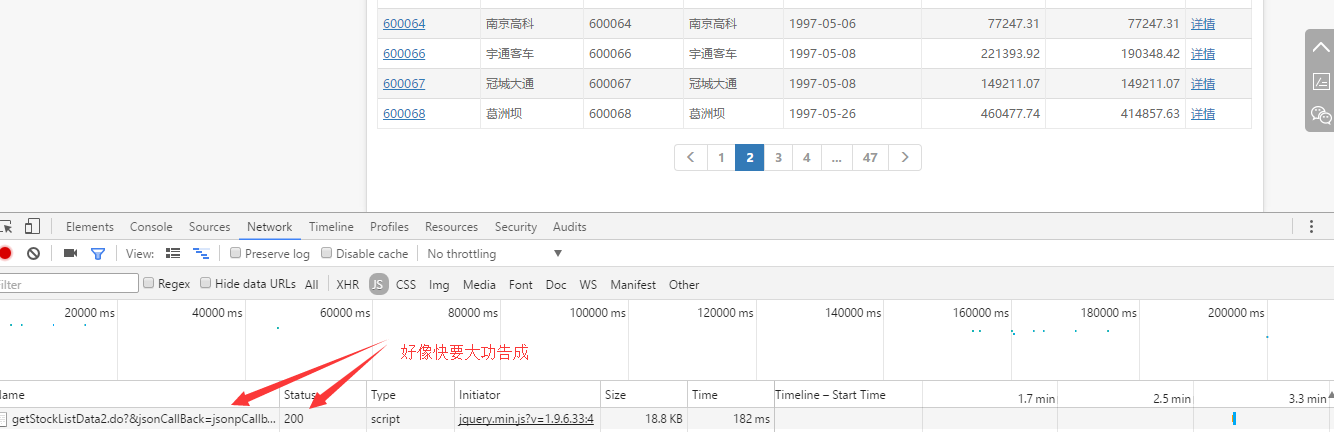
However, when we duplicate the url and open it in the browser, the browser presents the following information:

403 mistake! Strange!
What does the 403 status code mean? That is to say, this server knows what you are looking for when you send this string of url s, but Laozi won't give it to you!
What to do, there are ways~
Think about it. Why do we normally get data when we click on page two and page three on that page? Why can't we ask directly? It's the same browser.
The problem is that browsers make requests from the previous page and request header s are different. For example, cookie s and refer s are fields through which the server filters out our requests.
The browser is like this, so is our crawler. Finally, I solve this problem by setting a detailed request header for the crawler (from the original page we can request), including cookie s, refer s and so on, and finally succeeded in getting the returned json data.
This code was written in urllib of Python 3. I only helped him write a page of data. Logically, he wrote it himself. As follows, the officials may try to get rid of the header information.~
import urllib.request Cookie = "PHPStat_First_Time_10000011=1480428327337; PHPStat_Cookie_Global_User_Id=_ck16112922052713449617789740328; PHPStat_Return_Time_10000011=1480428327337; PHPStat_Main_Website_10000011=_ck16112922052713449617789740328%7C10000011%7C%7C%7C; VISITED_COMPANY_CODE=%5B%22600064%22%5D; VISITED_STOCK_CODE=%5B%22600064%22%5D; seecookie=%5B600064%5D%3A%u5357%u4EAC%u9AD8%u79D1; _trs_uv=ke6m_532_iw3ksw7h; VISITED_MENU=%5B%228451%22%2C%229055%22%2C%229062%22%2C%229729%22%2C%228528%22%5D" url = "http://query.sse.com.cn/security/stock/getStockListData2.do?&jsonCallBack=jsonpCallback41883&isPagination=true&stockCode=&csrcCode=&areaName=&stockType=1&pageHelp.cacheSize=1&pageHelp.beginPage=3&pageHelp.pageSize=25&pageHelp.pageNo=3&pageHelp.endPage=31&_=1480431103024" headers = { 'User-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36', 'Cookie': Cookie, 'Connection': 'keep-alive', 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, sdch', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Host': 'query.sse.com.cn', 'Referer': 'http://www.sse.com.cn/assortment/stock/list/share/' } ''' //If you need a good learning and communication environment, then you can consider Python Learning and Communication Group: 548377875; //If you need a systematic learning material, you can consider Python Learning Communication Group: 548377875. ''' req = urllib.request.Request(url,None,headers) response = urllib.request.urlopen(req) the_page = response.read() print(the_page.decode("utf8"))
epilogue
In the same sentence, the idea of crawling dynamically loaded pages by analyzing page requests. The central idea is to find the request from the javascript file that sent the request. Then we can use our existing crawler knowledge to construct the request.