preface
After writing the CSDN blog, Have you ever worried that if one day the blog "disappears" (you know)... Your efforts will not be in vain? And do you want to save your favorite articles locally and avoid "disappearing" or charging for them one day? This article will learn how to use Python script to automatically save CSDN blog articles to the local in HTML and PDF formats.
Single article preservation
Let's take a look at how to save and format a specified single article locally.
Scripting
1. The script needs to import the following modules:
import pdfkit import requests import parsel
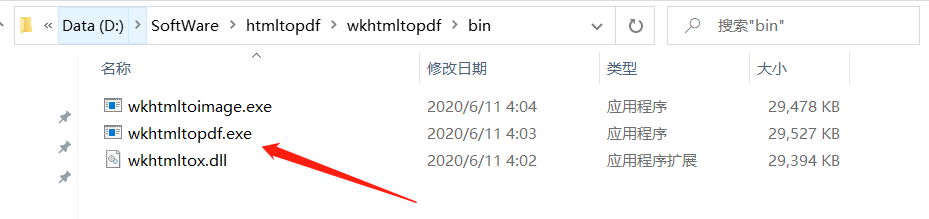
2. At the same time, the PC needs to install wkhtmltopdf tool to convert html documents into pdf, Official website download address , after installation:
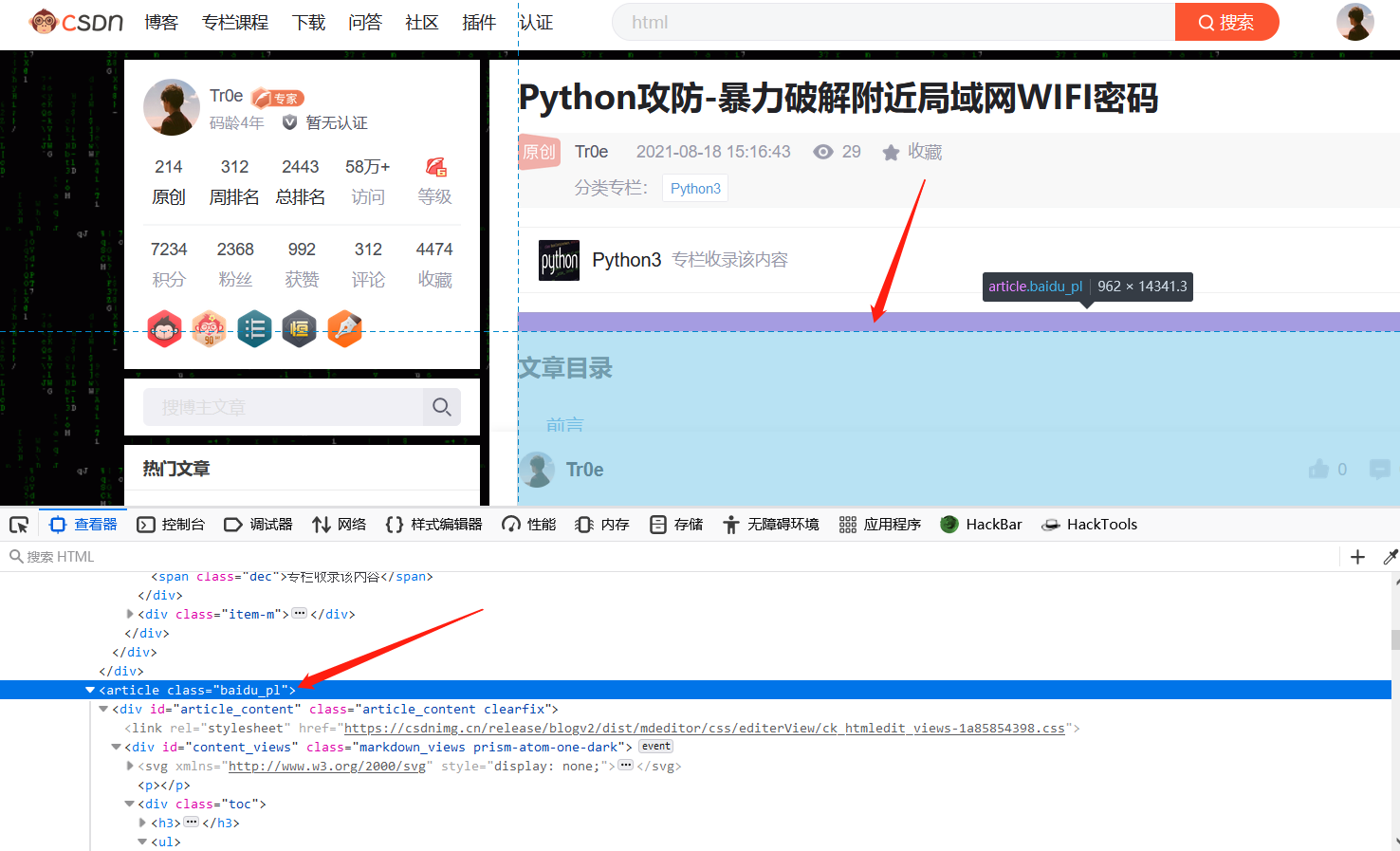
 3. Open the browser and right-click to check and analyze the html elements related to the article content (excluding irrelevant content). Through simple analysis, we can find that the content we need is under the article tag:
3. Open the browser and right-click to check and analyze the html elements related to the article content (excluding irrelevant content). Through simple analysis, we can find that the content we need is under the article tag:
 4. Because the web page elements behind the extracted act tag can not form a complete html document, it needs to be formatted and assembled. The following is a standard html structure:
4. Because the web page elements behind the extracted act tag can not form a complete html document, it needs to be formatted and assembled. The following is a standard html structure:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
Related content
</body>
</html>
After analyzing the preceding contents, let's look at the complete script directly:
import pdfkit
import requests
import parsel
url = 'https://bwshen.blog.csdn.net/article/details/119778471'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
html = response.text
selector = parsel.Selector(html)
# Extract the title of the article
title = selector.css('.title-article::text').get()
# Extract the content labeled article
article = selector.css('article').get()
# Define a standard html structure for assembling the content of the article tag extracted above
src_html = '''
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
{content}
</body>
</html>
'''
# Assemble the article content into a standard html format document and save it locally
with open(title + '.html', mode='w+', encoding='utf-8') as f:
f.write(src_html.format(content=article))
print('%s.html Saved successfully' % title)
# Call wkhtmltopdf tool to convert html document to pdf format document
config = pdfkit.configuration(wkhtmltopdf=r'D:\SoftWare\htmltopdf\wkhtmltopdf\bin\wkhtmltopdf.exe')
pdfkit.from_file(title + '.html', title + '.pdf', configuration=config)
print(title + '.pdf', 'Saved successfully')
Effect demonstration
The code runs as follows:
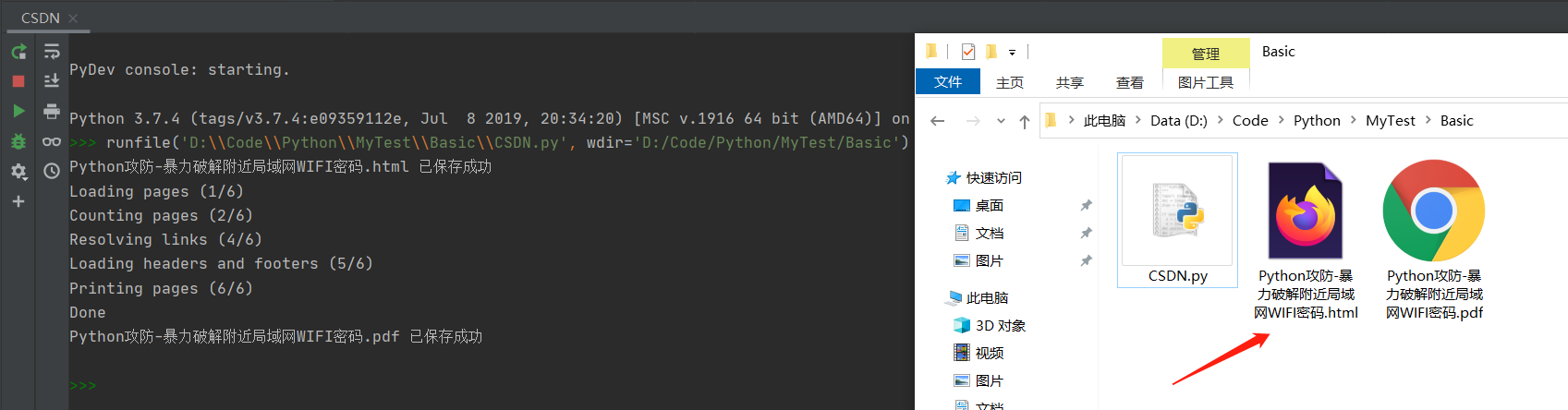 1. The generated HTML document is as follows:
1. The generated HTML document is as follows:
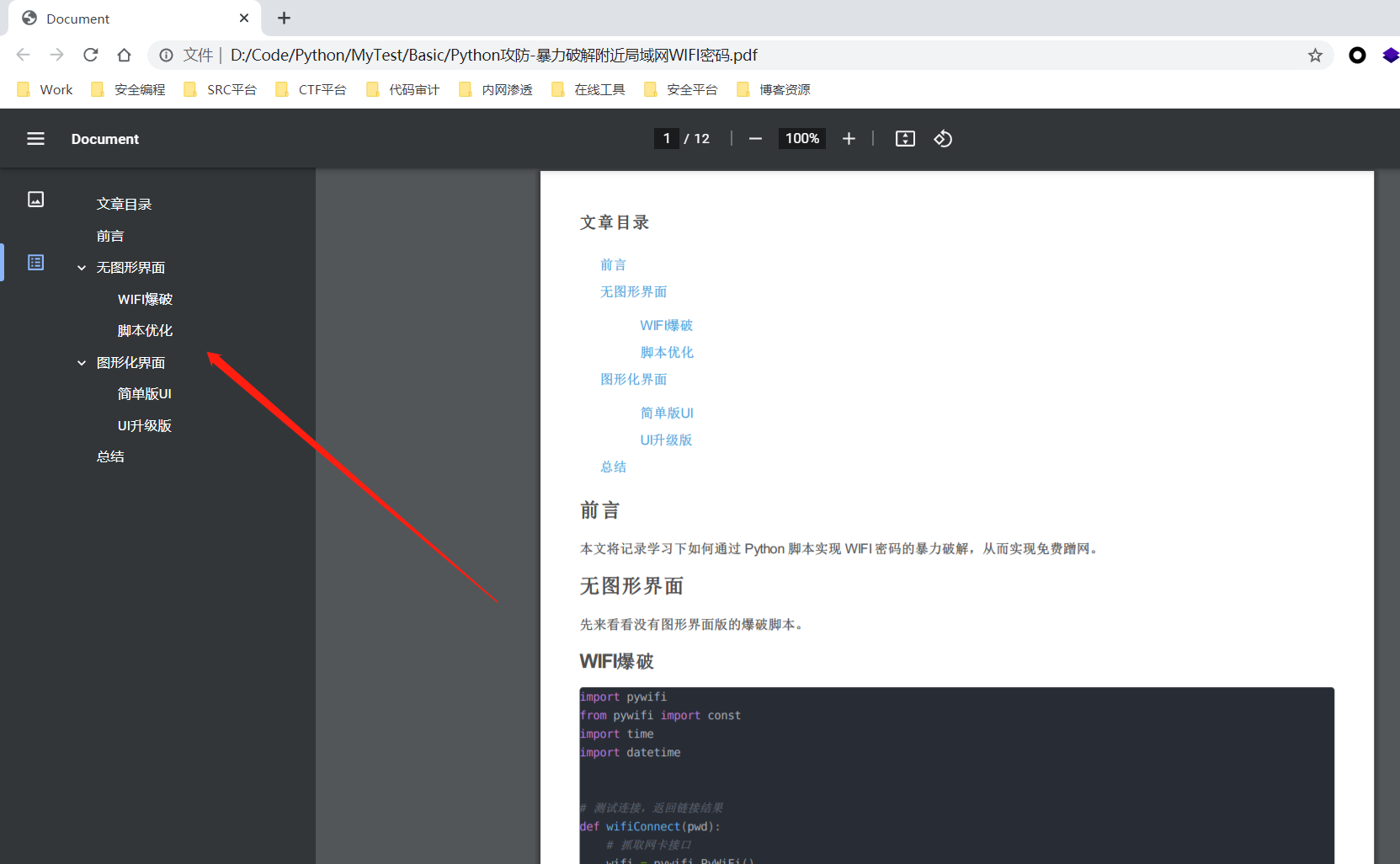
 2. The generated PDF file is as follows (with navigation label):
2. The generated PDF file is as follows (with navigation label):
Batch save
How to save and convert all the articles of a blogger automatically? You can't deal with it one by one... Let's improve the script to realize the batch automatic saving and conversion of all blog posts of a blogger.
Scripting
Visit my blog home page and find that the tag below contains all the article links of the current page:
 Take a look at the complete code:
Take a look at the complete code:
import pdfkit
import requests
import parsel
import time
src_html = '''
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
{content}
</body>
</html>
'''
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
}
def download_one_page(page_url):
response = requests.get(url=page_url, headers=headers)
html = response.text
selector = parsel.Selector(html)
title = selector.css('.title-article::text').get()
# Extract the content labeled article
article = selector.css('article').get()
# Save HTML document
with open(title+'.html', mode='w+', encoding='utf-8') as f:
f.write(src_html.format(content=article))
print('%s.html Saved successfully' % title)
# Convert HTML to PDF
config = pdfkit.configuration(wkhtmltopdf=r'D:\SoftWare\htmltopdf\wkhtmltopdf\bin\wkhtmltopdf.exe')
pdfkit.from_file(title+'.html', title+'.pdf', configuration=config)
print('%s.pdf Saved successfully' % title)
def down_all_url(index_url):
index_response = requests.get(url=index_url,headers=headers)
index_selector = parsel.Selector(index_response.text)
urls = index_selector.css('.article-list h4 a::attr(href)').getall()
for url in urls:
download_one_page(url)
time.sleep(2.5)
if __name__ == '__main__':
down_all_url('https://bwshen.blog.csdn.net/')
Effect demonstration
The code runs as follows:

summary
In fact, if you use Firefox, you can use ready-made plug-ins: PDF Saver For CSDN Blog Save a CSDN blog post as a local PDF file, but the generated PDF does not have a navigation tag and cannot be saved in batch, so you'd better use Python script.