 In July 2021, the biggest melon should be Wu moufan.
In July 2021, the biggest melon should be Wu moufan.
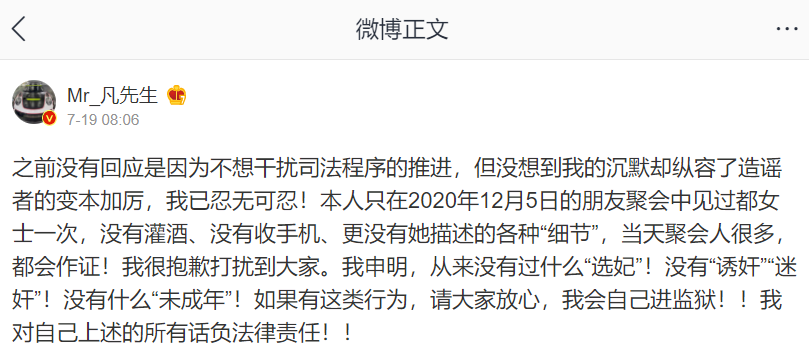
The pop melon in the entertainment industry is not new, but Wu moufan's melon is especially big!
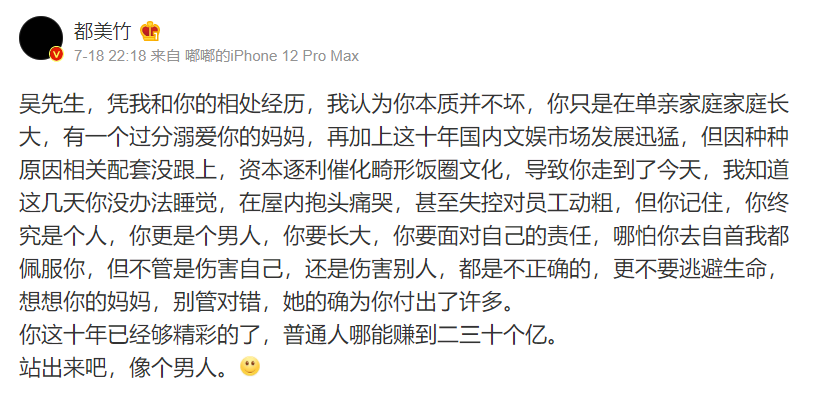
The thing is, a freshman girl named "Du mouzhu" broke the news on her microblog that she suffered cold violence during her love with Wu moufan

He also said that Wu moufan had the behavior of "selecting concubines" and "luring" underage girls
Subsequently, a number of girls who claimed to have had a relationship with Wu moufan have posted chat records to support Wu moufan's behavior.
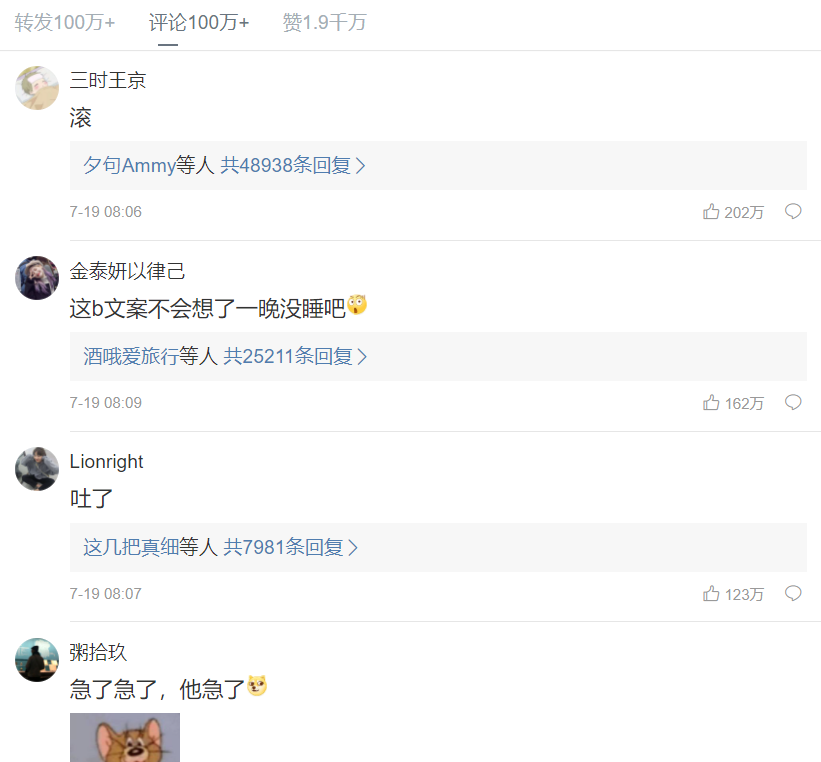
Is that really the case? Let's see what 1000000 + netizens say?
Target determination
Our goal is the following netizen comments on Wu moufan's microblog
See what they say?

requirement analysis
The data we want to obtain, if any
User id, author name, author motto, posting time and posting content.
First, we open the browser developer mode in F12:
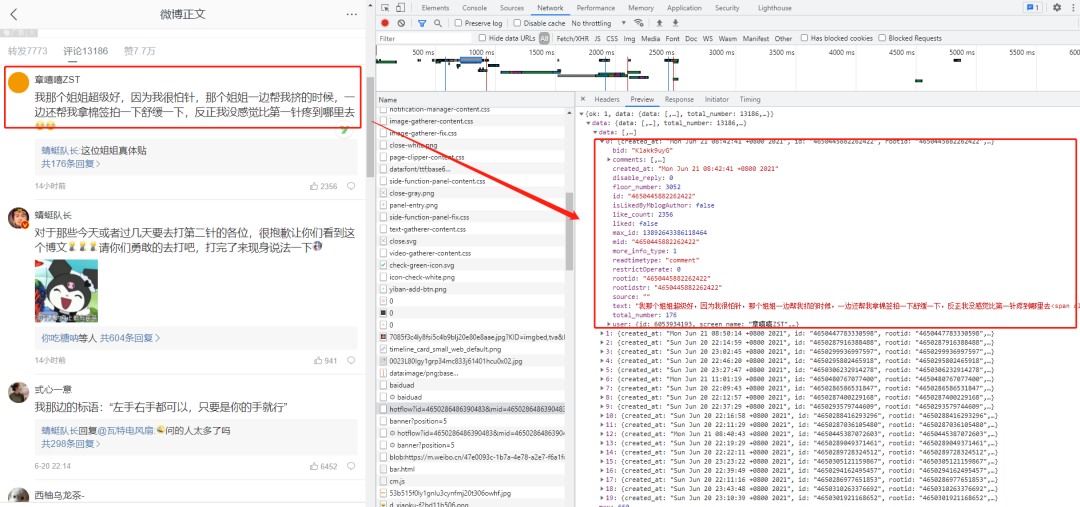
Find our target url:
https://m.weibo.cn/comments/hotflow?id=4660583661568436&mid=4660583661568436&max_id_type=0
There are also anti creep parameter headers
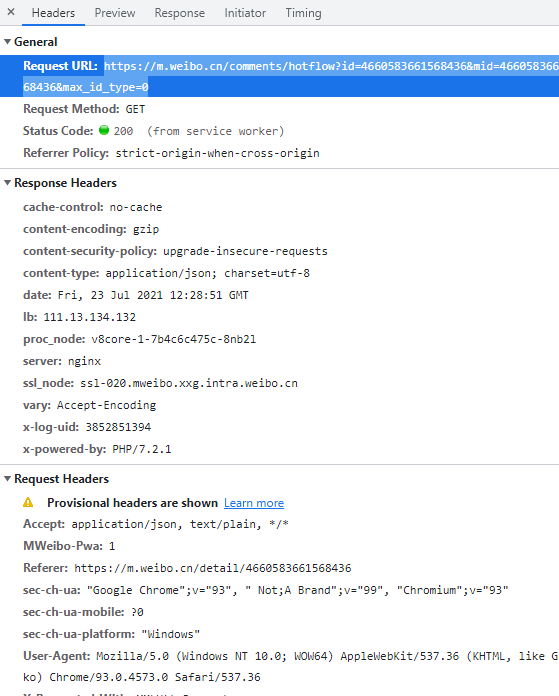
We opened the link with a browser and found that this is a data set in standard json format,
All the data we need is in this json data
So the first step is to get the data set in json format.

Send request
The goal is clear. Next, add the code:
url = 'https://m.weibo.cn/comments/hotflow?id=4660583661568436&mid=4660583661568436&max_id_type=0'
print('current url Yes:', url)
headers = {
'cookie': 'SUB=_2A25NyTOqDeRhGeVG7lAZ9S_PwjiIHXVvMl3irDV6PUJbktB-LVDmkW1NT7e8qozwK1pqWVKX_PsKk5dhdCyPXwW1; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFGibRIp_iSfMUfmcr5kb295NHD95Q01h-E1h-pe0.XWs4DqcjLi--fi-2Xi-2Ni--fi-z7iKysi--Ri-8si-zXi--fi-88i-zce7tt; _T_WM=98961943286; MLOGIN=1; WEIBOCN_FROM=1110006030; XSRF-TOKEN=70a1e0; M_WEIBOCN_PARAMS=oid%3D4648381753067388%26luicode%3D20000061%26lfid%3D4648381753067388%26uicode%3D20000061%26fid%3D4648381753067388',
'referer': 'https://m.weibo.cn/detail/4660583661568436',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4573.0 Safari/537.36'
}
resp = requests.get(url, headers=headers).json()
wb_info = resp['data']['data']
print(wb_info)
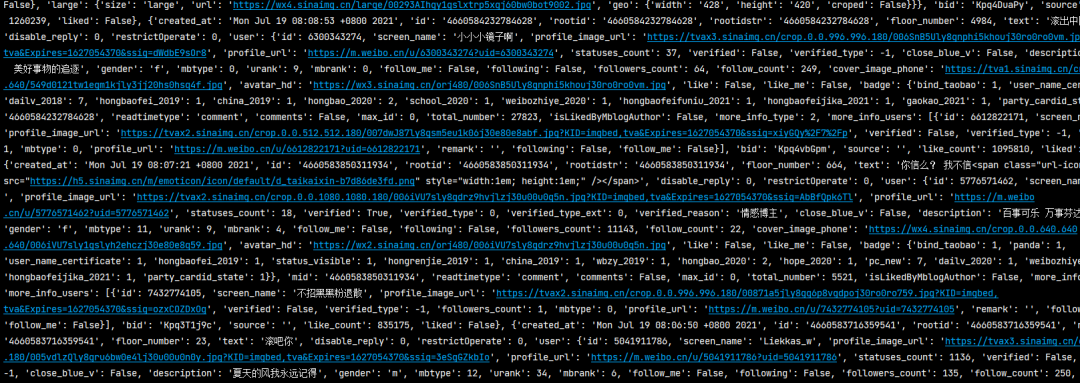
Parse page
The previous step has successfully simulated the browser to obtain the data.
The next step is how to extract our target data
for item in wb_info:
user_id = item.get('user')['id'] #User id
author = item['user']['screen_name'] #Author name
auth_sign = item['user']['description'] #Author's motto
time = str(item['created_at']).split(' ')[1:4]
rls_time = '-'.join(time) #Posting time
text = ''.join(re.findall('[\u4e00-\u9fa5]', item['text'])) #Post content
print(user_id, author, auth_sign, rls_time, text)
'''
6414472816 Three seasons Wang Jing Brush your microblog three nights and two ends Jul-19-08:06:52 rolling
6556281551 Jin Taiyan disciplined herself Don't talk to me if you don't take a big reward and belittle it every day Jul-19-08:09:16 The copywriter didn't think about it all night, was he surprised
3320924712 Lionright The people I like are stars and light Jul-19-08:07:06 Vomited
1966108801 Porridge nineteen Melody is homesick Jul-19-08:09:13 Hurry, hurry, he's hurry
6300343274 Little mirror Life is one after another The pursuit of good things Jul-19-08:08:53 Get out of China
5776571462 Peeled potato stew Pepsi Cola Everything Fanta Mood Sprite Seven up a week Jul-19-08:07:21 Do you believe it? I don't believe it. I'm too happy
5041911786 Liekkas_w I will always remember the summer wind Jul-19-08:06:50 Go away, you
2316414853 Are you a fool Justice will prevail Jul-19-08:17:02 All the good-looking ones are in his bed, and all the ugly ones are in control
5737714811 I like Crispy Shrimp cakes D 🌫 Jul-19-08:11:56 We believe in your tears
5366720146 The right person at first sight Jul-19-08:13:52 Even if the criticism is serious, you praise those who believe you and make them vomit in the front row
5599841983 Did you breathe today National second class football player Jul-19-08:18:08 Get out of China
3284861767 Watch the Milky Way catch stars I don't sing loud love songs Jul-19-08:07:53 We are
6446391321 What can you do to me-Kris- My attitude towards all of you depends on your attitude towards Wu Yifan. Jul-19-08:06:56 We've been thinking
5225883987 Nothing kym What are you looking at? I'm just Susie. Jul-19-08:06:55 trust you
'''
Data obtained successfully!
It's all right. Let's continue to analyze and turn the page. Start with the url of each page.
https://m.weibo.cn/comments/hotflow?id=4660583661568436&mid=4660583661568436&max_id_type=0 https://m.weibo.cn/comments/hotflow?id=4660583661568436&mid=4660583661568436&max_id=27509545759071812&max_id_type=0 https://m.weibo.cn/comments/hotflow?id=4660583661568436&mid=4660583661568436&max_id=11396065415043588&max_id_type=0 https://m.weibo.cn/comments/hotflow?id=4660583661568436&mid=4660583661568436&max_id=5160872412930597&max_id_type=0
I believe you can see it at a glance. From the second page, there is an additional max_ Parameter for ID.
And this max_id changes randomly with the number of pages.
Now the question becomes how to get max_id
Get the max on the second page through the link on the first page_ id,
Then get to the third page through the link on the second page_ id
And so on, get all the data

Then use openpyxl to save the content to an Excel file, as shown in the following figure.
ws = op.Workbook()
wb = ws.create_sheet(index=0)
wb.cell(row=1, column=1, value='user id')
wb.cell(row=1, column=2, value='Author name')
wb.cell(row=1, column=3, value='Author's motto')
wb.cell(row=1, column=4, value='Posting time')
wb.cell(row=1, column=5, value='Post content')
count = 2
wb.cell(row=count, column=1, value=user_id)
wb.cell(row=count, column=2, value=author)
wb.cell(row=count, column=3, value=auth_sign)
wb.cell(row=count, column=4, value=rls_time)
wb.cell(row=count, column=5, value=text)
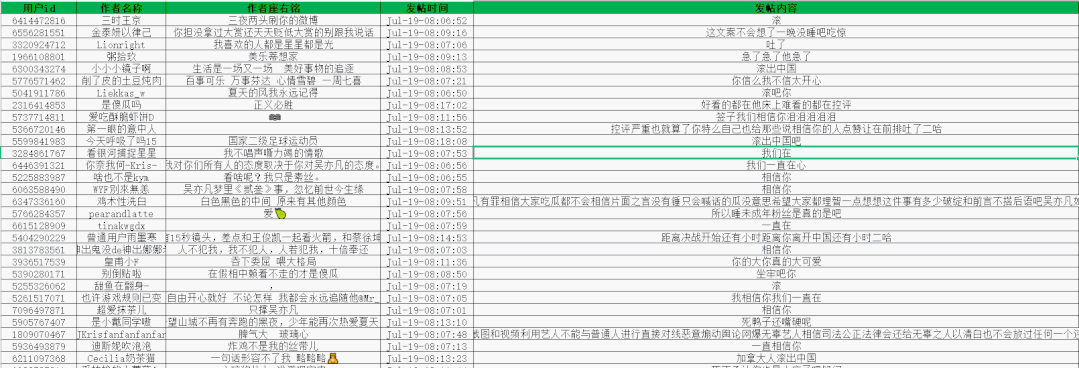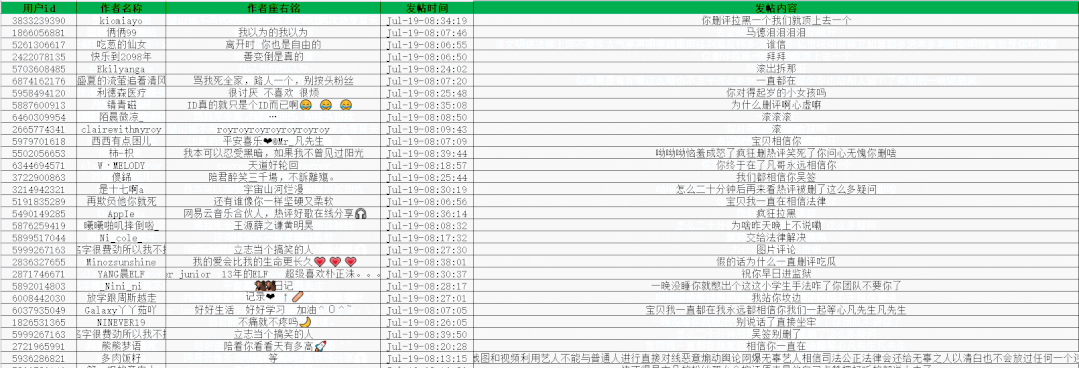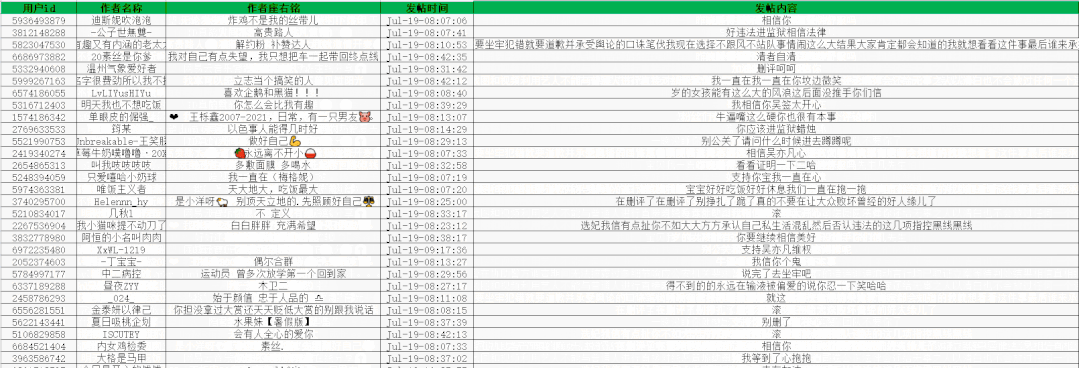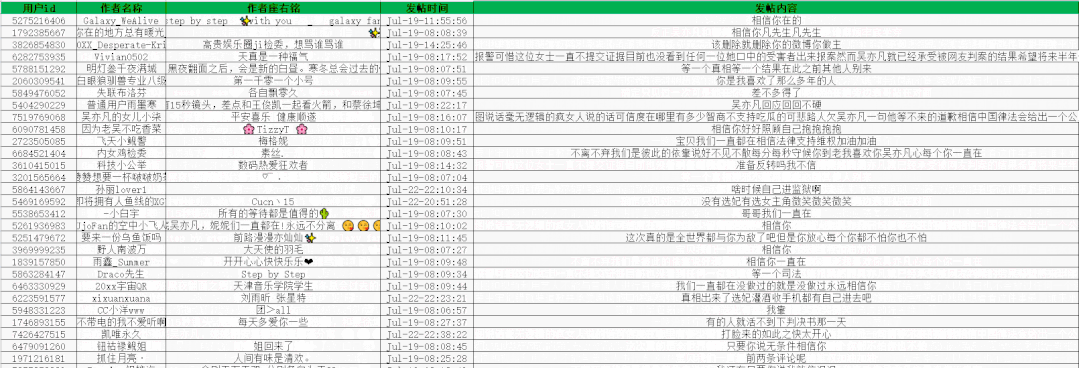
ws.save('666.xlsx')Get 50 pages of data first and practice
Some data obtained are as follows:
Visual display
rcv_data = pd.read_excel('./666.xlsx')
exist_col = rcv_data.dropna() #Delete empty lines
c_title = exist_col['Post content'].tolist()
#Cloud picture of film viewing comments
wordlist = jieba.cut(''.join(c_title))
result = ' '.join(wordlist)
pic = 'img1.jpg'
gen_stylecloud(text=result,
icon_name='fab fa-apple',
font_path='msyh.ttc',
background_color='white',
output_name=pic,
custom_stopwords=['you', 'I', 'of', 'Yes', 'stay', 'bar', 'believe', 'yes', 'also', 'all', 'no', 'Do you', 'Just', 'this', 'still', 'say', 'One', 'always', 'We']
)
print('Drawing succeeded!')

