hello everyone! I'm Lin hero
You know which is the hottest mobile game at present. Yes, it is the glory of the king. This mobile game must have been heard or played by everyone. There are 106 heroes and hundreds of hero skins. Today I'll teach you to climb down hundreds of skins.
catalogue
Get some information about heroes
Get hero skin name and skin link
Python Basics
Let's talk about some basic Python knowledge first. First, we may use these basic Python knowledge later to facilitate students with poor Python foundation to better understand. Second, in order to consolidate the foundation, we must look back and review the foundation.
If you have a good foundation, you can skip this section directly.
Python built-in function zip
The zip() function is used to take the iteratable object as a parameter, package the corresponding elements in the object into tuples, and then return the object composed of these tuples.
The syntax format is:
zip([iterable, ...])
The specific example code is as follows:
a=[1,2,3,4,5] b=['one','two','three','four','five'] c=zip(a,b) for ab in c: print(ab)
The operation result is:
(1, 'one') (2, 'two') (3, 'three') (4, 'four') (5, 'five')
We used the zip() function to combine the elements of the two lists into tuples one by one. Here, smart students found that we can use the zip() function to combine the skin name and corresponding skin links into tuples, which is more convenient to call.
Note: if the number of elements of each iterator is inconsistent, the length of the returned list is the same as the shortest object.
Python derivation
Derivation is a way to quickly create a sequence from one or more iterators. It can combine loops with conditional judgment to avoid lengthy code.
List derivation
The syntax format is as follows:
[expression for item in Iteratable object] [expression for item in Iteratable object if Conditional judgment]
The specific example 1 code is as follows:
#No derivation is used a=[] for i in range(1,4): a.append(i) print(a) #Use derivation b=[i for i in range(1,4)] print(b)
The operation result is:
[1, 2, 3] [1, 2, 3]
The specific example 2 code is as follows:
#When derivation is not used, the code is as follows: a=[] for i in range(1,4): if(i!=2): a.append(i) print(a) #After using the derivation, the code is as follows: b=[i for i in range(1,4) if i!=2] print(b)
The operation result is:
[1, 3] [1, 3]
Through the above two examples, it is obvious that the use of derivation greatly shortens our code lines and makes our code more professional.
Dictionary derivation
Dictionary derivation generates dictionary objects, whose syntax format is:
{key:value for Iterative variable in Iteratable object}The specific example code is as follows:
list = ['I','am','superman']
dict= {key: value for value,key in enumerate(list)}
print(dict)The operation result is:
{'I': 0, 'am': 1, 'superman': 2}Here we use the dictionary derivation to combine the elements in the list into a dictionary according to their positions.
Set derivation
Set derivation is a derivation with its own de duplication function
The syntax format is:
{expression for Iterative variable in Iteratable object if Conditional expression}The specific example code is as follows:
set = {i**2 for i in range(3)}
print(set)The operation result is:
{0, 1, 4}Careful students can find that various derivation formulas are mainly different from the outer brackets, and the others are similar, so as long as you remember one, the others will not be a problem.
'r', 'b', 'u', 'f' in Python
When writing code, we sometimes add some characters in front of the string, such as r, b, u, f, etc. What's the use of adding these characters? I'll explain it briefly next.
String preceded by 'r'
Its function is to remove escape characters
For example:
str1= 'Superman\n' str2= r'Superman\n' print(str1) print(str2)
The operation result is:
Superman Superman\n
We know that \ n means line feed. In the second line of code, we add an 'r' before the string, then \ n is only represented as a backslash and the letter n.
Characters beginning with r are often used in regular expressions.
String preceded by 'u'
The function is to encode the string in unicode.
Generally, English characters can be parsed normally under various codes, so they generally do not take u;
However, Chinese must indicate the required code, otherwise there will be garbled code once the code is converted.
String preceded by 'f'
Starting with 'f' means that python expressions in braces are supported in the string, which is equivalent to the abbreviation of format function.
For example:
name='superman'
print(f'I am {name}')
print('I am {}'.format(name))The operation result is:
I am superman I am superman
String preceded by 'b'
Adding 'b' before the string indicates that it is a bytes object, which is generally used in network programming, because the server and browser only recognize bytes data.
In Python 3, bytes and str are converted to each other as follows:
str.encode('utf-8')
bytes.decode('utf-8')Well, that's all for some basic knowledge of Python. Next, let's officially enter the theme - crawling the skin of the king's glory and hero.
Pre climbing analysis
Ajax analysis
First we open King glory official website , click the hero profile, and we can see the head of the king's glory hero, as shown in the figure below:
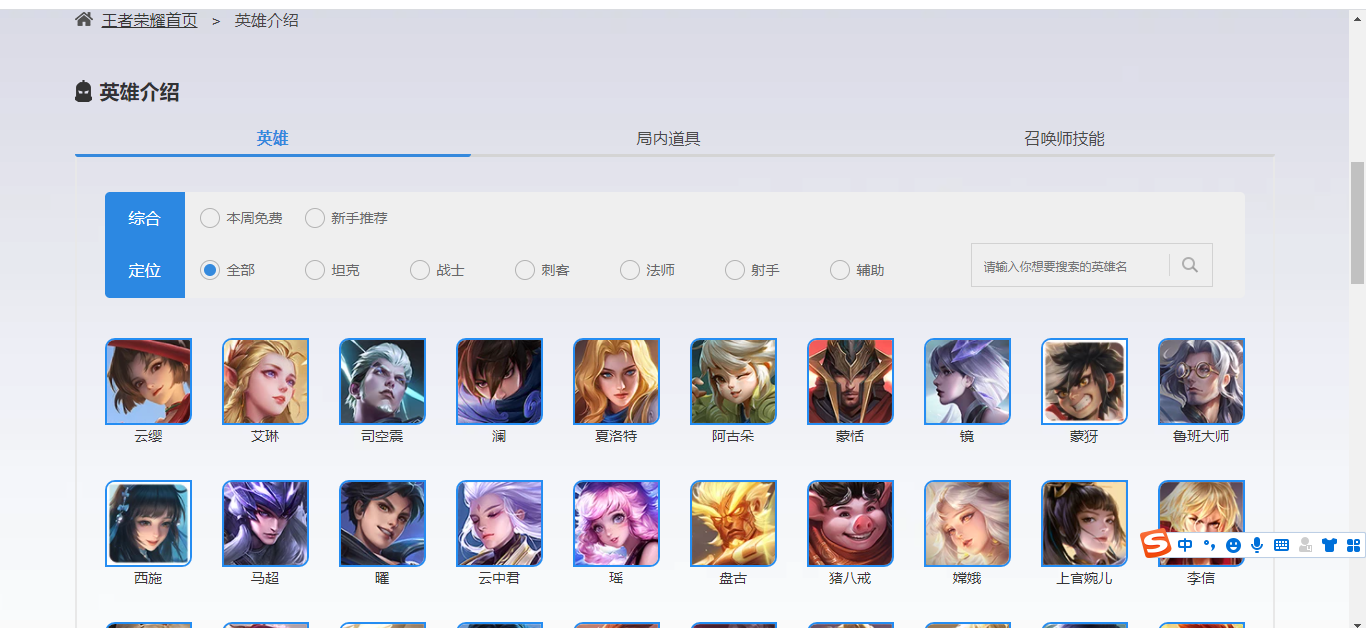
Then open the developer tool, switch to the XHR filtering tab, and click Rreview to check whether there are Ajax requests. Personally, I think the simplest way to obtain data information is to obtain it from Ajax requests. Therefore, generally, we give priority to checking whether there are Ajax requests. If not, we will consider using regular expressions or XPath to obtain data information.
After a simple search, we find that there are Ajax requests, as shown in the following figure:
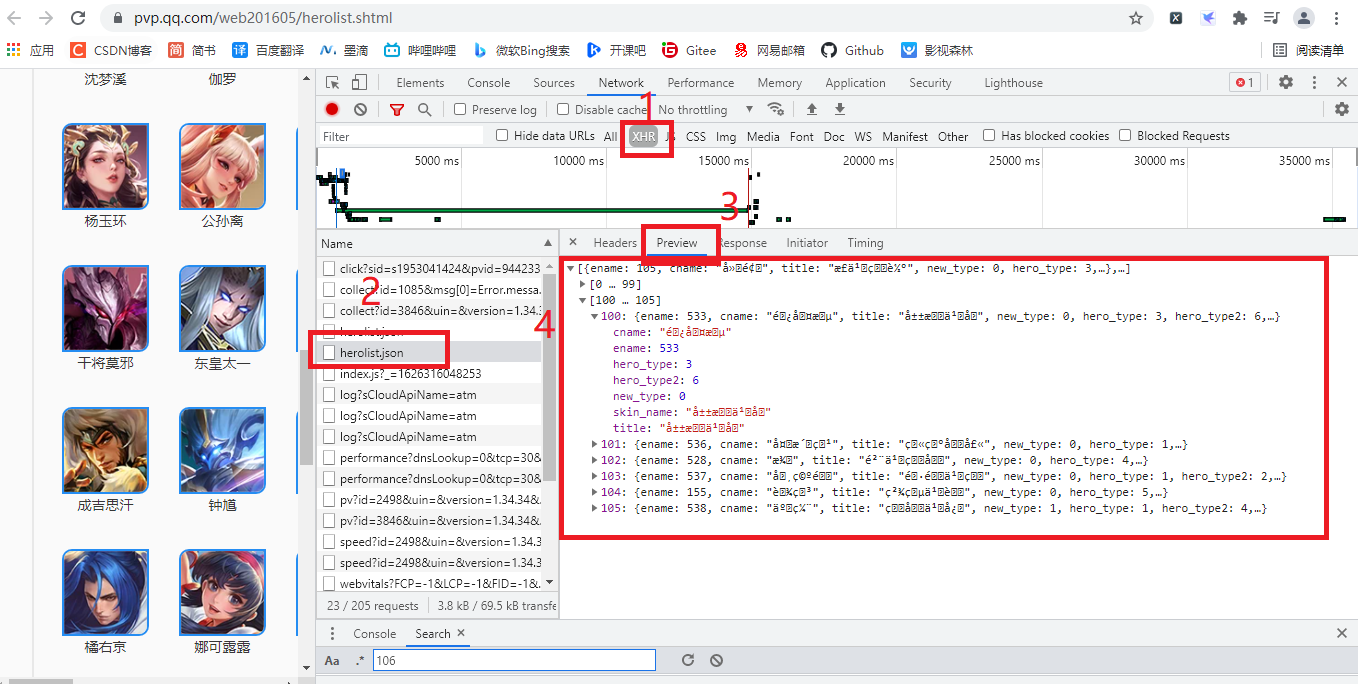
Some people may say what are the following things and whether they are an anti crawler method:
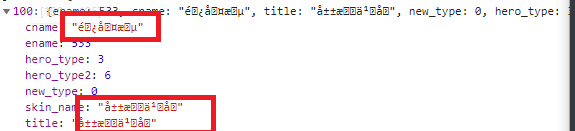
cname,skin_name and title can be translated from the perspective of English. We can know that they represent hero name, skin name and title respectively. Let's not worry about whether it is an anti crawler means, but try to obtain this information according to Ajax analysis,
The main codes are as follows:
response=requests.get(url,headers=headers)
json=response.json()
for i in json:
#Get skin id
nameid=i.get('ename')
#Get hero name
name=i.get('cname')
print(name)The operation results are as follows:

It can be seen from the hero's name that the garbled code in the Ajax request just now can be simply understood as that it is only displayed as garbled code in the request, which has little impact on the data we get.
The data in the Ajax request is useful to us. The hero name (create a folder according to the hero skin name) and hero id (used to construct the link of the hero page and the link of the skin picture). Some people may say that the hero skin name is also useful to us. After observation, it is found that some of the hero skin names are missing in the Ajax request, such as Yao. So we need to get the hero's skin name from another place.
Hero page analysis
We randomly click on several heroes' avatars to observe the difference between their corresponding URL links:
Charlotte page URL Link: https://pvp.qq.com/web201605/herodetail/536.shtml Yunying page URL link:https://pvp.qq.com/web201605/herodetail/538.shtml Zhuge Liang page URL Link: https://pvp.qq.com/web201605/herodetail/190.shtml
Through observation, we can find that only the following numbers of these URL links change, and these numbers are the hero's id, so we can construct each hero's URL link through the hero id.
For the old specification, open the developer tool to check whether there are Ajax requests. After searching, it is found that there are no Ajax requests, so we should consider using regular expressions or XPath to obtain data information. In the Ajax analysis in the previous step, we have obtained the hero name and hero id. in the hero page, we need to obtain the skin link and skin name.
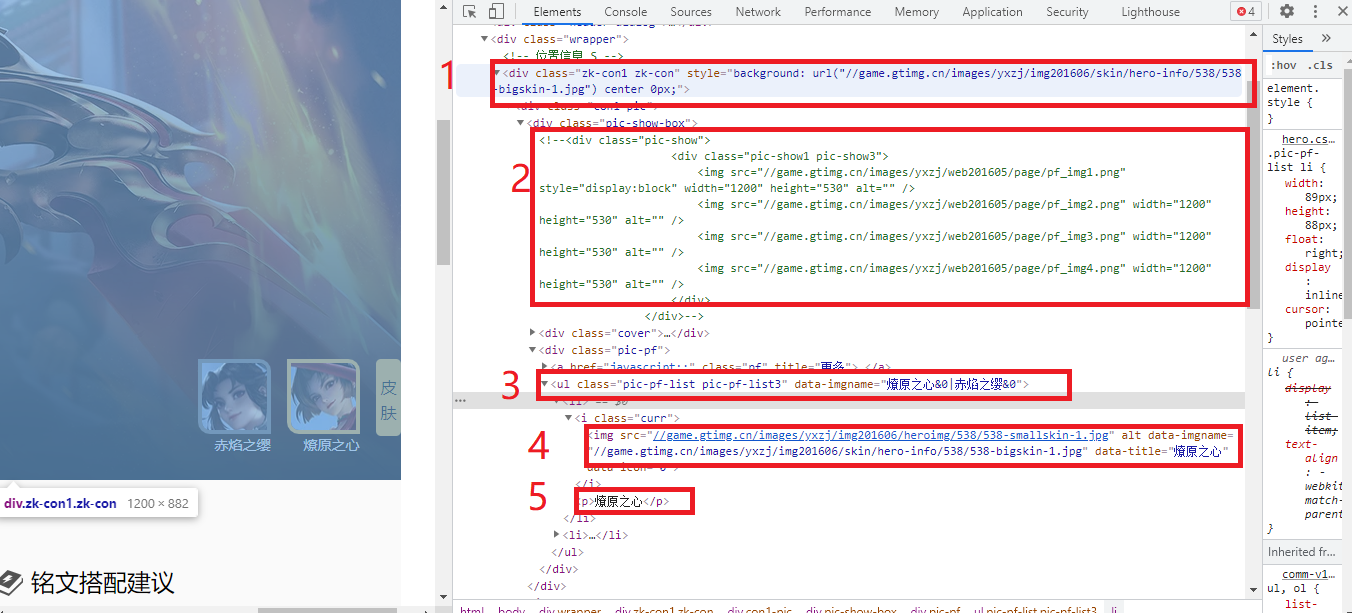
Open the developer tool and find that there are many picture links. Obviously, the URL links in 2 and 3 above are not the picture URL links we want to obtain. Then we open the URL link in 1 and find that the link is exactly the link we need:
https://game.gtimg.cn/images/yxzj/img201606/heroimg/538/538-mobileskin-1.jpg

Next, we only need to observe the law of the link and construct the URL link of the skin according to the law
Hero: Yunying https://game.gtimg.cn/images/yxzj/img201606/heroimg/538/538-mobileskin-1.jpg # the heart of a prairie fire https://game.gtimg.cn/images/yxzj/img201606/heroimg/538/538-mobileskin-2.jpg # red flame tassel Hero: Charlotte https://game.gtimg.cn/images/yxzj/img201606/heroimg/536/536-mobileskin-1.jpg # rose swordsman
Through observation, it can be found that only the back of the hero skin link: 536/536-mobileskin-1.jpg changes, where 536 is the hero id and - 1 is the skin name of the picture.
Now that we have the rules, we can combine the variables of the picture link with its corresponding skin name into a tuple. That's all for the analysis before crawling. Next, we officially start the actual combat.
Actual combat drill
Our basic crawling idea is:
-
Obtain some information of heroes, such as hero name and id;
-
Get skin name and construct skin link;
-
Save the picture.
Get some information about heroes
First, we obtain the Ajax request of the hero list, and obtain the hero name and hero id through the request. The main code is as follows:
response=requests.get(url,headers=headers)
json=response.json()
for i in json:
nameid=i.get('ename')
name=i.get('cname') l
link_list=f'https://pvp.qq.com/web201605/herodetail/{nameid}.shtml'
get_data(link_list,name,nameid)First, we use the json() method to get json data and the get() method to get specific data information. Here, we get the hero name and hero id, then use the obtained hero id to construct the URL link of each hero page, and then transfer the obtained hero name, hero id and URL link to our defined get_ In the data() method. In this way, the first step of our climb is completed.
Get hero skin name and skin link
In the previous step, we have obtained the hero name, hero id and hero URL links. In this step, we need to use the obtained hero id and URL links to obtain the skin name and construct the skin links.
It should be noted that:
The code of the head part of the source code of the king glory web page is gbk, as shown in the following figure:

We use the method of requests library to see what the default code is similar to. The specific code is as follows:
import requests url = 'https://pvp.qq.com/web201605/herodetail/536.shtml' response = requests.get(url) print(response.encoding)
The operation result is: ISO-8859-1
Therefore, we should use the requests library to change the encoding of the output results, otherwise Chinese garbled code will occur, as shown in the following figure:
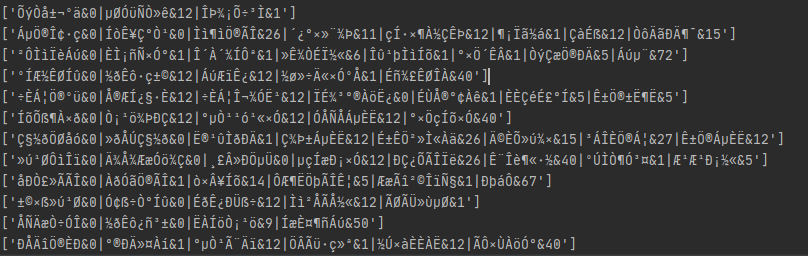
In order to avoid the Chinese random code in the figure above, we use the requests library to change the code of the output result. The specific code is as follows:
response.encoding = 'gbk' html=response.text
After changing the encoding of the output result, we start to obtain the hero skin name by constructing a regular expression object. The specific code is as follows:
patterm=re.compile('<ul.*?pic-pf-list.*?data-imgname="(.*?)">.*?</ul>',re.S)
skin_namelist=re.findall(patterm,html)We use the re.compile() method to construct a regular expression object, and then use the re.findall() method to find multiple matches and return a list.
The data obtained are as follows:
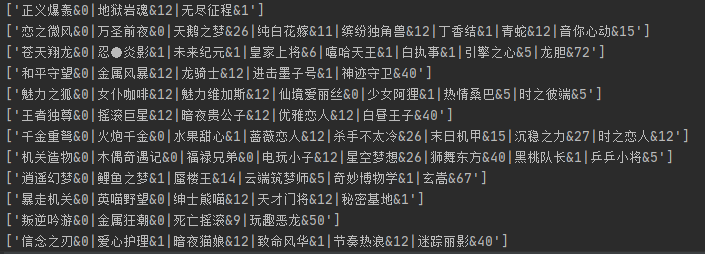
The initial skin name we obtained above obviously needs data processing. The main code of data processing is as follows:
for skin_name in skin_namelist:
skin=skin_name.replace('&','').replace('|','')
hero_skin=re.split('\d+',skin)
hero_skin_name=[i for i in hero_skin if i!='']
print(hero_skin_name)The operation results are shown in the figure below:

After obtaining the skin name, we will construct the skin URL link and store it in the list. The main code is as follows:
link_lisk=[]
for j in range(len(hero_skin_name)):
link = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{nameid}/{nameid}-bigskin-{j + 1}.jpg'
link_lisk.append(link)First, we create an empty list to store the skin URL links, and then increase the number of hero skin names to transform. After constructing the skin URL links, we will store the skin name and the corresponding skin URL links in the tuple. The main code is as follows:
link_skin_name_list = zip(link_lisk,hero_skin_name)
Here, we use python's built-in function zip(), whose parameters are skin URL link and skin name respectively.
Well, all the data we need have been obtained. Next, we need to start downloading all the king glory hero skins to the local folder.
Save picture
In the above steps, we have successfully obtained the hero name, hero skin name and skin URL links. Next, we begin to download all skins.
The main codes are as follows:
if not os.path.exists(name):
os.mkdir(name)
data=requests.get(skin_name_list[0],headers=headers).content
with open(f'{name}/{skin_name_list[1]}.jpg','wb')as f:
f.write(data)First, we judge whether there is a folder with the hero name as the file name. If it does not exist, we use the os.mkdir() method to create the folder, and the passed in parameter is the hero name. Then create a data variable to save the download information of each skin URL. Finally, use the write() method to write the data data to the folder.
Result display
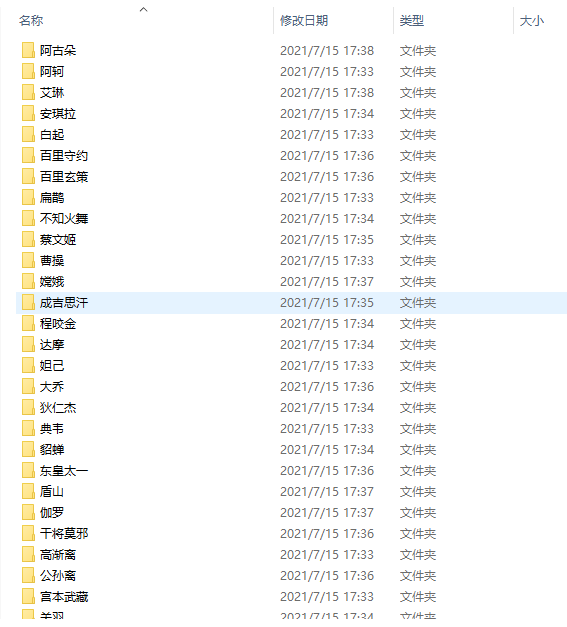

Well, that's all for crawling the skin picture of the king's glory hero. Then the problem comes. Which hero do you think is the most powerful and which skin feels the best!!!