1. A Brief Introduction to Data Crawling of Blog Biographical Comments on Station B
Today, I have been thinking for half a day about what to grab. I went to station B to see my little sister dancing. Suddenly I saw the comments. Then I grabbed the commentary data of station B. There are so many video animations and I don't know which to grab. I chose a blogger to pass on the comments related to the fire shadow. Website: https://www.bilibili.com/bangumi/media/md5978/?From=search&seid=160133881367636883#short
In this page, I saw 18560 short reviews, and the amount of data is not large, so scrapy is still used.

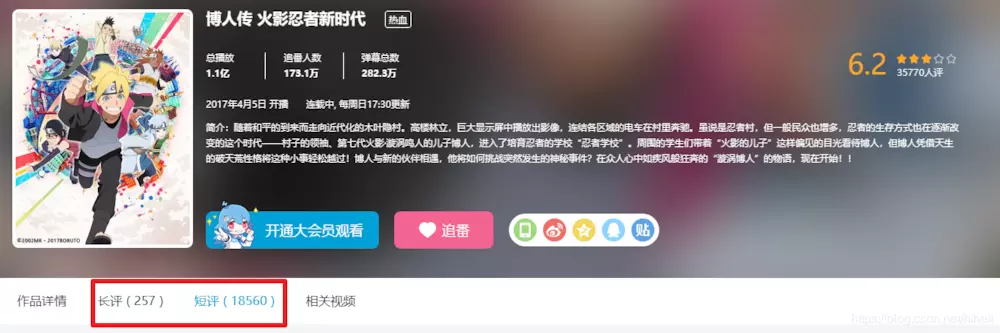
2. B Blog Biographical Comments Data Case - Getting Links
From the developer tools, you can easily get the following links, links are easy to do, how to create a project is no longer verbose, we go directly to the topic.
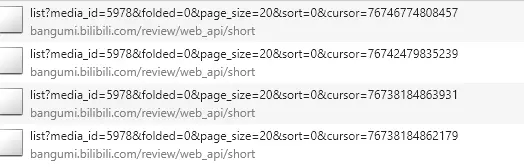
In the parse function in the code, I set two yield s, one to return items and one to return requests.
Then we implement a new function, switching UA every time we visit, which we need to use middleware technology.
class BorenSpider(scrapy.Spider):
BASE_URL = "https://bangumi.bilibili.com/review/web_api/short/list?media_id=5978&folded=0&page_size=20&sort=0&cursor={}"
name = 'Boren'
allowed_domains = ['bangumi.bilibili.com']
start_urls = [BASE_URL.format("76742479839522")]
def parse(self, response):
print(response.url)
resdata = json.loads(response.body_as_unicode())
if resdata["code"] == 0:
# Get the last data
if len(resdata["result"]["list"]) > 0:
data = resdata["result"]["list"]
cursor = data[-1]["cursor"]
for one in data:
item = BorenzhuanItem()
item["author"] = one["author"]["uname"]
item["content"] = one["content"]
item["ctime"] = one["ctime"]
item["disliked"] = one["disliked"]
item["liked"] = one["liked"]
item["likes"] = one["likes"]
item["user_season"] = one["user_season"]["last_ep_index"] if "user_season" in one else ""
item["score"] = one["user_rating"]["score"]
yield item
yield scrapy.Request(self.BASE_URL.format(cursor),callback=self.parse)
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
3. Data Case of Blog Biographical Comments on Station B-Realizing Random UA
The first step is to add some User Agents to the settings file. I found some from the Internet.
USER_AGENT_LIST=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
The second step is to set "DOWNLOADER_MIDDLEWARES" in the settings file.
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
#'borenzhuan.middlewares.BorenzhuanDownloaderMiddleware': 543,
'borenzhuan.middlewares.RandomUserAgentMiddleware': 400,
}
Third, import the USER_AGENT_LIST method in the settings module in the middlewares.py file
from borenzhuan.settings import USER_AGENT_LIST # Import Middleware
import random
class RandomUserAgentMiddleware(object):
def process_request(self, request, spider):
rand_use = random.choice(USER_AGENT_LIST)
if rand_use:
request.headers.setdefault('User-Agent', rand_use)
OK, random UA has been implemented. You can write the following code in the parse function for testing.
print(response.request.headers)
4. B logger Comment Data of Station B - Perfecting Items
This operation is relatively simple, these data are the data we want to save.
author = scrapy.Field()
content = scrapy.Field()
ctime = scrapy.Field()
disliked = scrapy.Field()
liked = scrapy.Field()
likes = scrapy.Field()
score = scrapy.Field()
user_season = scrapy.Field()
5. B Blog Biographical Comments Data Case - Increasing Climbing Speed
In settings.py, set the following parameters:
# Configure maximum concurrent requests performed by Scrapy (default: 16) CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 1 # The download delay setting will honor only one of: CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) COOKIES_ENABLED = False
interpretative statement
1. Reducing download latency
DOWNLOAD_DELAY = 0
When the download delay is set to 0, corresponding anti-ban measures are needed. User agent rotation is generally used to construct user agent pool, and one of them is chosen as user agent in turn.
II. Multithreading
CONCURRENT_REQUESTS = 32
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
Scapy network requests are based on Twisted, and Twisted supports multi-threading by default, and scrapy also supports multi-threading requests by default, and supports multi-core CPU concurrency. We can improve the crawling speed by increasing the number of concurrencies of scrapy through some settings.
3. Disabling cookies
COOKIES_ENABLED = False
6. B Blog Biographical Review Data Case - Preserving Data
Finally, in the pipelines.py file, you can write the save code.
import os
import csv
class BorenzhuanPipeline(object):
def __init__(self):
store_file = os.path.dirname(__file__)+'/spiders/bore.csv'
self.file = open(store_file,"a+",newline="",encoding="utf-8")
self.writer = csv.writer(self.file)
def process_item(self, item, spider):
try:
self.writer.writerow((
item["author"],
item["content"],
item["ctime"],
item["disliked"],
item["liked"],
item["likes"],
item["score"],
item["user_season"]
))
except Exception as e:
print(e.args)
def close_spider(self, spider):
self.file.close()
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
After running the code, it was found that the error was reported after a while.
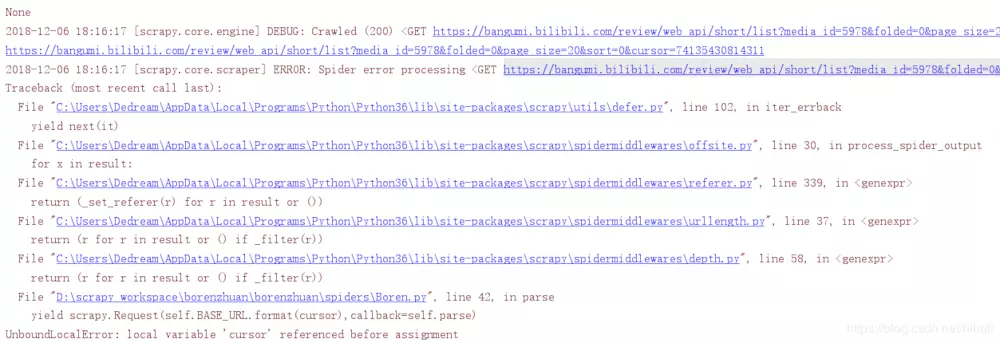
Look at it, it's data crawling!!!