Python crawler: make its own IP proxy module 2
Xiaobian wrote a blog about IP proxy module a few days ago( Python crawler: make your own IP proxy module
), but that still needs improvement. Today, Xiaobian improved that module, crawling the ip data of multiple URLs, then de duplication, and finally judge whether the crawling ip is available. Let's take a look at the difference between the previous module and the improved module!

1. Crawl three free ip proxy websites
The three ip proxy websites are: Fast agent,Nima ip agent,89 free agent
1.1 crawl the IP data of the proxy web address
First, let's crawl the IP data of the fast proxy!
The website style of express agent is: https://www.kuaidaili.com/free/inha/ {page}/
Curly brackets represent page numbers. There are many page numbers in this website, with more than 4000 pages.
Let's see how to get the ip data of this website! The xpath syntax is used here
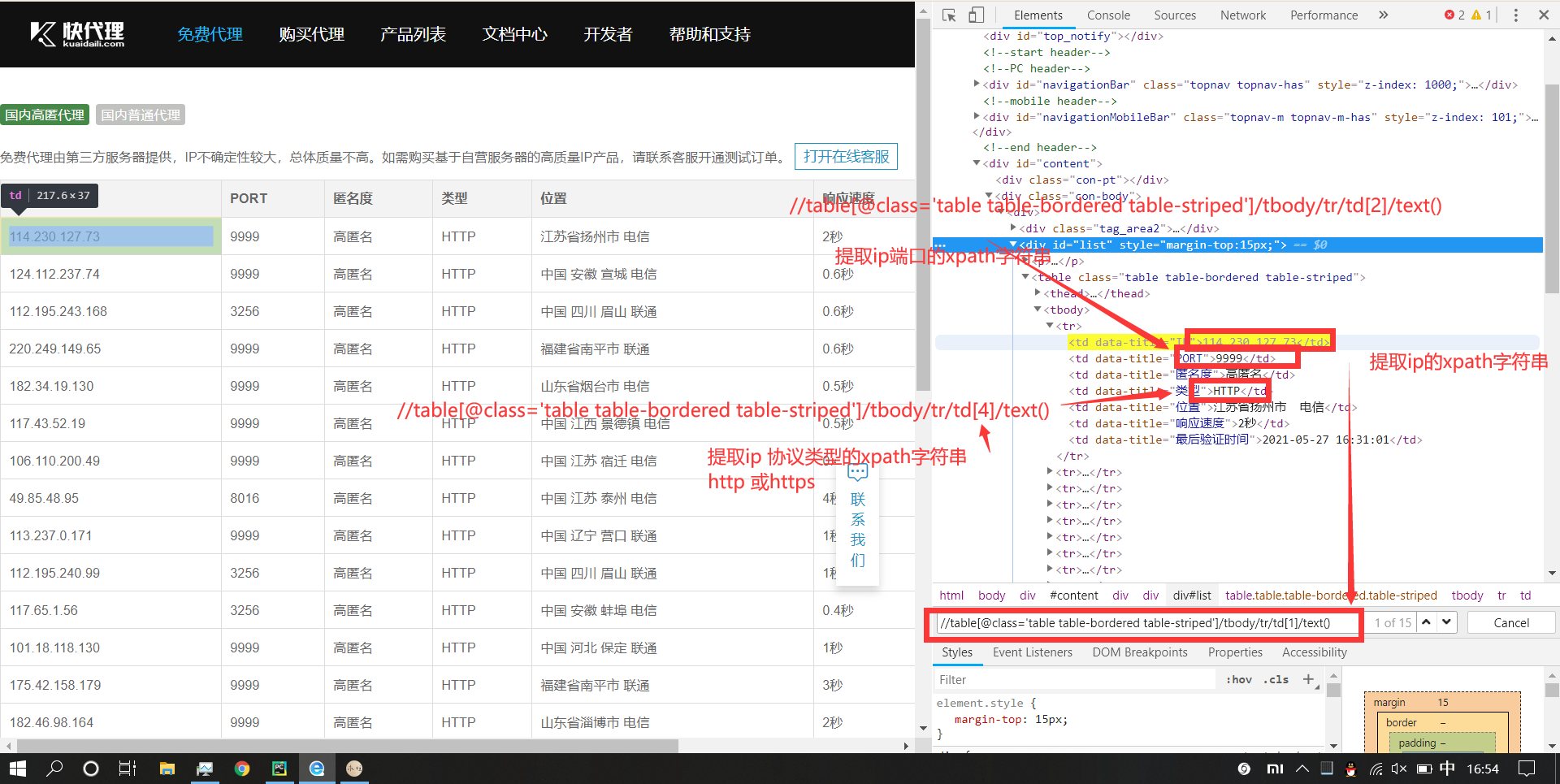
Because this protocol type is in uppercase letters, the small page does not know whether this will affect the final result, so it is simply converted to lowercase letters.
The code is:

It should be that the crawling is multi page ip data. After crawling one page, the Xiaobian is dormant for 2 seconds.
1.2 crawl the IP data of NIMA IP proxy website
The style of this website is the same as that of fast proxy: http://www.nimadaili.com/gaoni/ {page}/
The content in curly brackets is the page number, although the website is marked with 2000 pages

But there are only more than 300 pages of ip data.
Now let's see how to get the ip data of this website!

For some ip, only one protocol can be used (this is the case for most ip). For some ip, both protocols can be used. Here, for simplicity, select one ip protocol directly (if both protocols are available, select the first one). Similarly, the case of the string should also be converted here.

1.2 crawl the IP data of 89 free proxy website

The URL style is: https://www.89ip.cn/index_ {page} html
Curly brackets represent page numbers, and the total number of valid pages is more than 100. The specific reference of crawling this ip data is as follows:

Because the ip protocol type is not mentioned in the website, the two types (HTTP and HTTPS) are directly spliced here. There are line breaks and spaces in front and behind the crawled information, so the string should be intercepted during the final splicing,

2. Verify whether the crawled ip is available
Baidu is still used here to check whether the crawling ip is available. In order to improve the inspection efficiency, multithreading is used.
Reference codes are as follows:
def checkIps(self,ips):
while True:
if len(ips)==0:
break
proxies=ips.pop()
headers = {'user-agent': self.userAgent.getUserAgent()}
try:
rsp=requests.get(url=self.url,headers=headers,proxies=proxies,timeout=0.5) # Set timeout
if(rsp.status_code==200):
self.userfulProxies.append(proxies)
print('========IP{}available'.format(proxies)) # If the test needs, it can not be commented out
time.sleep(1) # Sleep for 1 second
except Exception as e:
print(e)
print('========IP{}Not available'.format(proxies)) # For testing, you can log out
def getUserIps(self): # Get available ip data
self.spiderIps()
ips=self.proxies[:]
# The total number of ip crawls is hundreds, and 10 threads are used
threads=[]
for i in range(10):
thread=threading.Thread(target=self.checkIps,args=(ips,))
thread.start()
threads.append(thread)
for th in threads:
th.join()
print('IP test completed!') # ip test completed!
print('(The number of available IPs is:[%d])' % len(self.userfulProxies)) # The total number of valid IPS is
print('IP proxy efficiency is--{:.2f}%'.format((len(self.userfulProxies)/len(self.proxies))*100)) # Crawl ip efficiency
return self.userfulProxies # Return available ip data
Operation results:

3. Final actual combat: use ip agent to crawl 500 pages of little sister's pictures on Jitu
The last time I used the ip proxy module at the beginning, I couldn't use the URL directly. Now I think it must be available. after all

and

Start crawling (here we only calculate the availability of this ip proxy module, only crawl the image link, and do not download the image. However, if you want to download the image, isn't it also a line of code? Ha ha)
Reference codes are as follows:
import requests
from crawlers.userAgent import useragent # Import your own custom class. Its main function is to randomly take the value of user agent
from lxml import etree
from Craw_2.Test.wenti1 import IPs # Import ip proxy module
ip=IPs()
proxiess=ip.getUserIps()
userAgent=useragent()
url='http://www.jituwang.com/sucai/meinv-7559813-%d.html'
i=1
proxies=proxiess.pop()
print('Start crawling')
while i<501:
try:
headers = {'user-agent': userAgent.getUserAgent()}
rsp=requests.get(url=url%(i),headers=headers,proxies=proxies,timeout=1)
if rsp.status_code==200:
print(proxies,i)
html=etree.HTML(rsp.text)
hrefs=html.xpath("//div[@class='boxMain']//li/a//img/@src")
print(hrefs)
i+=1
except Exception as e:
if len(proxiess)==0:
break
proxies = proxiess.pop()
print(e)
Operation results:
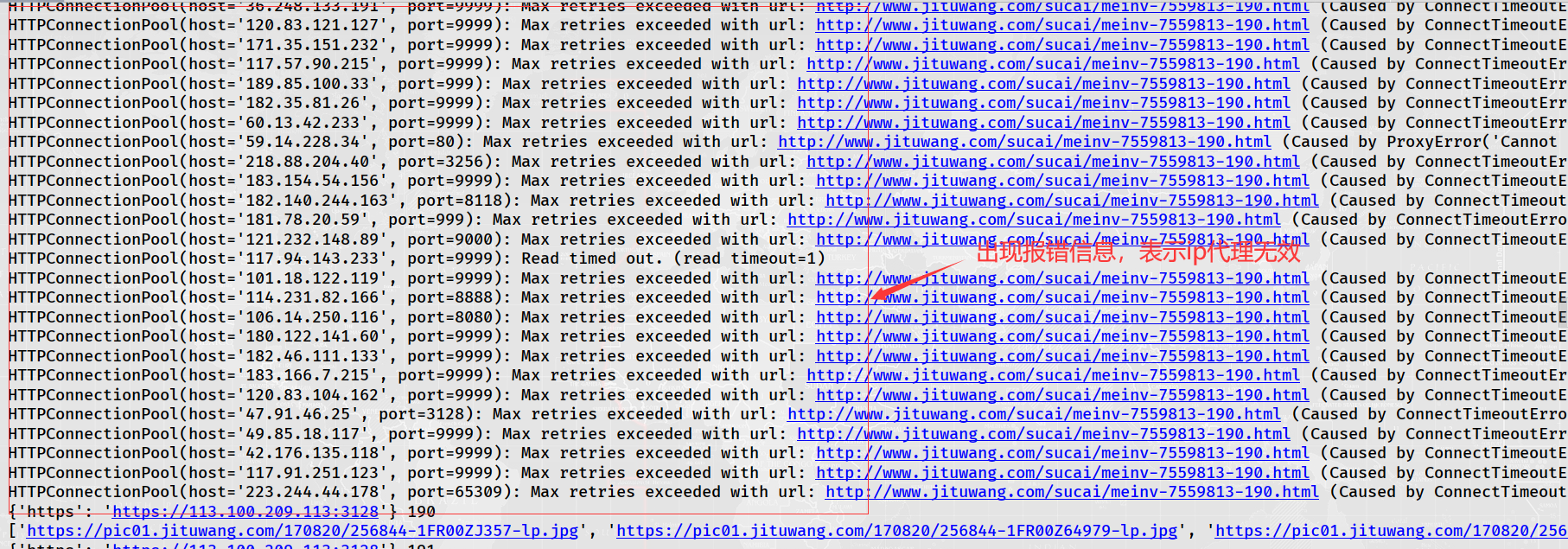
Because free ip has timeliness, crawling ip is not necessarily available when used.
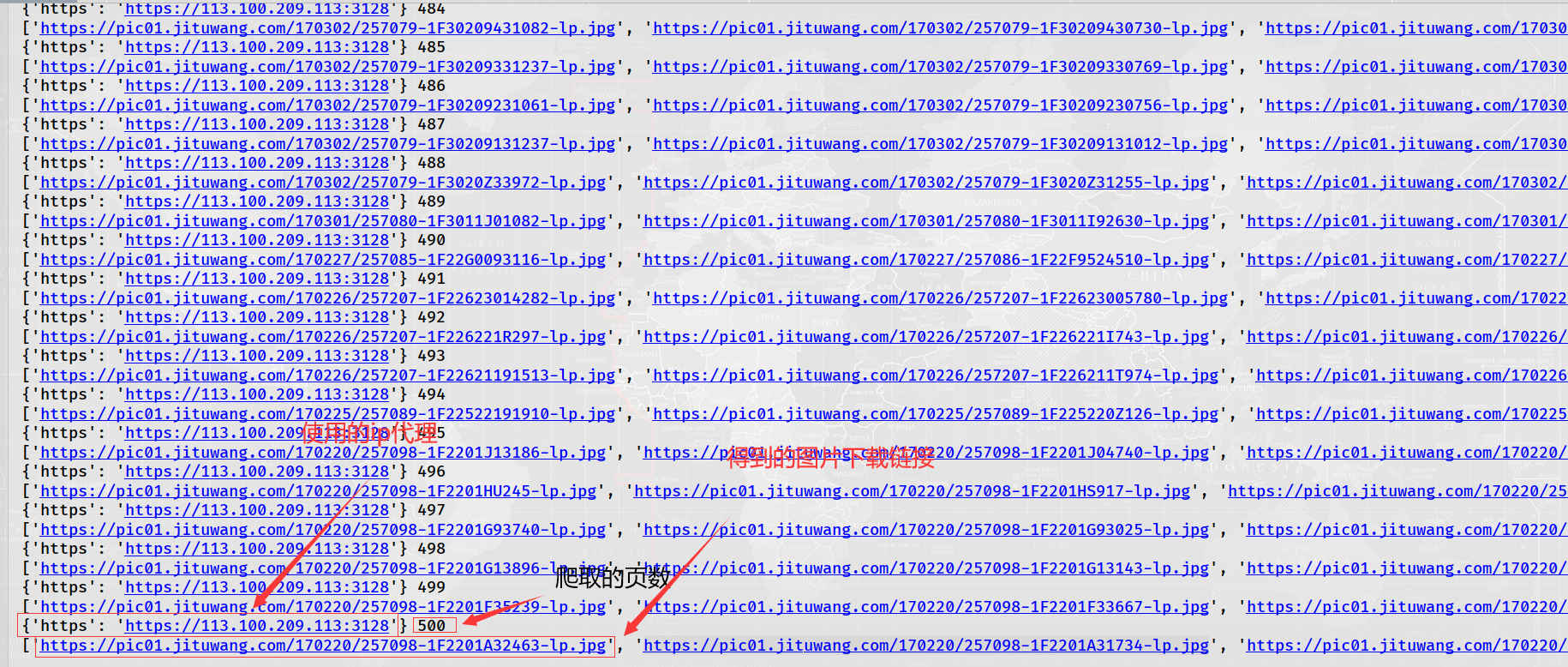
We click one of the picture links to enter:
The link is: https://pic01.jituwang.com/201028/144489-20102Q35I377-lp.jpg

We found that the size of the picture is too small. We click the picture on the original website, find the link of the picture on it, and click to enter. We found that the size of the picture has become larger,
The URL link is: https://img01.jituwang.com/201028/144489-20102Q35I377.jpg

Comparing the above two links, it is found that the other parts are the same except that the head and tail of the link are a little different. We can use string splicing and string interception to get a large picture.
Xiaobian doesn't use multithreading here, so the download connection speed of crawling these pictures is very slow. Interested readers can try to use multithreading and add this ip proxy to climb the link! It must be a lot faster.
From the above use of IP proxy, you can know that if you don't use IP proxy, your IP may have been blocked before you climb to page 500. Therefore, you can see the importance of using IP proxy.
The source code of the ip proxy module has been uploaded to gitee. The link is: ips2.py , readers who want the source code can download it by themselves!
4. Summary
The ip proxy module of Xiaobian has been greatly improved compared with the previous one. To improve, we need to add a few more ip proxy URLs to improve the quality of crawling ip. If you think you can participate in this plan, you can still join it!