Official account: Special House
Author: Peter
Editor: Peter
Hello, I'm Peter~
Recently, the divorce between Wang and Li has been making a lot of noise. I believe everyone has eaten a lot of melons. This article combines the comments of netizens below Li's first article to see how everyone views this matter.

Webpage
Crawl field
- User nickname
- Comment time
- Comment content
- Number of likes
- Number of replies
- Gender
- city
Data from this address: https://weibo.com/5977512966/L6w2sfDXb#comment

Crawl all of the following comments:
Web law
The microblog web page belongs to Ajax rendering. When we slide down, the comments will be displayed. The URL of the address bar remains unchanged. We need to find the actual request URL.
1. Right click Check to find Network

2. Determine the content URL for each page
Here is the home page

Display the URL of each page after sliding;

3. URL address per page
start_url = "https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4715531283728505&is_show_bulletin=2&is_mix=0&count=10&uid=5977512966" # 2: Max returned with the first page_ ID as parameter value url2 = "https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4715531283728505&is_show_bulletin=2&is_mix=0&max_id=22426369418746150&count=20&uid=5977512966" # 3: Max returned with the second page_ ID as parameter value url3 = "https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4715531283728505&is_show_bulletin=2&is_mix=0&max_id=2197966808100516&count=20&uid=5977512966"
The part with more URL addresses from the second page is max_id, just the value of this parameter is the return content of the previous page:
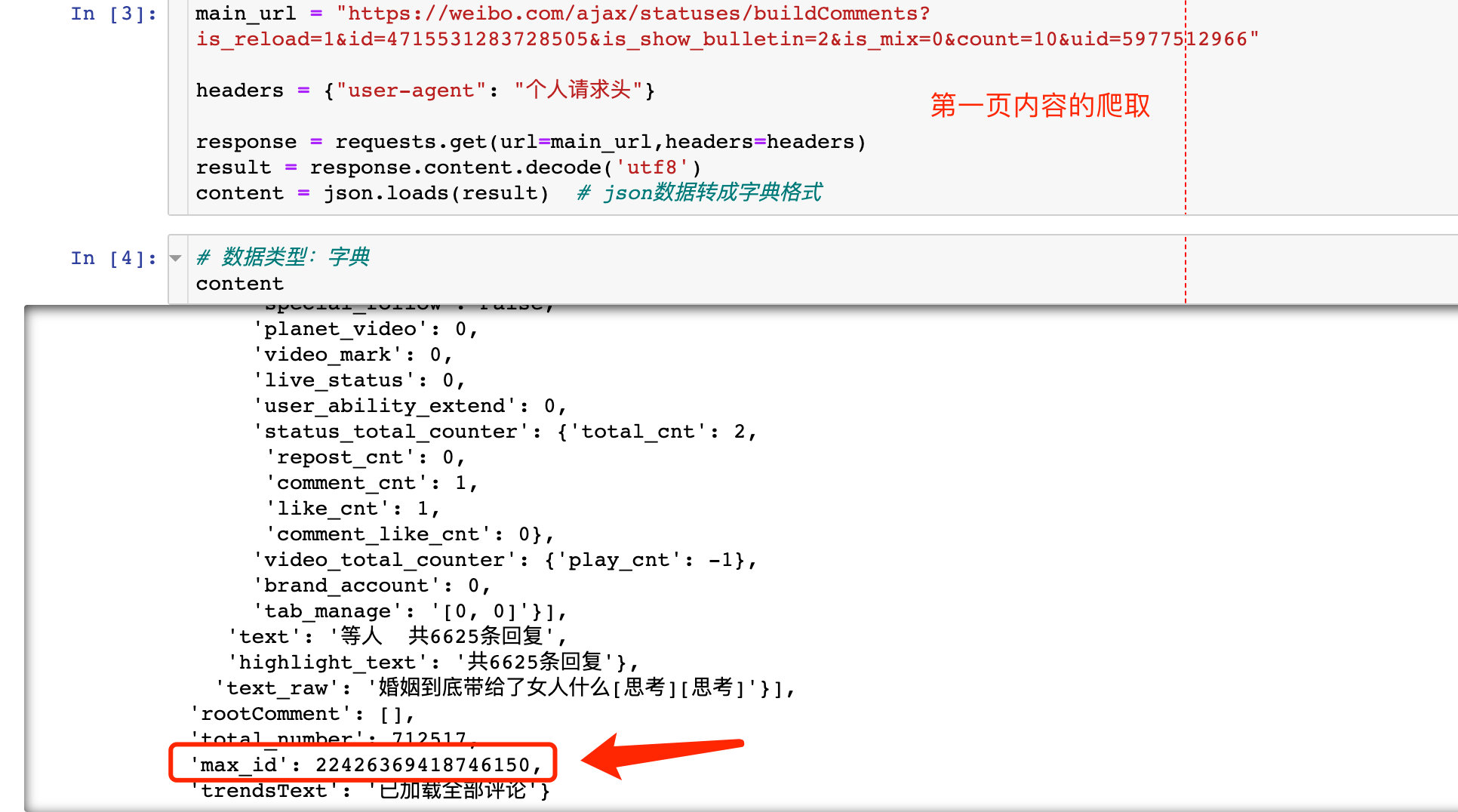
4. Introduction to crawling on page 1
main_url = "https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4715531283728505&is_show_bulletin=2&is_mix=0&count=10&uid=5977512966"
headers = {"user-agent": "Personal request header"}
response = requests.get(url=main_url,headers=headers)
result = response.content.decode('utf8')
content = json.loads(result) # Convert json data to dictionary format
For example, we can get the relevant information of the first user:

Finally, we can see the data display crawled on the first page:
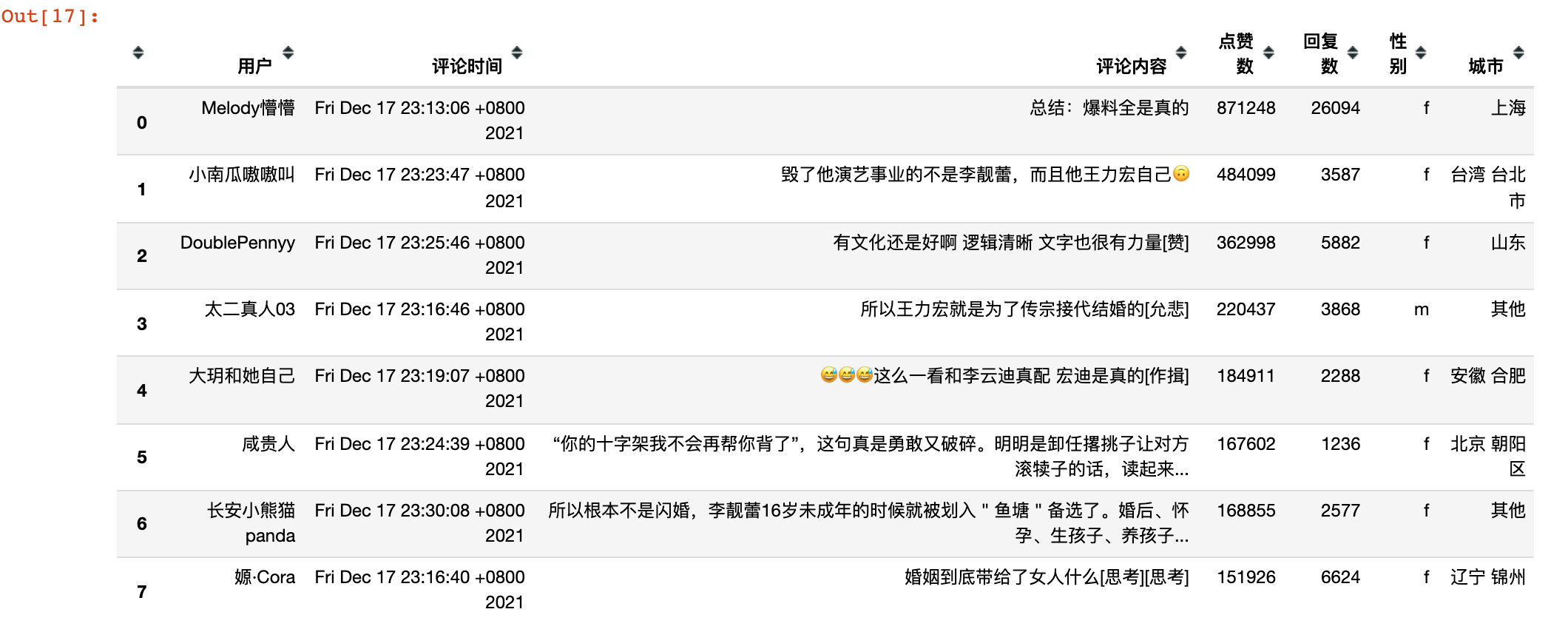
Referring to the above logic, you can crawl to all the comments under the microblog
Microblog analysis
Import library
Import required libraries:
import pandas as pd
import numpy as np
import jieba
from snownlp import SnowNLP
# Show all columns
# pd.set_option('display.max_columns', None)
# Show all rows
# pd.set_option('display.max_rows', None)
# Set the display length of value to 100, and the default is 50
# pd.set_option('max_colwidth',100)
# Drawing related
import matplotlib.pyplot as plt
from pyecharts.globals import CurrentConfig, OnlineHostType
from pyecharts import options as opts # Configuration item
from pyecharts.charts import Bar, Scatter, Pie, Line,Map, WordCloud, Grid, Page # Classes for each drawing
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType,SymbolType
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots # Draw subgraph
Data EDA
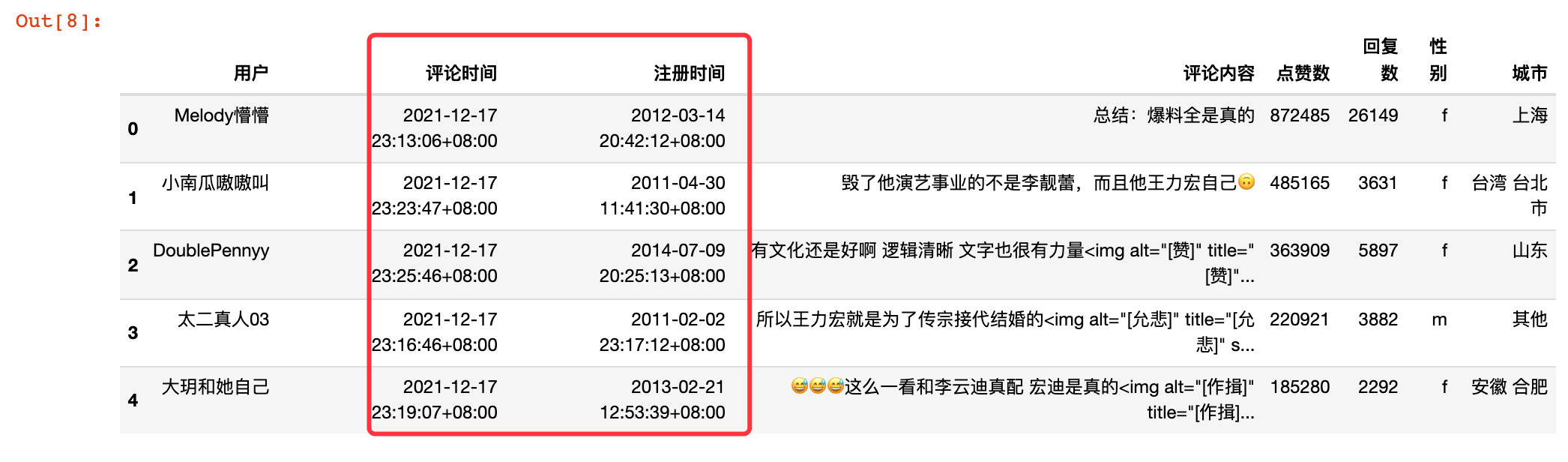
View the basic information of the data we crawled. We import the first 5 rows of data:

Basic information: view the shape shape of the data, with a total of 47638 rows and 8 fields, and there are no missing values.

Time preprocessing
Turn the Greenwich time we climbed into a familiar standardized time form:
import datetime
def change_time(x):
"""
Greenwich mean time format----->Specified time format
"""
std_transfer = '%a %b %d %H:%M:%S %z %Y'
std_change_time = datetime.datetime.strptime(x, std_transfer)
return std_change_time
df["Comment time"] = df["Comment time"].apply(change_time)
df["Registration time"] = df["Registration time"].apply(change_time)
df.head()
Other processing
- Remove the img part of the comment
- For crawling cities, we extract the provinces or municipalities directly under the central government. If it is foreign, the direct value is overseas
df["Comment content"] = df["Comment content"].apply(lambda x:x.split("<img")[0])
df["province"] = df["city"].apply(lambda x:x.split(" ")[0])
df.head()
Regional melon competition
fig = px.bar(df1[::-1],
x="user",
y="province",
text="user",
color="user",
orientation="h"
)
fig.update_traces(textposition="outside")
fig.update_layout(title="Distribution of microblog comments on cities",width=800,height=600)
fig.show()
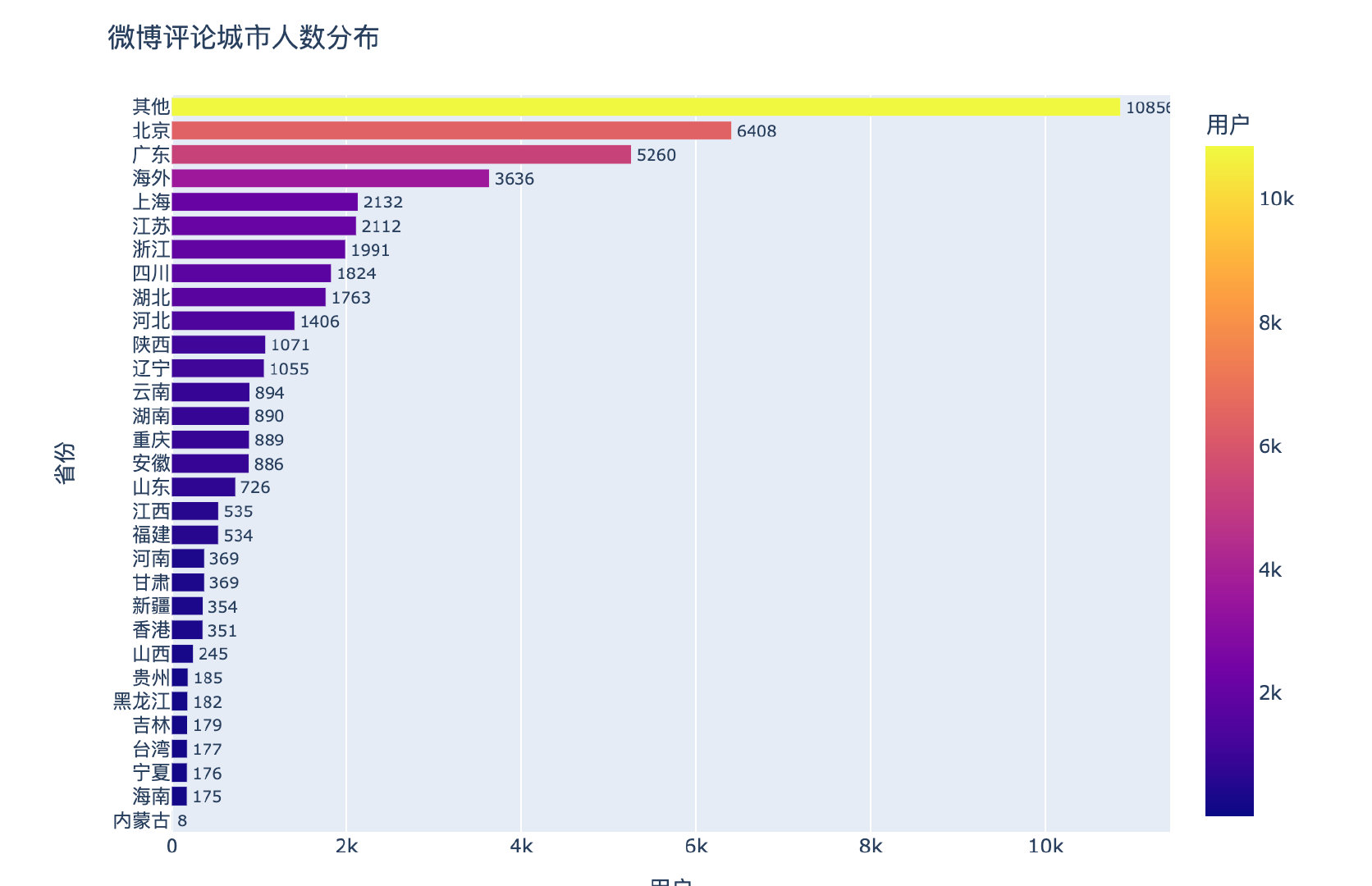
Among the domestic provinces, Beijing, Guangdong, Shanghai and Jiangsu are all big melon eating provinces!
Gender competition
df2 = df.groupby("Gender")["user"].count().reset_index()
fig = px.pie(df2,names="Gender",values="user",labels="Gender")
fig.update_traces(
# Text display position: ['inside ',' outside ',' auto ',' none ']
textposition='inside',
textinfo='percent+label'
)
fig.show()
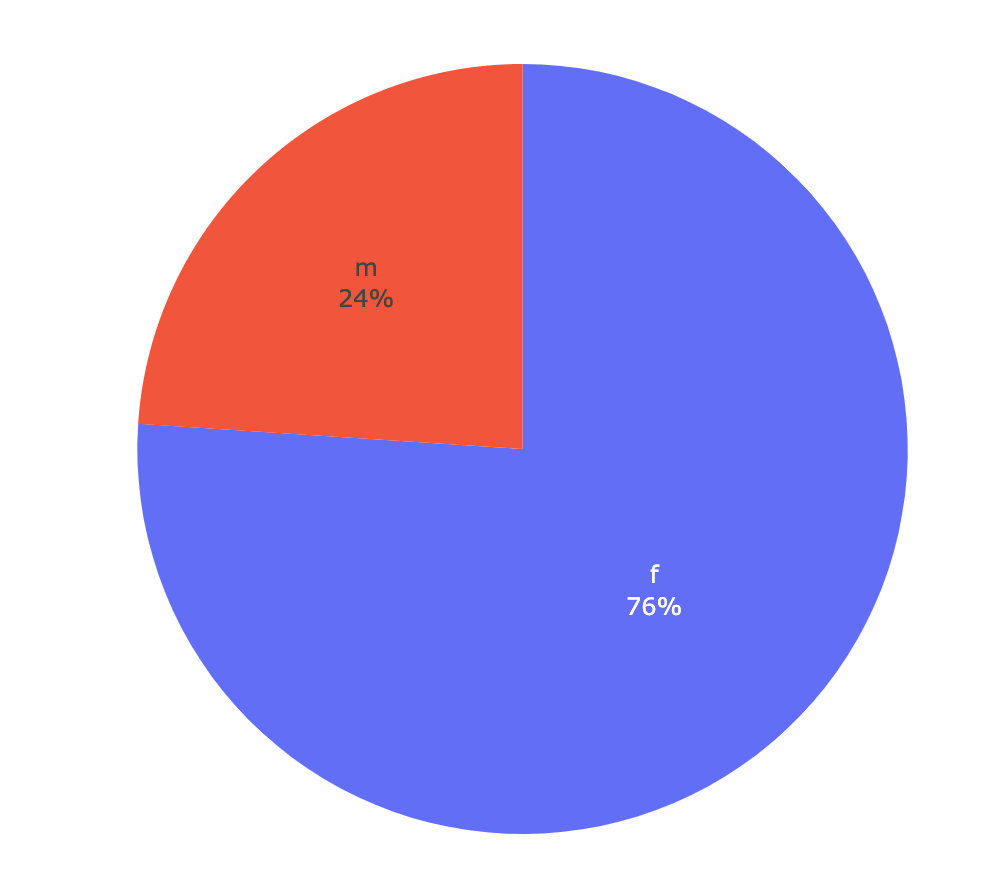
Sure enough: women really like melons 🍉 Far more than men
Hot comments
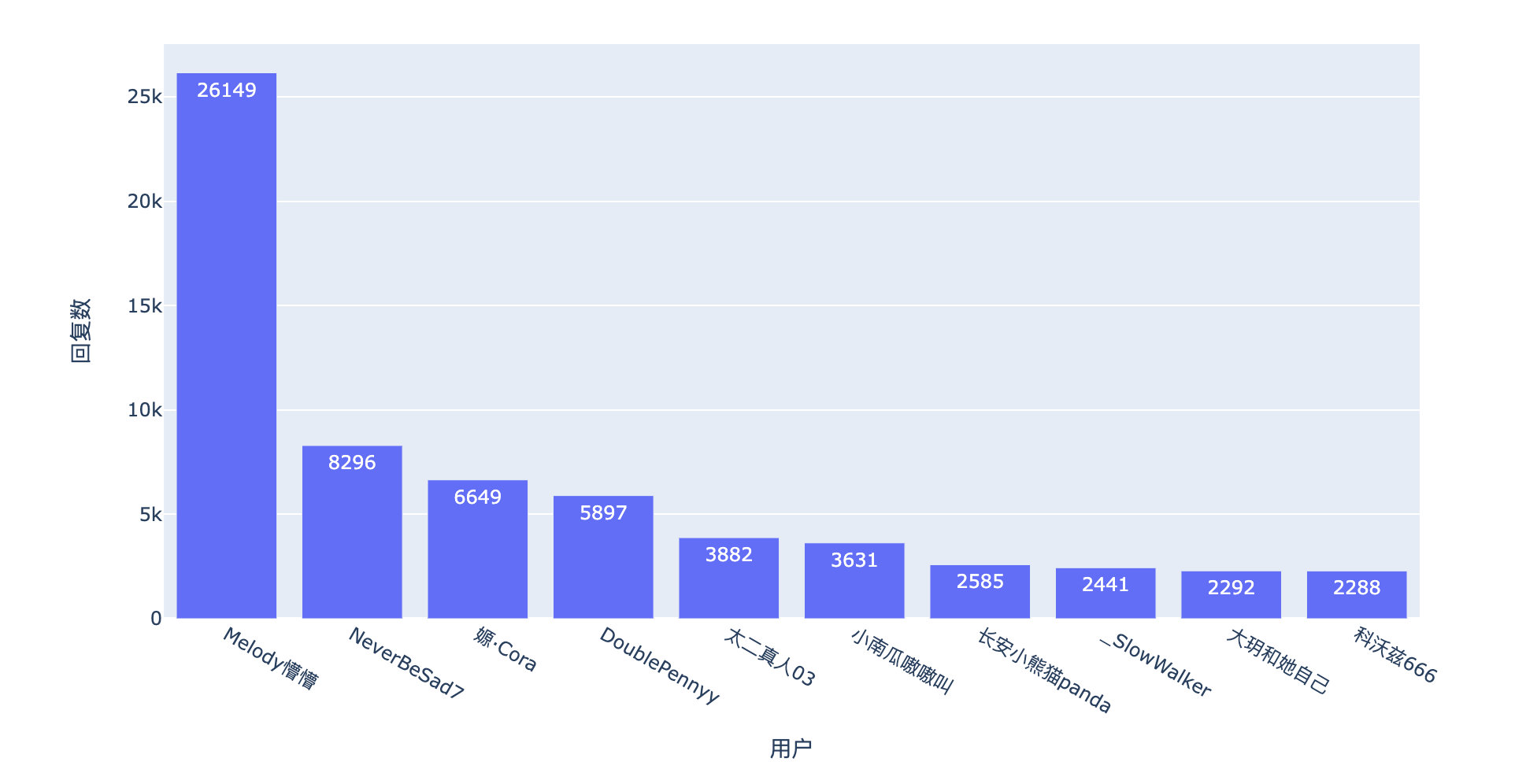
Look at the popular comments under this microblog through the number of likes and replies:
Number of likes
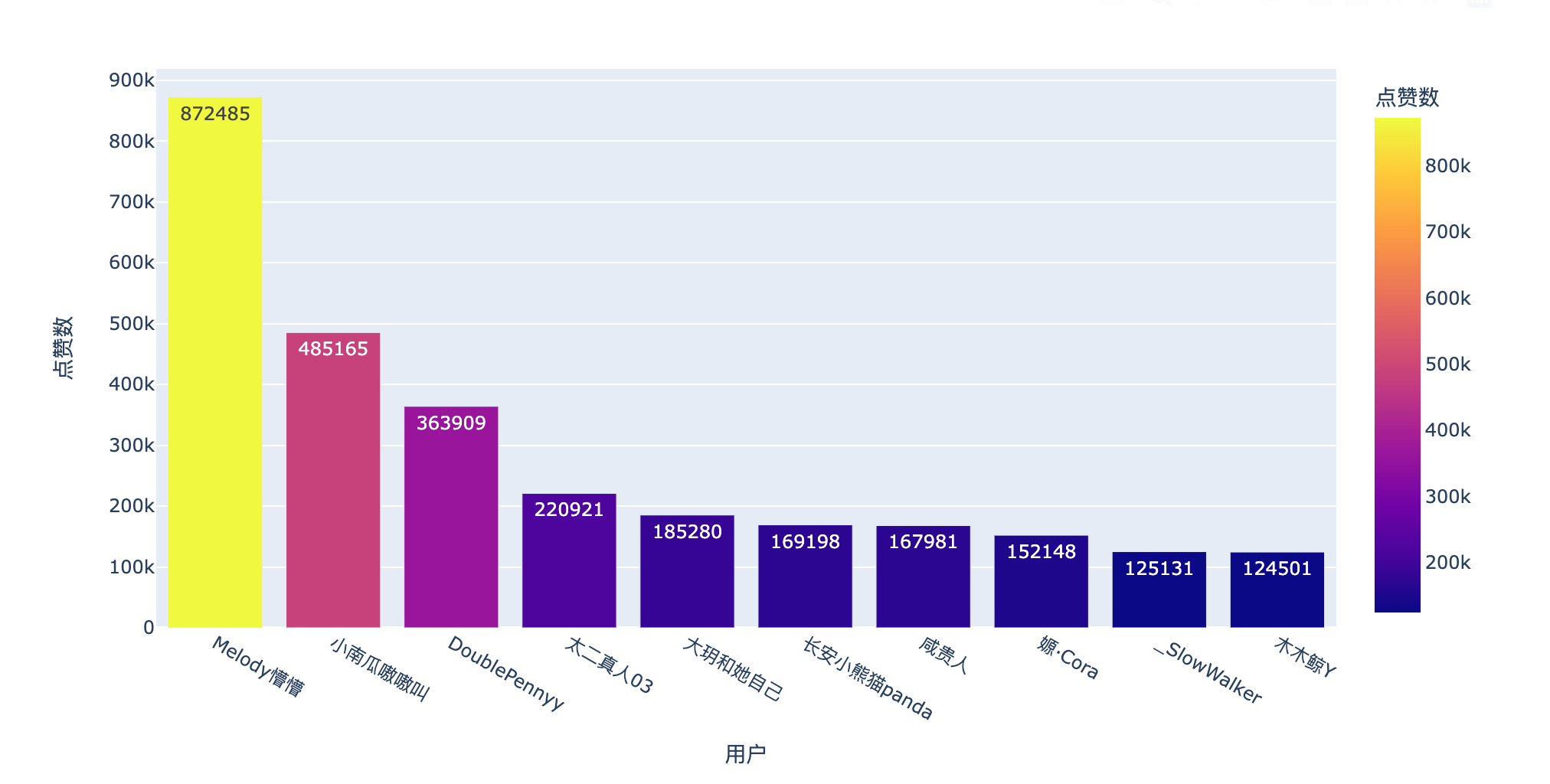
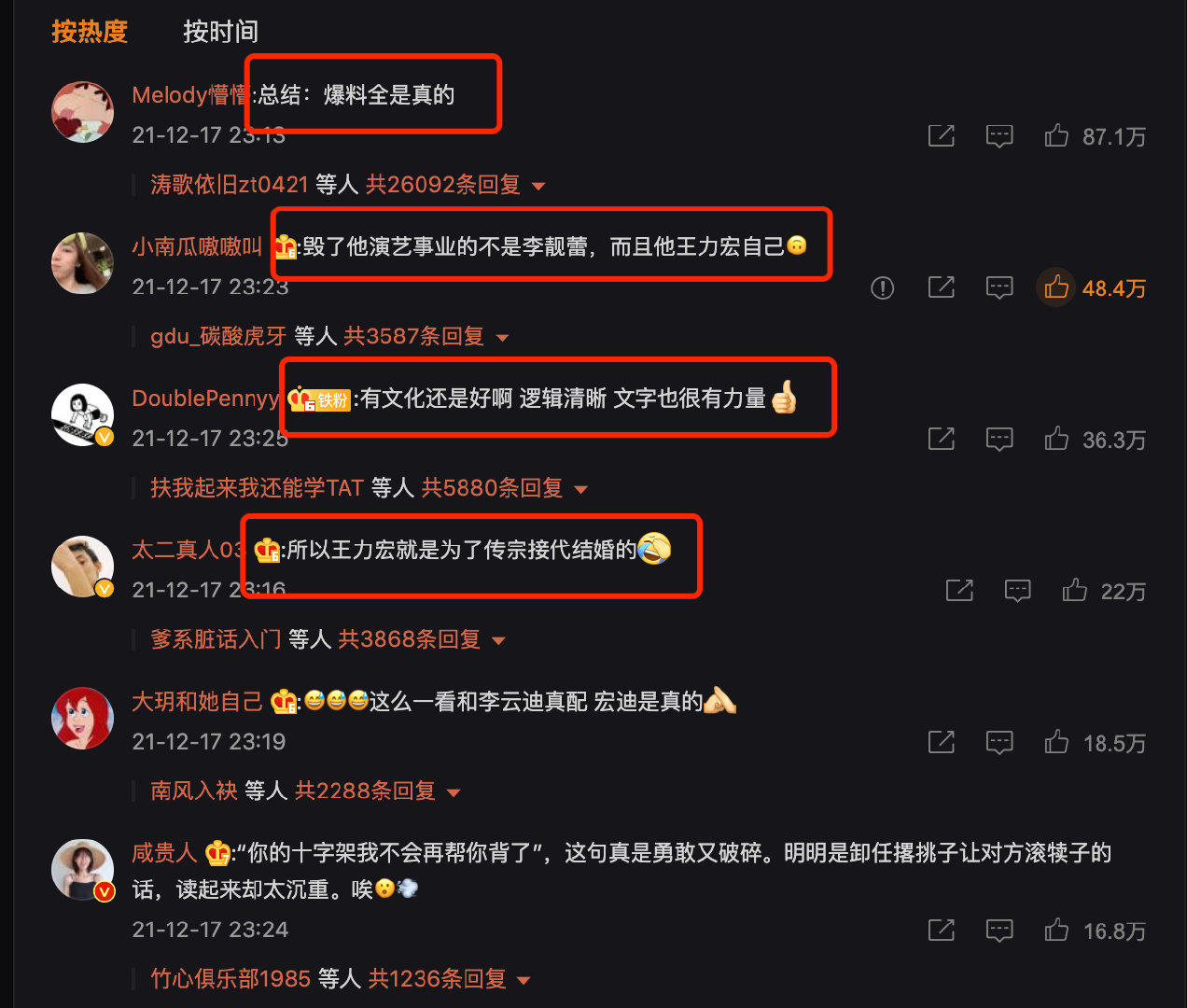
A netizen commented on 870000 + likes! six hundred and sixty-six
Number of replies
It is also the comment of this netizen, and the number of replies is No.1
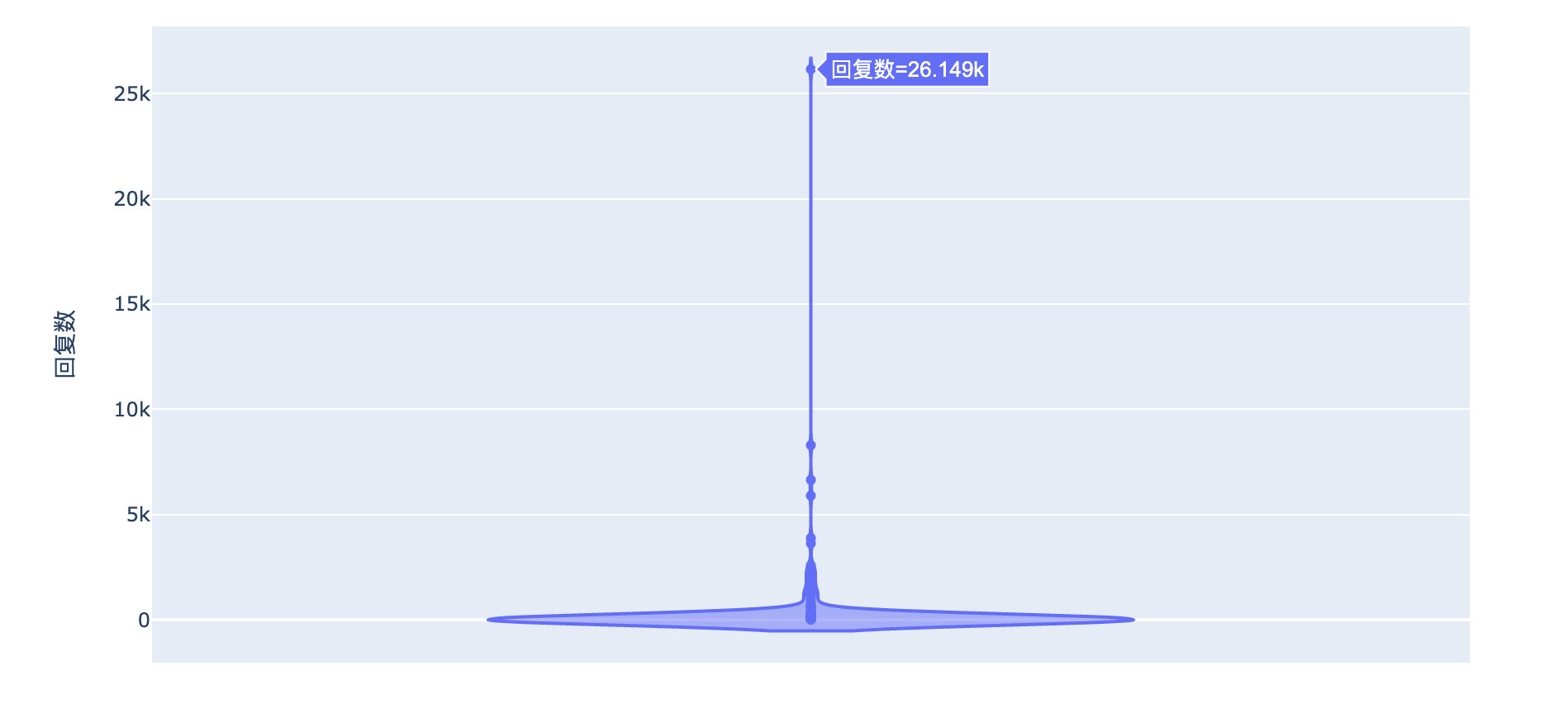
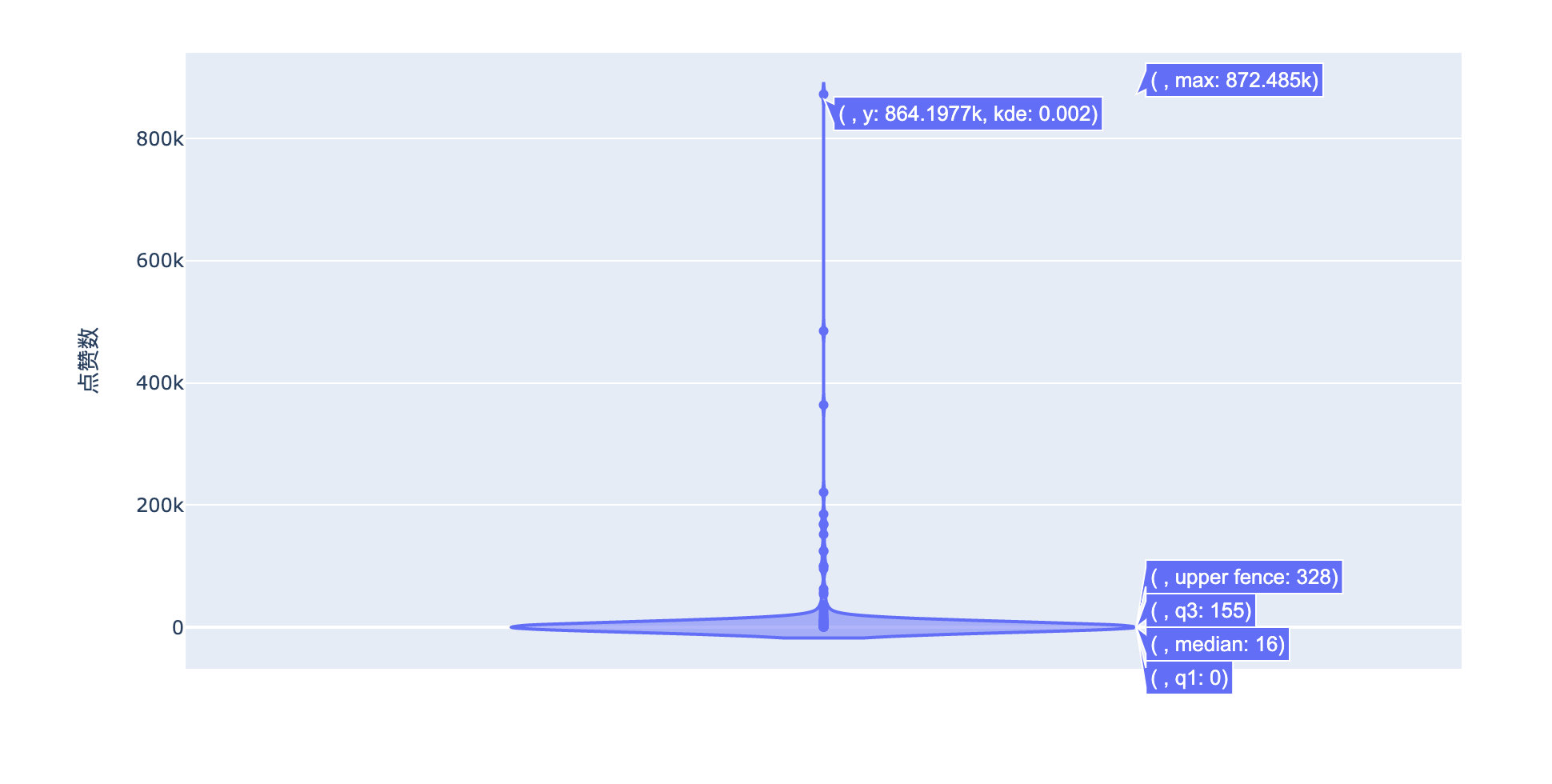
From the overall distribution of likes and replies, this comment is really unique! Has completely deviated from other data:
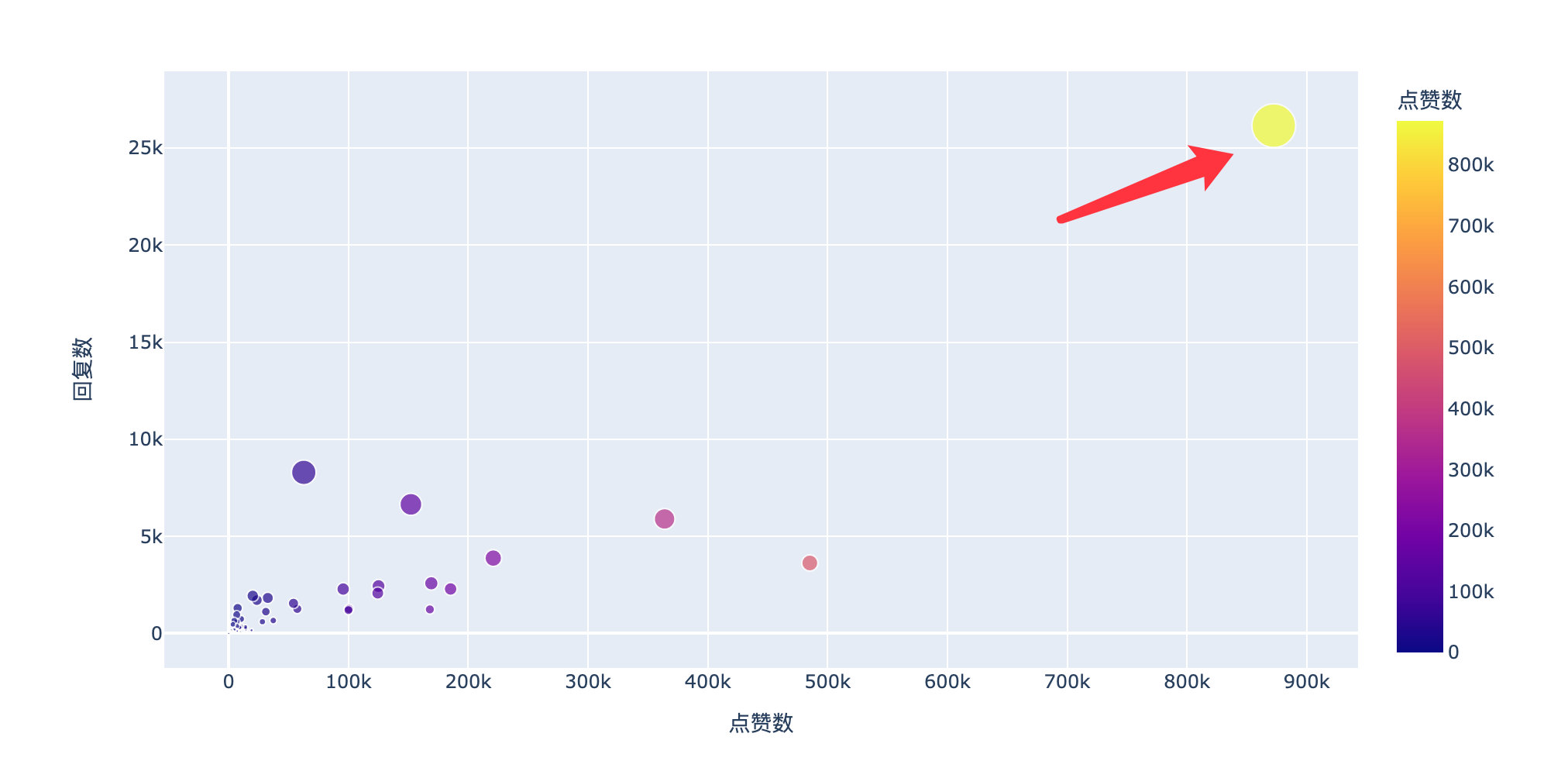
Looking at the original data, we found that this comment is:
Conclusion: the revelations are all true
It seems that many previous revelations have been hammered!
Microblog user age
df["interval"] = df["Comment time"] - df["Registration time"] # time interval
df["day"] = df["interval"].apply(lambda x:x.days) # days property of timedelta
df["year"] = df["day"].apply(lambda x:str(int( x / 365)) + "year") # Microblog age rounding; Less than one year
px.scatter(df,
x="Number of likes",
y="Number of replies",
size="day",
facet_col="year",
facet_col_wrap=4, # Up to 4 graphics per line
color="year")
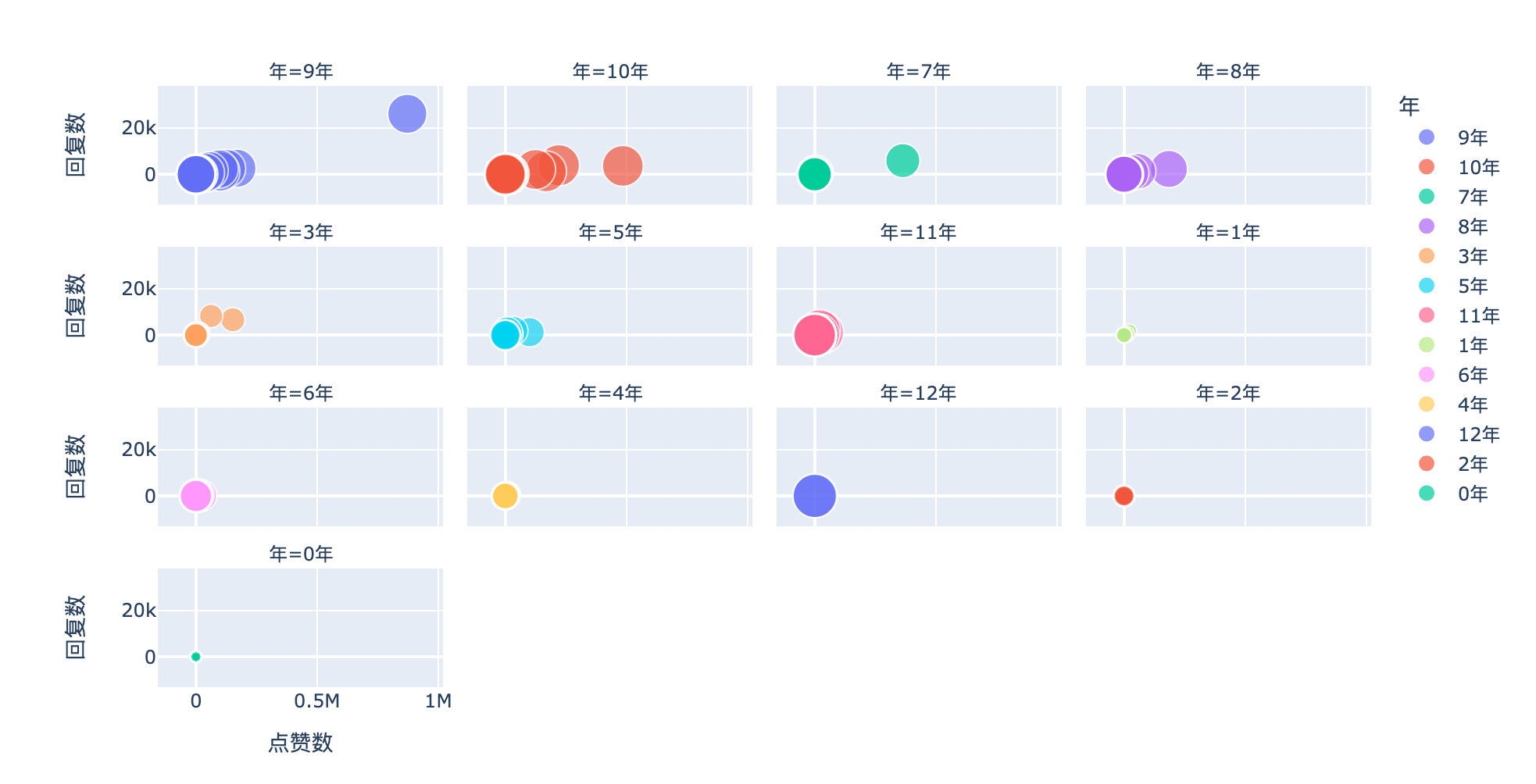
According to the user's age, number of likes and replies, users aged 7, 8, 9 and 10 are more active; Older or new microblog users have less comments.
At the same time, the number of likes is also concentrated in the part between 2000 and 5000
Comment time
px.scatter(df,
x="Comment time",
y="day",
color="year",
size="day")
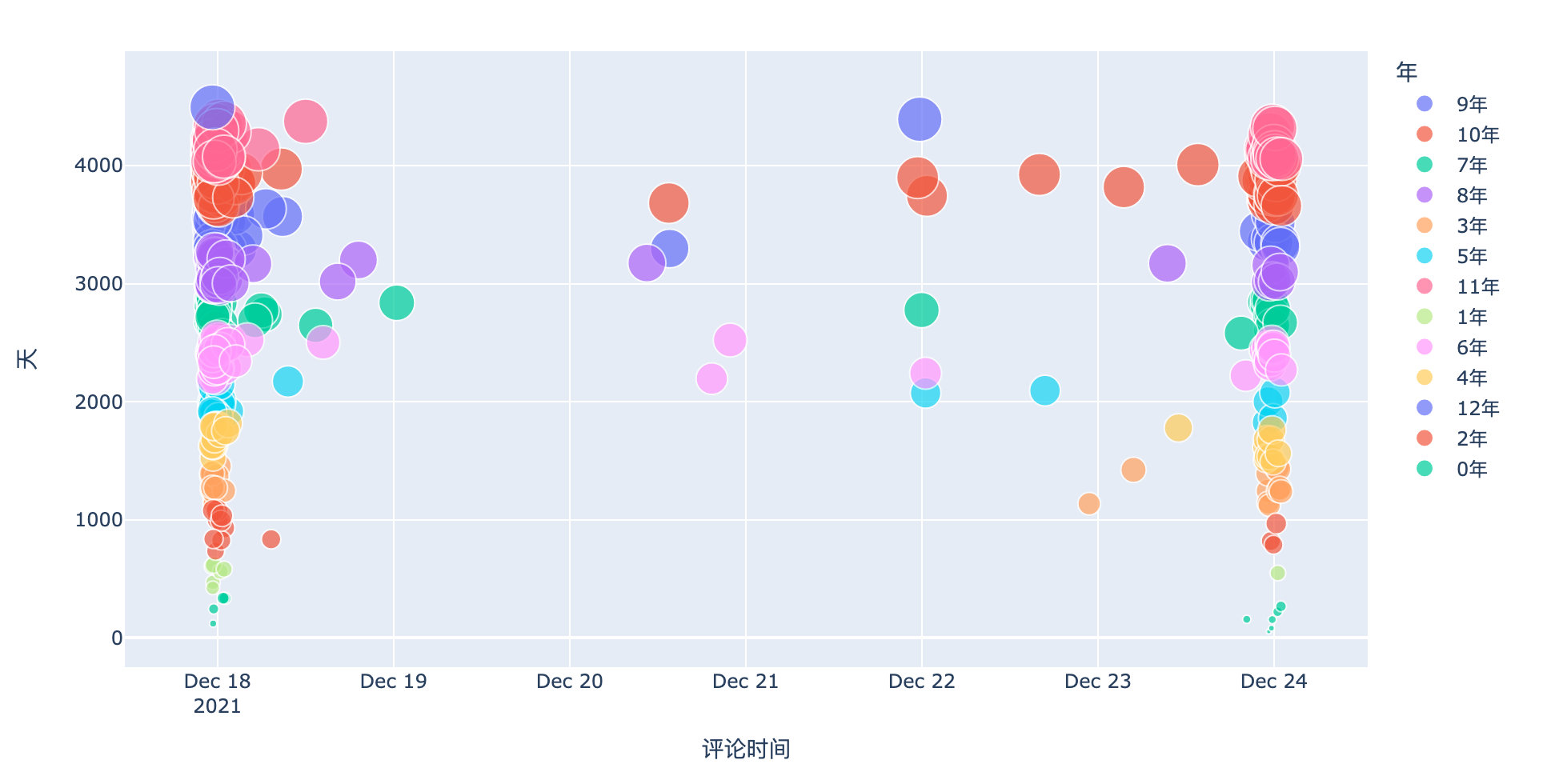
From the user's comment time point of view, when Li sent his first article, he immediately detonated the comment (the dense part on the left); this microblog was silent for 4 days, but I didn't expect it to be hot again on the night of the 23rd
Key points of eating melon with vermicelli
Segment fans' comments to find their focus:
comment_list = df["Comment content"].tolist()
# Word segmentation process
comment_jieba_list = []
for i in range(len(comment_list)):
# jieba participle
seg_list = jieba.cut(str(comment_list[i]).strip(), cut_all=False)
for each in list(seg_list):
comment_jieba_list.append(each)
# Create stop word list
def StopWords(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# Path to the incoming stop phrase list
stopwords = StopWords("/Users/peter/spider/nlp_stopwords.txt")
useful_comment = []
for col in comment_jieba_list:
if col not in stopwords:
useful_comment.append(col)
information = pd.value_counts(useful_comment).reset_index()[1::]
information.columns=["word","number"]
information_zip = [tuple(z) for z in zip(information["word"].tolist(), information["number"].tolist())]
# mapping
c = (
WordCloud()
.add("", information_zip, word_size_range=[20, 80], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="Cloud map of microblog comments"))
)
c.render_notebook()

Focus on the first 50 words:

In addition to the two parties, fans also care about their children. After all, children are innocent, but aren't their melons caused by children? Personal views.
In short: whether it's Wang or Li, if it's really a scum man or a scum woman, please go to the cross, Amen!
Book delivery activities
Python crawler has a very powerful framework, scripy. Xiaobian contacted Peking University Press to send two books: "Python web crawler framework, scripy from introduction to Mastery". Select two friends who leave messages

Friends interested in Python crawlers can also buy them directly.