Preliminary preparation:
(1) Install requests (get HTML information for the entire web page)
In cmd, use the following command to install requests:
pip install requests
(2) Install beautiful soup4 (parse HTML information and extract what we need)
In cmd, use the following command to install requests:
pip install beautifulsoup4
(3) Identify article links (http://www.xbiquge.la/13/13959/5939025.html)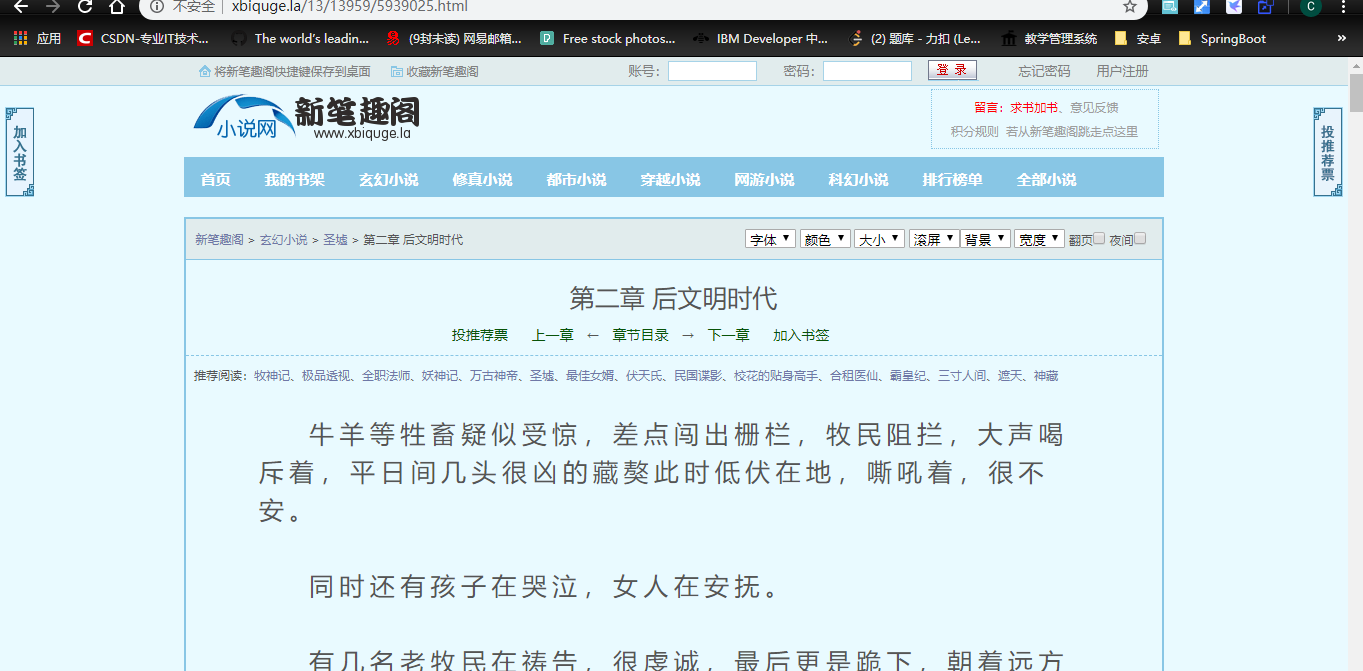
Get page first
# -*- coding:UTF-8 -*- import requests if __name__ == '__main__': target = 'http://www.xbiquge.la/13/13959/5939025.html' req = requests.get(url=target) req.encoding = 'UTF-8' # The obtained page will be garbled and needs transcoding html = req.text print(html)
Then use beautifulsop to get what you need
# -*- coding:UTF-8 -*- import requests from bs4 import BeautifulSoup if __name__ == '__main__': target = 'http://www.xbiquge.la/13/13959/5939025.html' req = requests.get(url=target) req.encoding = 'UTF-8' # The obtained page will be garbled and needs transcoding html = req.text bf = BeautifulSoup(html, features="html.parser") # I used the best HTML parser available on my system ("html.parser") texts = bf.find_all("div", id="content") #Extract the div module with id content in the web page, and the returned result is a list print(texts[0].text.replace('\xa0' * 8, '\n\n')) #Use the text attribute to extract the text content, filter out the br label, and then use the replace method to remove the eight space symbols in the following figure, and use the enter instead
Note: here is to obtain the corresponding module by id. if the module is obtained by class, you need to add the underscore (class Uu), because class is the keyword in python
After running above, the result of running in pyCharm may not be the same as that in cmd. In cmd, the data is crawled completely, while in pyCharm, there is only the next section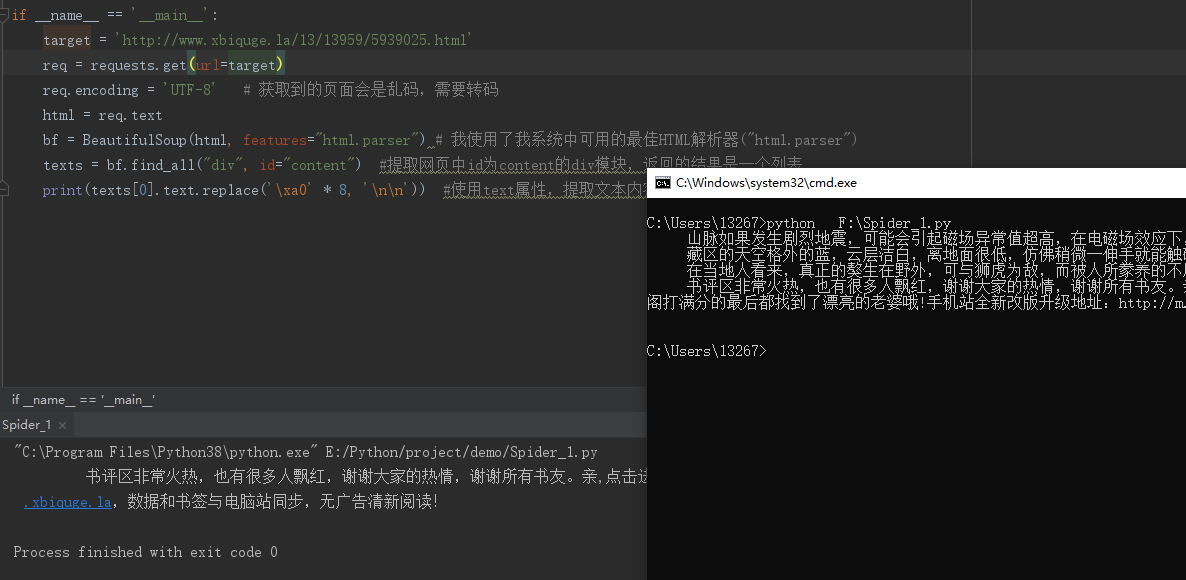
This is because the display is incomplete. In fact, the data has been obtained
With the above foundation, we can obtain the chapter catalog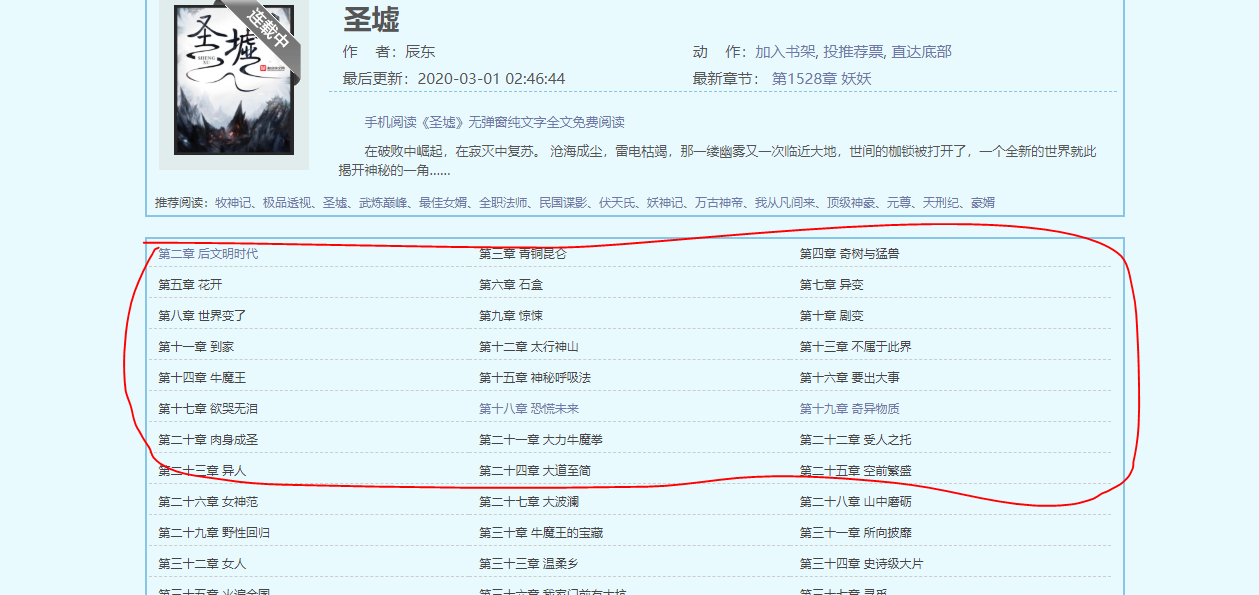
import requests from bs4 import BeautifulSoup req = requests.get(url = 'http://www.xbiquge.la/13/13959/') req.encoding = 'UTF-8' # The acquired Chinese will be garbled and need to be transcoded html = req.text div_bf = BeautifulSoup(html, features="html.parser") div = div_bf.find_all('div', id = 'list') print(div)
You can see that the output is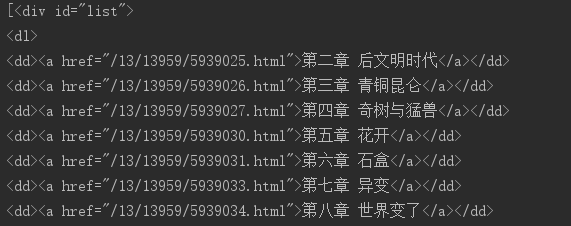
The crawled data includes chapter names and corresponding hyperlinks. At this time, we need to extract chapter names and hyperlinks, and the format of hyperlinks is the data extracted by server + of web pages.
div = div_bf.find_all('div', id = 'list') a_bf = BeautifulSoup(str(div[0]), features="html.parser") a = a_bf.find_all('a') #Get chapter links self.nums = len(a) #Number of statistical chapters
Finally, we integrate the code and add the file storage module. The following is the complete code
# -*- coding:UTF-8 -*- import requests,sys from bs4 import BeautifulSoup class getNovel(object): def __init__(self): self.server = 'http://www.xbiquge.la/' #Link to Chapter self.target = 'http://www.xbiquge.la/13/13959/' #Novel Homepage self.names = [] #Storage chapter name self.urls = [] #Store chapter links self.nums = 0 #Chapters number """ //Write crawled article content to file Parameters: name - Chapter name(string) path - Under current path,Novel preservation name(string) text - Chapter content(string) Returns: //nothing """ def writer(self, name, path, text): write_flag = True with open(path, 'a', encoding='utf-8') as f: f.write(name + '\n') f.writelines(text) f.write('\n\n') """ //Crawled article content Parameters: target - Content path Returns: //Article content """ def get_content(self,target): req = requests.get(url=target, headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36", "Cookie": "_abcde_qweasd=0; Hm_lvt_169609146ffe5972484b0957bd1b46d6=1583122664; bdshare_firstime=1583122664212; Hm_lpvt_169609146ffe5972484b0957bd1b46d6=1583145548", "Host": "www.xbiquge.la"}) req.encoding = 'UTF-8' # The acquired Chinese will be garbled and need to be transcoded html = req.text bf = BeautifulSoup(html, features="html.parser") # I used the best HTML parser available on my system ("html.parser") texts = bf.find_all("div", id="content") # Extract the div module with id content in the web page, and the returned result is a list if (len(texts) ==0 ): content = "Chapter content not obtained" else: content = texts[0].text.replace('\xa0' * 8, '\n\n') # Use the text attribute to extract the text content, filter out the br label, and then use the replace method to remove the eight space symbols in the following figure, and use the enter instead return content """ //Function Description: get download link Parameters: //nothing Returns: //nothing Modify: 2017-09-13 """ def get_novel_url(self): req = requests.get(url = self.target) req.encoding = 'UTF-8' # The acquired Chinese will be garbled and need to be transcoded html = req.text div_bf = BeautifulSoup(html, features="html.parser") div = div_bf.find_all('div', id = 'list') a_bf = BeautifulSoup(str(div[0]), features="html.parser") a = a_bf.find_all('a') #Get chapter links self.nums = len(a) #Eliminate unnecessary chapters and count the number of chapters for each in a: self.names.append(each.string) self.urls.append(self.server + each.get('href')) if __name__ == '__main__': gn = getNovel() gn.get_novel_url() print('<The holy ruins begins to download:') for i in range(gn.nums): gn.writer(gn.names[i], 'Holy ruins.txt', gn.get_content(gn.urls[i])) sys.stdout.write("\r Downloaded:{0:.3f}".format(i/gn.nums)) #Add "\ r" to refresh sys.stdout.flush() print('<Download of Shengxu completed')
Crawling results:


