After a lot of study and preparation in the early stage, it is important for us to start writing the first real reptile. This time we want to climb the site is: Baidu Post Bar, a very suitable place for new people to practice, so let's start.
This time I climb the post bar is < western world > > which is an American drama I always like. I usually go to see what my friends are talking about when I have time. So choose this bar as the experimental material this time. Note: many people will encounter all kinds of problems in the process of learning python. No one can easily give up. For this reason, I have built a python full stack free answer. Skirt: after a long time, I can find it under the conversion of liuyisi (homophony of numbers). The problems that I don't understand are solved by the old driver and the latest Python tutorial download. We can supervise each other and make progress together!
Post address:
https://tieba.baidu.com/f?kw=%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8
Python version: 3.6
Browser version: Chrome
Objective analysis:
Because it's the first experimental reptile, we don't have much to do. What we need to do is:
1. Climb down a specific page from the web
2. Simple filtering and analysis for the content of the down page
3. Find the title, sender, date, floor, and jump links of each post
4. Save the results to text.
Preliminary preparation:
Do you feel confused when you see the url address of the post bar? Which string of unrecognized characters are there?
In fact, these are all Chinese characters,
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C
After the coding: the western world.
At the end of the link, & ie = utf-8 indicates that the connection is utf-8 encoded.
The default encoding of windows is GBK. When dealing with this connection, we need to manually set it in Python to use it successfully.
Compared with Python 2, python 3 has greatly improved its support for coding. By default, utf-8 coding is used globally. Therefore, it is suggested that the little friends who are still learning Python 2 should rush into the embrace of Python 3, which really saves the efforts of the eldest brother.
Then we turn to the second page of the post bar:
url:
`url: https://tieba.baidu.com/f?kw=%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8&pn=50`
Notice that no, there is an extra parameter at the end of the connection & PN = 50,
Here we can easily guess the relation between this parameter and page number:
- &PN = 0: Homepage
- &PN = 50: second page
- &PN = 100: page 3
- &PN = 50 * npage n
- 50 means there are 50 posts on each page.
In this case, we can use simple url modification to achieve page turning effect.
Use of chrome developer tools:
To write a crawler, we must be able to use a development tool. In other words, this tool is for the former developers, but we can use it to quickly locate the information we want to crawl and find the corresponding rules.
- Press cmmand+option+I to open the chrome tool. (for win, you can press F12 or open it manually in the chrome toolbar.)
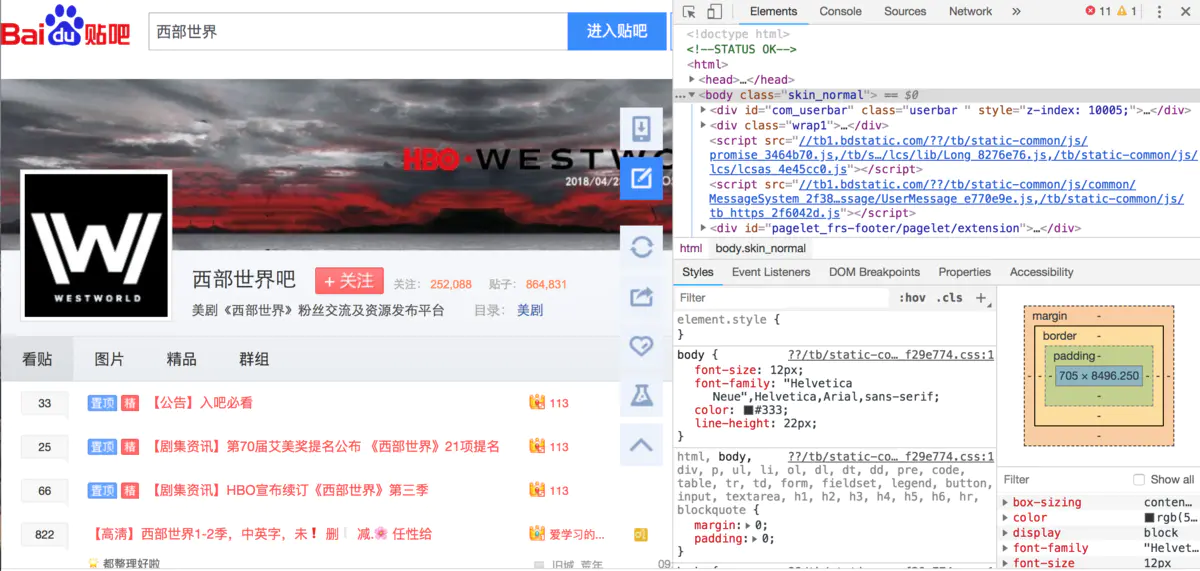
- Use the simulation click tool to quickly locate a single post. (mouse arrow icon in the upper left corner)
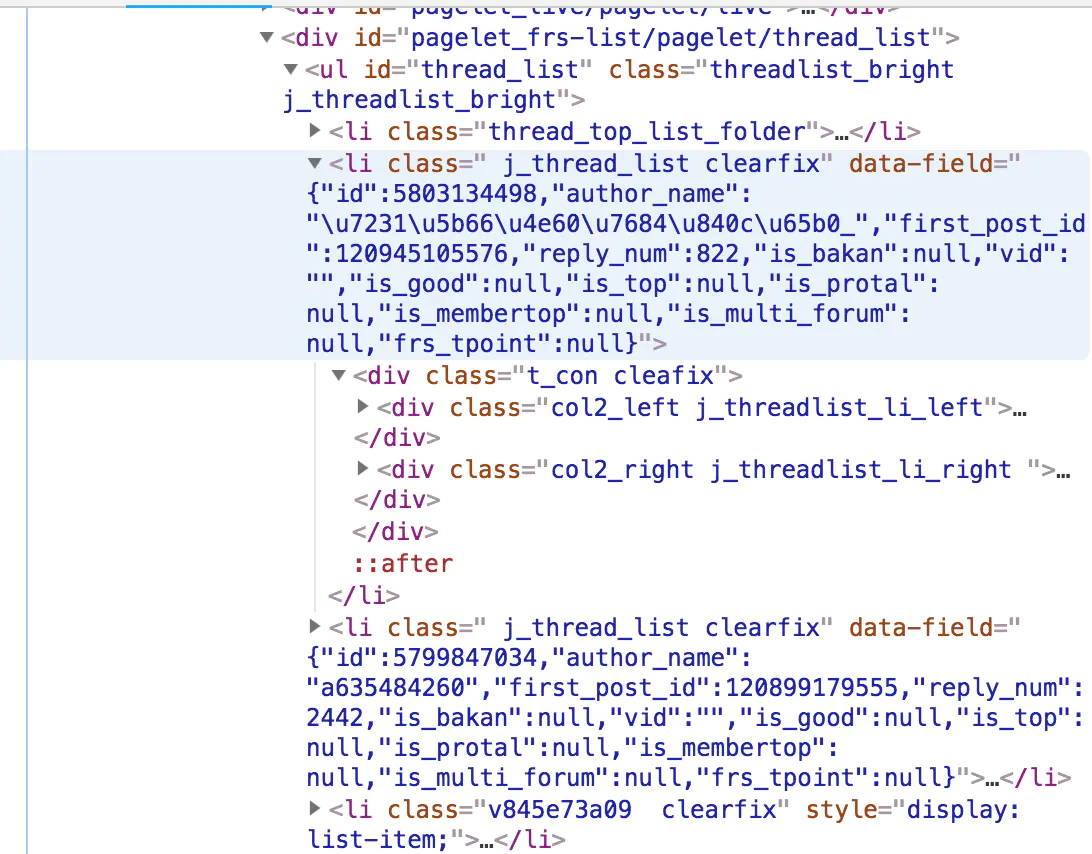
After careful observation, we found that the content of each post is wrapped in a li tag:
<li class=" j_thread_list clearfix">
So we just need to quickly find out all the tags that meet the rules,
In the further analysis of the contents, the data can be filtered out at last.
Start writing code?
Let's first write the function to grab people on the page:
This is the climbing frame introduced earlier, which we will often use later.
import requests
from bs4 import BeautifulSoup
# First of all, we write the function to grab the web page
def get_html(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
#Here we know that the code of Baidu Post Bar is utf-8, so it is set manually. When crawling to other pages, it is recommended to use:
# r.endcodding = r.apparent_endconding
r.encoding='utf-8'
return r.text
except:
return " ERROR "
Then we extract the details:
- Let's divide the internal structure of each li tag:
A large li tag contains many div tags
And the information we want is in this div tag:
# Title & post link
<a rel="noreferrer" href="/p/5803134498" title="[Gaoqing] Western world 1-2 Ji, in Chinese and English, Wei❗️Delete❕reduce.🌸Willful giving" target="_blank" class="j_th_tit ">[Gaoqing] Western world 1-2 Ji, in Chinese and English, Wei❗️Delete❕reduce.🌸Willful giving</a>
#Poster:
<span class="tb_icon_author no_icon_author" title="Topic author: Love learning_" data-field="{"user_id":829797296}"><i class="icon_author"></i><span class="pre_icon_wrap pre_icon_wrap_theme1 frs_bright_preicon"><a class="icon_tbworld icon-crown-super-v1" href="/tbmall/tshow" data-field="{"user_id":829797296}" target="_blank" title="Post Bar super member"></a></span>
#Number of replies:
<div class="col2_left j_threadlist_li_left">
<span class="threadlist_rep_num center_text" title="Reply">822</span>
</div>
#Post date:
<span class="pull-right is_show_create_time" title="Creation time">7-20</span>
After analysis, we can easily get the result we want through the soup.find() method
Implementation of specific code:
'''
//Grasp the basic content of Baidu Post Bar -- Western world bar
//Crawler line: requests - bs4
Python Version: 3.6
OS: mac os 12.13.6
'''
import requests
import time
from bs4 import BeautifulSoup
# First of all, we write the function to grab the web page
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
# Here we know that the code of Baidu Post Bar is utf-8, so it is set manually. When crawling to other pages, it is recommended to use:
# r.endcodding = r.apparent_endconding
r.encoding = 'utf-8'
return r.text
except:
return " ERROR "
def get_content(url):
'''
//Analyze the webpage file of the post bar, organize the information, and save it in the list variable
'''
# Initialize a list to save all post information:
comments = []
# First of all, we download the web pages that need to crawl information to the local
html = get_html(url)
# Let's make a pot of soup
soup = BeautifulSoup(html, 'lxml')
# According to the previous analysis, we found all li tags with the 'j'thread'list Clearfix' attribute. Returns a list type.
liTags = soup.find_all('li', attrs={'class': ' j_thread_list clearfix'})
# Find the information we need in each post by looping:
for li in liTags:
# Initialize a dictionary to store article information
comment = {}
# Here, a try except is used to prevent the crawler from not finding information to stop running
try:
# Start filtering information and save to dictionary
comment['title'] = li.find(
'a', attrs={'class': 'j_th_tit '}).text.strip()
comment['link'] = "http://tieba.baidu.com/" + \
li.find('a', attrs={'class': 'j_th_tit '})['href']
comment['name'] = li.find(
'span', attrs={'class': 'tb_icon_author '}).text.strip()
comment['time'] = li.find(
'span', attrs={'class': 'pull-right is_show_create_time'}).text.strip()
comment['replyNum'] = li.find(
'span', attrs={'class': 'threadlist_rep_num center_text'}).text.strip()
comments.append(comment)
except:
print('There's a little problem')
return comments
def Out2File(dict):
'''
//Write crawled file to local
//Save to the TTBT.txt file in the current directory.
'''
with open('TTBT.txt', 'a+') as f:
for comment in dict:
f.write('Title: {} \t Links:{} \t Poster:{} \t Post time:{} \t Number of replies: {} \n'.format(
comment['title'], comment['link'], comment['name'], comment['time'], comment['replyNum']))
print('Current page crawling completed')
def main(base_url, deep):
url_list =