Python web crawler and information extraction.
Article directory
- Python web crawler and information extraction.
- Tools.
- Requests library.
- HTTP protocol and Requests library method.
- robots.txt
- Example - Jingdong.
- Amazon.
- Examples - Baidu, 360.
- Crawling and storage of network pictures.
- Automatic query of instance IP address home location.
- Beautiful Soup
- Projects
- Re
- Scrapy
The Website is the API...
Master the basic ability of directional web crawling and web page parsing.
Tools.
IDLE
Sublime Text
PyCharm
Anaconda & Spyder
Wing
Visual Studio & PTVS
Eclipse + PyDev
PyCharm
- Scientific calculation and data analysis.
Canopy
Anaconda
Requests library.
http://2.python-requests.org/zh_CN/latest/
Automatically crawls HTML pages.
Automatic network submission.
Installation.
pip install requests
Use.
>>> import requests >>> r = requests.get("http://www.baidu.com") >>> r.status_code 200 >>> r.encoding 'ISO-8859-1' >>> r.encoding = 'utf-8' >>> r.text ...
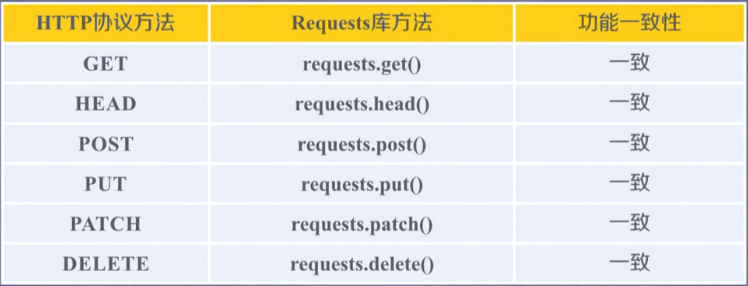
Main methods of Requests library.
| Method | Explain |
|---|---|
| requests.request() | Construct a request that supports the following basic methods. |
| requests.get() | The main method to GET HTML pages corresponds to HTTP GET. |
| requests.head() | Get the HTML page header information, corresponding to the HTTP HEAD. |
| requests.post() | Submit the POST request to the HTML page, corresponding to the HTTP POST. |
| requests.put() | Submit a PUT request to the HTML page, corresponding to the HTTP PUT. |
| requests.patch() | Submit the local modification request to the HTML page, corresponding to the HTTP PATCH. |
| requests.delete() | Submit a DELETE request to the HTML page, corresponding to HTTP DELETE. |
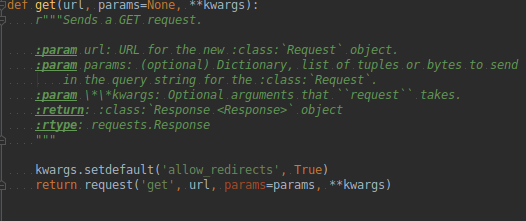
requests.request()
The following six are the encapsulation of the requests.request() method.
return request('get', url, params=params, **kwargs)
- The complete parameters of the requests.get() method.
url - > the url link of the page to be obtained.
params - > additional parameters in URL, dictionary or byte stream format. Optional.
**kwargs -- > 12 parameters to control access.
>>> import requests >>> r = requests.get("http://www.baidu.com") >>> r.status_code 200 >>> r.encoding 'ISO-8859-1' >>> r.encoding = 'utf-8' >>> r.text > ... Omit content... >>> type(r) <class 'requests.models.Response'>
GET() method.
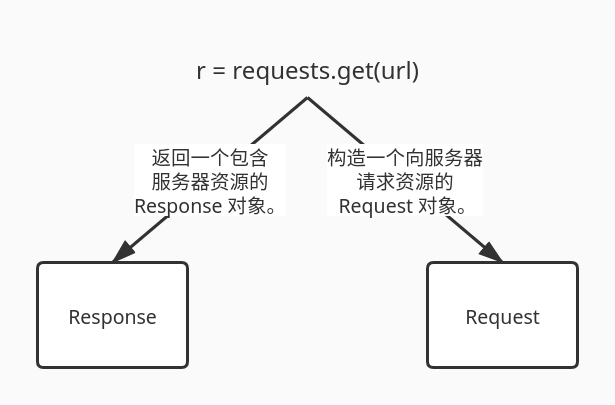
Two important objects of Requests library.
Object properties.

- Code.
r.encoding
Guess from the HTTP header. If charset does not exist in the header, it is considered as ISO-8859-1.
(unable to parse Chinese).
r.apparent_encoding
Analyze the possible encoding from the content part of HTTP instead of the header part. (more accurate).

- General process.

>>> import requests >>> r = requests.get('http://www.baidu.com') >>> r.encoding 'ISO-8859-1' # Default encoding. >>> r.apparent_encoding 'utf-8'
Crawl the general code framework of the web page.
There are risks in network connection, so exception handling is very important.
Abnormal.
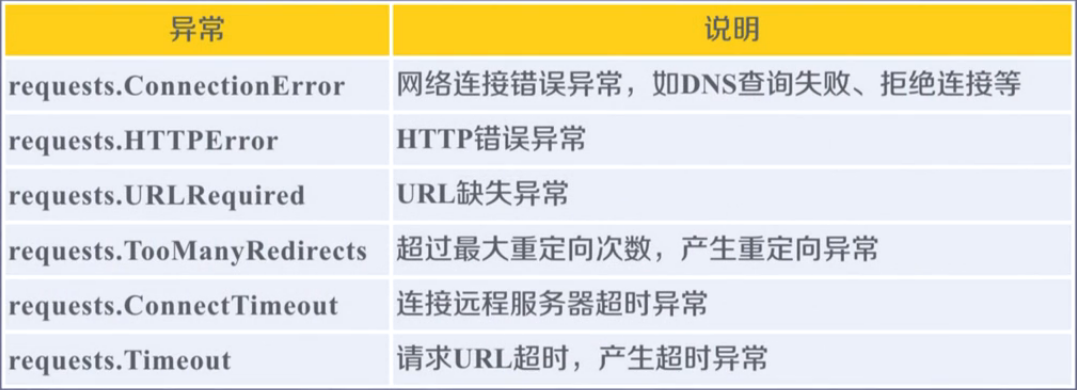
The Requests library is important.
Response object. r.raise_for_status().

Common code.
import requests def getHtmlText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() # If the status is not 200, an HTTPError exception is thrown. r.encoding = r.apparent_encoding return r.text except: return 'An exception occurred.' if __name__ == '__main__': url = "http://www.baidu.com" print(getHtmlText(url))
HTTP protocol and Requests library method.

HTTP, Hypertext Transfer Protocol, hypertext transfer protocol.
HTTP is a stateless application layer protocol based on "request and response" mode.
HTTP generally uses URL as the identification of locating network resources.
URL format.
http://host[:port] [path]
- host
Legal Internet host domain name or IP address. - port
Port number. The default port is 80. - path
The path to the request resource.
Understanding of HTTP URL.
URL is the Internet path to access resources through HTTP protocol. A URL corresponds to a data resource.
HTTP operations on resources.


The difference between PATCH and PUT.
Suppose the URL location has a set of data UserInfo, including 20 fields such as UserID and UserName.
Requirement: the user has modified the UserName, others remain unchanged.
- With PATCH, only local update requests for UserName are submitted to the URL.
- With PUT, all 20 fields must be submitted to the URL, and the uncommitted fields are deleted.
PATCH - > saves network bandwidth.
HTTP protocol and Requests library.
>>> import requests >>> r = requests.head('http://www.baidu.com') >>> r.headers {'Connection': 'keep-alive', 'Server': 'bfe/1.0.8.18', 'Last-Modified': 'Mon, 13 Jun 2016 02:50:08 GMT', 'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 15 Mar 2020 05:27:57 GMT', 'Pragma': 'no-cache'} >>> r.text '' >>> # r.text is empty.
The post() method of the Requests library.
- Post a dictionary to the URL, automatically encoded as a form.
>>> payload = {'key1': 'value1', 'key2': 'value2'} >>> r = requests.post('http://httpbin.org/post', data = payload) >>> print(r.text) { "args": {}, "data": "", "files": {}, "form": { "key1": "value1", "key2": "value2" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "23", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.12.4", "X-Amzn-Trace-Id": "Root=1-5e6dbe4a-093105e6e89bdcef261839bc" }, "json": null, "origin": "111.47.210.49", "url": "http://httpbin.org/post" } >>>
- Post a string to the URL, automatically encoded as data.
>>> r = requests.post('http://httpbin.org/post', data = 'geek') >>> print(r.text) { "args": {}, "data": "geek", "files": {}, "form": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "4", "Host": "httpbin.org", "User-Agent": "python-requests/2.12.4", "X-Amzn-Trace-Id": "Root=1-5e6dc04d-b5788522e25af298ea06f366" }, "json": null, "origin": "111.47.210.49", "url": "http://httpbin.org/post" } >>>
put() method of Requests library.
>>> payload = {'key1': 'value1', 'key2': 'value2'} >>> r = requests.put('http://httpbin.org/put', data = payload) >>> print(r.text) { "args": {}, "data": "", "files": {}, "form": { "key1": "value1", "key2": "value2" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "23", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.12.4", "X-Amzn-Trace-Id": "Root=1-5e6dc16b-6bf16d909e60eba2379976b6" }, "json": null, "origin": "111.47.210.49", "url": "http://httpbin.org/put" } >>>
Requests library main method analysis.
requests.request(method, url, **kwargs)
Method > request method, corresponding to 7 kinds of get / put / post.
url - > the url link of the page to be obtained.
**kwargs - > 13 parameters to control access.
- Method > request method.

- **kwargs - > 13 parameters to control access.
**Start - > optional parameters.
params - > dictionary or byte sequence, added to the url as a parameter.
>>> kv = {'key1': 'value1', 'key2': 'value2'} >>> r = requests.request('GET', 'http://python123.io/ws', params=kv) >>> print(r.url) https://python123.io/ws?key1=value1&key2=value2
data - > dictionary, byte sequence or file object as the content of Request.
>>> kv = {'key1': 'value1', 'key2': 'value2'} >>> r = requests.request('POST', 'http://python123.io/ws', data=kv) >>> body = 'Main content' >>> r = requests.request('POST', 'http://python123.io/ws', data=body.encode('utf-8'))
json - > data in json format, as the content of Request.
>>> kv = {'key1': 'value1'} >>> r = requests.request('POST', 'http://python123.io/ws', json=kv)
Headers - > dictionary, HTTP custom headers.
>>> kv = {'key1': 'value1'} >>> r = requests.request('POST', 'http://python123.io/ws', headers=hd)
Cookies - > cookies in the dictionary or CookieJar, Request.
auth - > tuple, which supports HTTP authentication.
Files - > dictionary type, transfer files.
>>> fs = {'file': open('data.xls', 'rb')} >>> r = requests.request('POST', 'http://python123.io/ws', files=fs)
Timeout - > set the timeout in seconds.
>>> r = requests.request('GET', 'http://www.baidu.com', timeout=10)
proxies - > dictionary type. Set access proxy server to add login authentication. (hide the user's original IP information to prevent the crawler from tracking back.).
>>> pxs = {'http': 'http://user:pass@10.10.10.1:1234', \ ... 'https': 'https://10.10.10.1:4321'} >>> r = requests.request('GET', 'http://www.baudi.com', proxies=pxs)
Allow? Redirects - > True / false, default to True, redirection switch.
stream - > True / false, the default is True, and the download switch is used to get the content immediately.
verify - > True / false, the default is True, and the SSL certificate switch is authenticated.
cert - > local SSL certificate path.
requests.get(url, params=None, **kwargs)
requests.head(url, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.delete(url, **kwargs)
robots.txt
Queue criteria for web crawlers.
Problems caused by web crawlers.

- Legal risks of web crawlers.
The data on the server has ownership.
It will bring legal risk for the crawler to make profits after obtaining data.
- Web crawlers leak privacy.
Web crawlers may have the ability to break through the simple access control, obtain the protected data and disclose personal privacy.
Limitations of web crawlers.
- Source review: judge user agent restrictions.
Check the user agent domain visiting the HTTP protocol header, and only respond to browser or friendly crawler access.
- Announcement: Robots protocol.
Inform all crawlers of the view crawl strategy and ask them to follow it.
Robots protocol.

Put it in the root directory.
http://www.baudi.com/robots.txt
http://news.sina.com.cn/robots.txt
http://www.qq.com/robots.txt
http://news.qq.com/robots.txt
http://www.moe.edu.cn/robots.txt (no robots protocol).
https://www.jd.com/robots.txt
User-agent: * Disallow: /?* Disallow: /pop/*.html Disallow: /pinpai/*.html?* User-agent: EtaoSpider Disallow: / User-agent: HuihuiSpider Disallow: / User-agent: GwdangSpider Disallow: / User-agent: WochachaSpider Disallow: /

How to comply with the Robots protocol.
Use of Robots protocol.
Web crawler: automatically or manually identify robots.txt, and then crawl the content.
Binding: Robots protocol is recommended but not binding. Web crawlers can not abide by it, but there are legal risks.

Humanoid behavior can not refer to Robots protocol.
Example - Jingdong.
https://item.jd.com/100004364088.html
>>> import requests >>> r = requests.get('https://item.jd.com/100004364088.html') >>> r.status_code 200 >>> r.encoding 'gbk' # You can parse the code from scratch. >>> r.text[:1000] '<!DOCTYPE HTML>\n<html lang="zh-CN">\n<head>\n <!-- shouji -->\n <meta http-equiv="Content-Type" content="text/html; charset=gbk" />\n <title>[millet Ruby]millet (MI)Ruby 15.6 Learning light and thin laptops in "Internet Course"(intel core i5-8250U 8G 512G SSD 2G GDDR5 Self evident FHD Full keyboard Office Win10) Deep space grey computer-JD.COM</title>\n <meta name="keywords" content="MIRuby,millet Ruby,millet Ruby offer,MIRuby offer"/>\n <meta name="description" content="[millet Ruby]JD.COM JD.COM Provide millet Ruby Genuine goods, including MIRuby Online shopping guide and Xiaomi Ruby Pictures, Ruby Parameters, Ruby Commentary, Ruby Experience, Ruby Tips and other information, online shopping millet Ruby Jingdong,Relax and relax" />\n <meta name="format-detection" content="telephone=no">\n <meta http-equiv="mobile-agent" content="format=xhtml; url=//item.m.jd.com/product/100004364088.html">\n <meta http-equiv="mobile-agent" content="format=html5; url=//item.m.jd.com/product/100004364088.html">\n <meta http-equiv="X-UA-Compatible" content="IE=Edge">\n <link rel="canonical" href="//item.jd.com/100004364088.html"/>\n <link rel="dns-prefetch" href="//misc.360buyimg.com"/>\n <link rel="dns-prefetch" href="//static.360bu'
import requests def getHtmlText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() # If the status is not 200, an HTTPError exception is thrown. r.encoding = r.apparent_encoding return r.text except: return 'An exception occurred.' if __name__ == '__main__': url = "https://item.jd.com/100004364088.html" print(getHtmlText(url))
Amazon.
https://www.amazon.cn/dp/B07STXYG5T/ref=lp_1454005071_1_13?s=pc&ie=UTF8&qid=1584258911&sr=1-13
>>> r = requests.get('https://www.amazon.cn/dp/B07STXYG5T/ref=lp_1454005071_1_13?s=pc&ie=UTF8&qid=1584258911&sr=1-13')
Python faithfully told the server that it was requested by Python's Requests library.
>>> r.request.headers {'Connection': 'keep-alive', 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'User-Agent': 'python-requests/2.12.4'}
Modify user agent.
>>> kv = {'user-agent': 'Mozilla/5.0'} >>> url = 'https://www.amazon.cn/dp/B07STXYG5T/ref=lp_1454005071_1_13?s=pc&ie=UTF8&qid=1584258911&sr=1-13' >>> r = requests.get(url, headers = kv) >>> r.status_code 200 >>> r.request.headers {'Connection': 'keep-alive', 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'user-agent': 'Mozilla/5.0'}
Examples - Baidu, 360.
- Baidu interface.
https://www.baidu.com/s?wd=
keyword
>>> import requests >>> kv = {'wd': 'Python'} >>> r = requests.get('https://www.baidu.com/s', params = kv) >>> r.status_code 200 >>> r.request r.request >>> r.request.url 'https://wappass.baidu.com/static/captcha/tuxing.html?&ak=c27bbc89afca0463650ac9bde68ebe06&backurl=https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3DPython&logid=9150222916142828809&signature=0acac15173bcd5487e4b0837a6dbf568×tamp=1584259949' >>> len(r.text) 1519
- 360 interface.
https://www.so.com/s?q=
keyword
Crawling and storage of network pictures.
- Network picture link format.
http://www.example.com/
picture.jpg
- National Geographic Chinese network.
http://www.ngchina.com.cn/
A picture of the day.
http://www.ngchina.com.cn/photography/photo_of_the_day/6245.html
http://image.ngchina.com.cn/2020/0310/20200310021330655.jpg
>>> import requests >>> path = '/home/geek/geek/crawler_demo/marry.jpg' >>> url = 'http://image.ngchina.com.cn/2020/0310/20200310021330655.jpg' >>> requests.get(url) <Response [200]> >>> r = requests.get(url) >>> with open(path, 'wb') as f: ... f.write(r.content) # r.content is in binary form. ... 471941 >>> f.close f.close( f.closed >>> f.close() >>>
Full code.
import os import requests root = r'/home/geek/geek/crawler_demo/' url = 'http://image.ngchina.com.cn/2020/0310/20200310021330655.jpg' path = root + url.split('/')[-1] try: if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): with open(path, 'wb') as f: r = requests.get(url) f.write(r.content) # r.content is in binary form. f.close() print('The file was saved successfully.') else: print('The file already exists.') except Exception as e: print(e) print('Crawling failed.')
Result.
geek@geek-PC:~/geek/crawler_demo$ ls marry.jpg geek@geek-PC:~/geek/crawler_demo$ ls 20200310021330655.jpg marry.jpg
Automatic query of instance IP address home location.
First, you need an IP address library.
www.ip138.com iP query (search location of iP address)
Interface.
http://www.ip138.com/iplookup.asp?ip=
IP address&action=2
>>> import requests >>> url = 'http://www.ip138.com/iplookup.asp?ip=111.47.210.37&action=2' >>> kv = {'user-agent': 'Mozilla/5.0'} >>> r = requests.get(url, headers = kv) >>> r.status_code 200 >>> r.encoding = r.apparent_encoding >>> r.text
Code.
import requests url = 'http://www.ip138.com/iplookup.asp?ip=111.47.210.37&action=2' kv = {'user-agent': 'Mozilla/5.0'} try: r = requests.get(url, headers=kv) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[:1000]) except: print('Crawling failed.')
Beautiful Soup
Parse the HTML page.
Projects
Practical project A/B.
Re
Regular expression details.
Extract page key information.
Scrapy
Introduction to the principle of web crawler.
Introduction to professional reptile framework.

