Making a reptile is generally divided into the following steps:
1. Analysis requirements
2. Analyze web page source code and cooperate with developer tools
3. Write regular expressions or XPath expressions
4. Formally write python crawler code
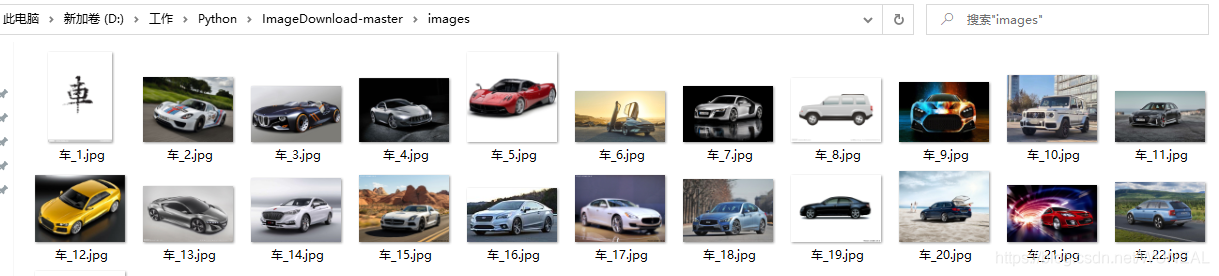
The operation effect is as follows:

Folder for pictures:
requirement analysis
Our crawler should realize at least two functions: one is to search images, and the other is to download automatically.
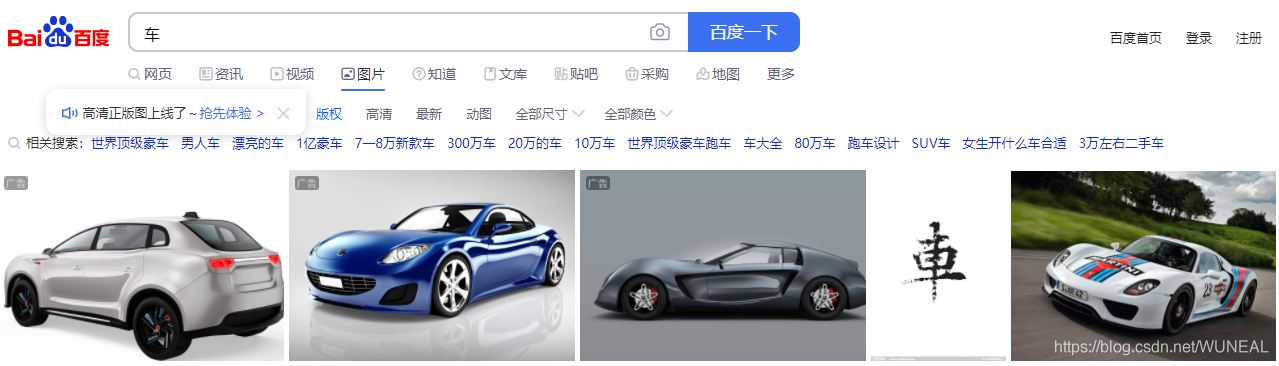
Search for pictures: the easiest thing to think of is the result of climbing Baidu pictures. Let's go to Baidu pictures:

Search a few keywords casually, and you can see many pictures that have been searched:
Analyze web pages
Right click to view the source code:
After opening the source code, we find that a pile of source code is difficult to find the resources we want.
At this time, we need to use developer tools! We go back to the previous page and call up the developer tool. We need to use the thing in the upper left corner: (mouse follow).
Then select the place where you want to see the source code, and you can find that the following code area is automatically located to the corresponding position. As shown below:
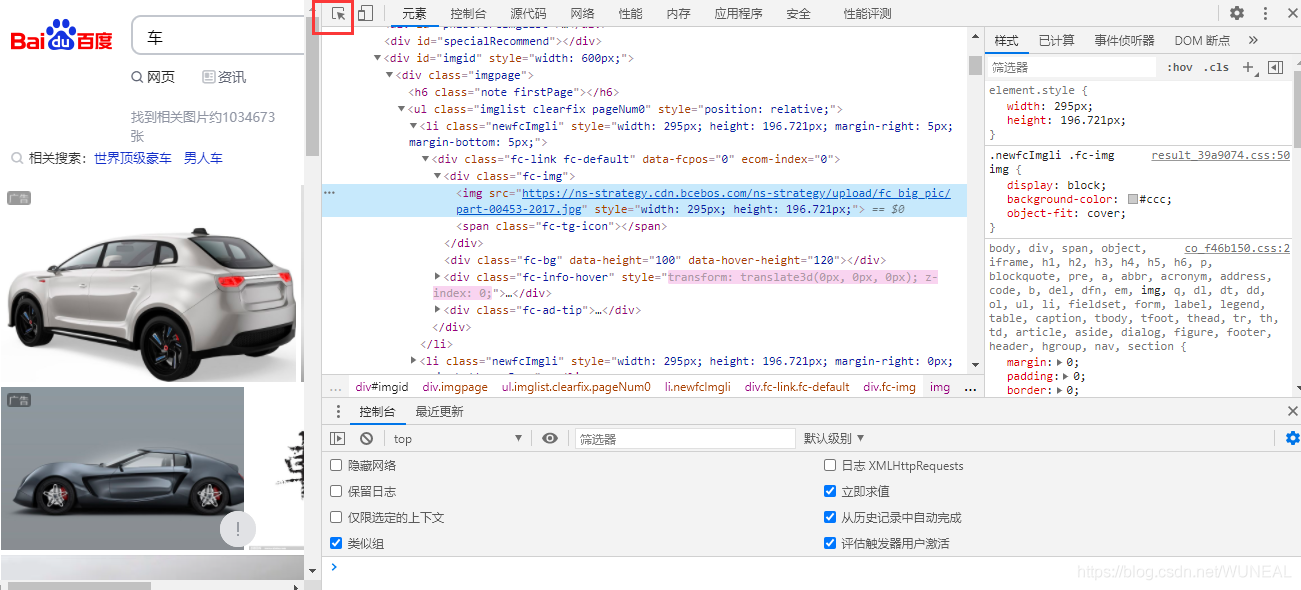
We copied this address, searched in a pile of source code just now, and found its location, but here we wonder, which one is used for this picture with so many addresses? We can see that there are thumbURL, middleURL, hoverURL and obj URL

Through analysis, we can know that the first two are reduced versions. hoverURL is the version displayed after the mouse moves. Obj URL should be what we need. You can open these URLs separately and find the largest and clearest obj URL.
After finding the picture address, let's analyze the source code. See if all obj URLs are pictures.

The discovery is based on A picture ending in jpg format.
Writing regular expressions
Detailed explanation of findall() of Python regular expression re module
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
Writing crawler code
Here we use two packages, one is regular and the other is requests
#-- coding:utf-8 --import reimport requests
Copy the link of Baidu image search, pass in requests, and then write the regular expression
url ='http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip')
#Word is the search keyword
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
The session object of the requests library can help us maintain some parameters across requests, and also maintain cookies between all requests issued by the same session instance. Requests in python Wonderful use of session
sessions = requests.session()
result=sessions.post('http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip')
Because there are many pictures, we need to cycle. We print out the results to have a look, and then use requests to obtain the website. Because some pictures may not open the website, a 10 second timeout control is added.
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)i = 1for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('error: current picture cannot be downloaded ')
continue
Then we save the pictures. We set up an images directory in advance, put all the pictures in it, and name them with numbers.
dir = '.../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
Complete code
# -*- coding:utf-8 -*-
import re
import requests
def dowmloadPic(html, keyword):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 1
print('Find keywords:' + keyword + 'Start downloading pictures now...')
for each in pic_url:
print('Downloading page' + str(i) + 'Picture, picture address:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('[Error] the current picture cannot be downloaded')
continue
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
sessions = requests.session()
sessions.headers['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'
word = input("Input key word: ")
result=sessions.post('http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip')
dowmloadPic(result.text, word)

We saw that some pictures were not displayed. We opened the website and found that they were indeed gone.

summary
Image download crawler completed.