Introduction:
Crawler is a program that automatically grabs Internet information. It can grab valuable data from the Internet.
Commonly used libraries include urllib, beautiful soup, etc
urllib parses the text information returned based on the request, and beautiful soup parses based on the interface label
The usage of urllib is described in detail here.
The urllib libraries corresponding to python2 and python3 are different, corresponding to urllib 2 and urllib respectively. Specific use can be searched by version. This article uses urllib corresponding to Python 3 to illustrate
Application scenarios and analysis methods:
I need to query the corresponding information in a system and obtain the results.
The system needs to judge the user's permission to query the data request, so it needs user information such as cookies, and the cookies will change each time you log in, ⬇️ To automatically save cookies, once and for all.
First, use the Google browser mode, open the network, check preserve log, operate the links to be accessed in the interface, and then view and analyze in the log, taking CSDN as an example to query my original articles.
You can see that the original article query request is the get method. Let's take another look at the header hearders and upload Parameters of the request:
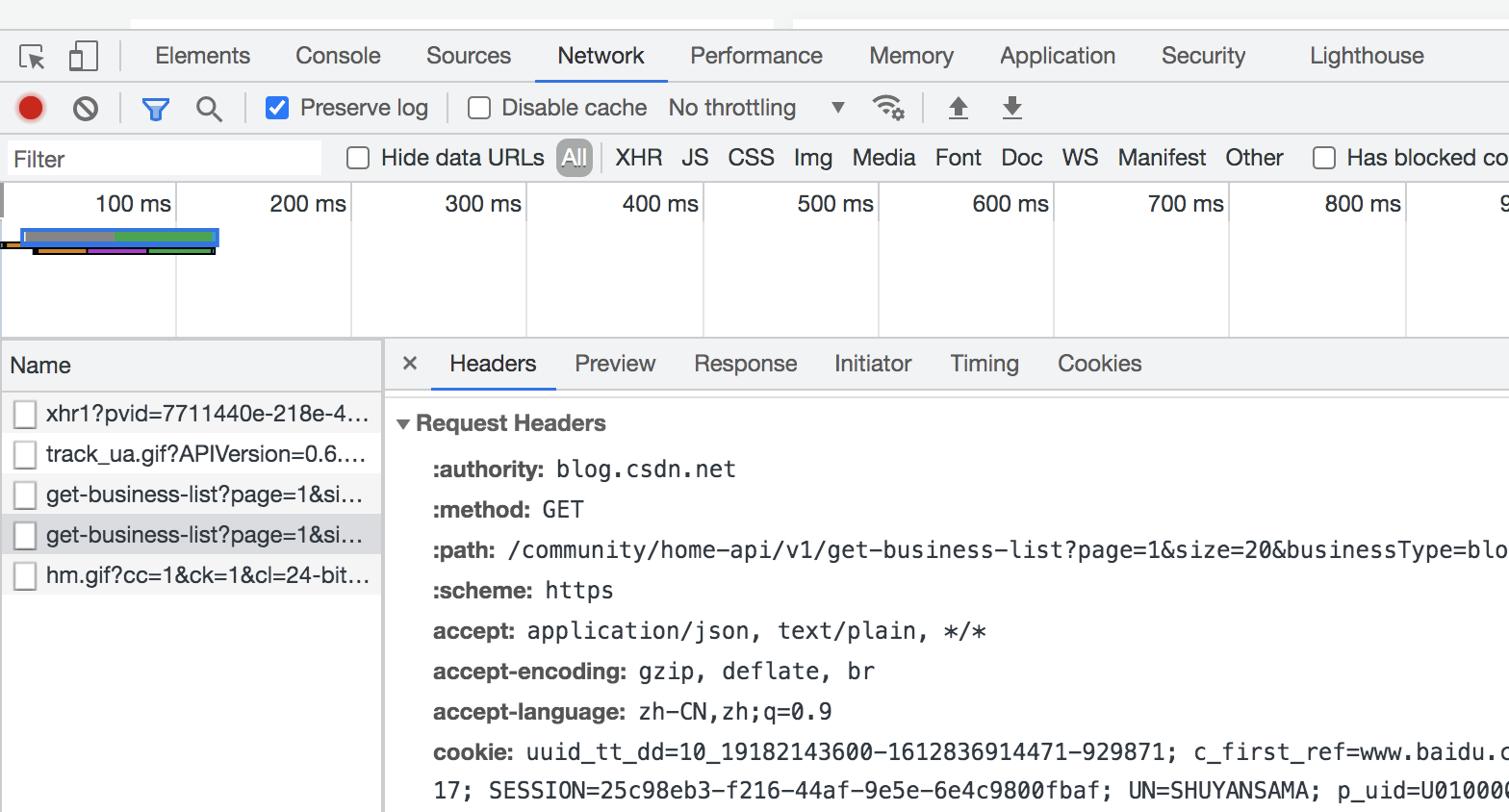
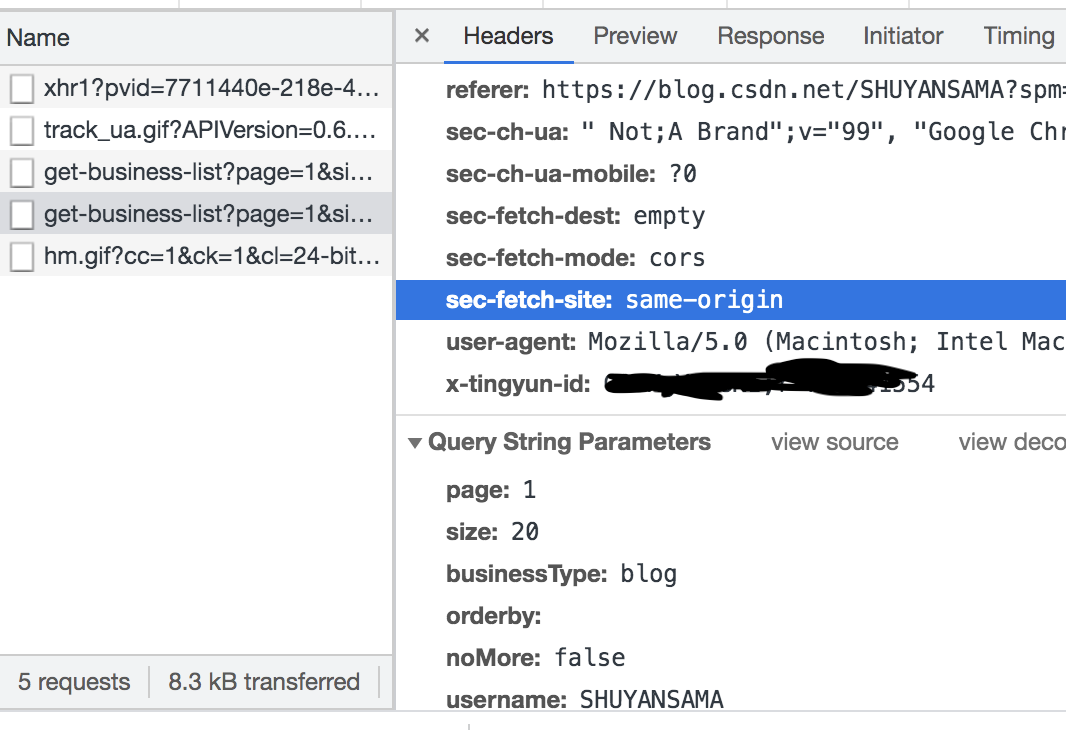 The user agent in the shearers is the agent, which needs to be copied and placed in the code to disguise the browser operation. Parameters are the parameters to be uploaded in the request.
The user agent in the shearers is the agent, which needs to be copied and placed in the code to disguise the browser operation. Parameters are the parameters to be uploaded in the request.
Next, take a look at the return of this request:
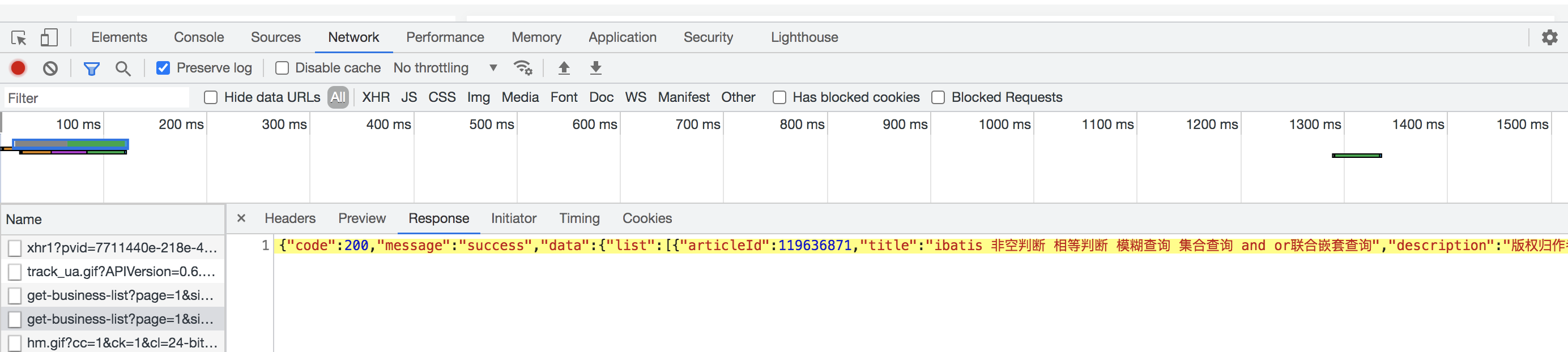
Return a list containing the title, description and other information of my original article. Through the text processing of the obtained information, the corresponding data to be crawled can be obtained.
Code implementation:
Crawler splitting steps:
1. Simulate user login operation, parse and obtain user cookie s
2. Analyze the URL that needs to crawl information, and use the user cookie obtained in the first step to submit the request query data
3. Analyze and process the request return data in step 2 to get the information we want to crawl
First, let's look at the code implementation of the first step
import urllib
import http.cookiejar
def getCookie():
##Log in to the website and get cookie s
login_url = 'To be logged in_URL'
##'userId' and 'password' are in the request parameter in the browser in developer mode
login_data = {'userId':"yourUserID,'password':"yourPassWord"}
headers = {
'User-Agent':"Viewed in developer mode in browser yourUserAgent",
'Host':"Browser developer mode host Information“
}
cookie = http.cookiejar.CookieJar()
cookieProcessor = urllib.request.HTTPCookieProcessor(cookie)
#First build and initialize an opener
opener = urllib.request.build_opener(cookieProcessor)
urllib.request.install_opener(opener)
#The parameters passed to the browser are encoded in UTF8
postdata = urllib.parse.urlencode(login_data).encode(encoding='UTF8')
request = urllib.request.Request(login_url,postdata,headers)
response = ulilib.request.urlopen(request)
#At this time, the cookie is already in the opener, and the parameters contained in it are spliced into a string
cj = ""
for item in cookie:
cj += item.name + "=" + item.value + ","
#cj is a concatenated cookie string
return cjStep 2 / 3 code implementation:
def getInformation(name_to_search,startDate,endDate,cookie):
url_query = 'To be queried_URL request'
#The parameters that need to be uploaded to submit a query request, someone, data within a certain period of time
values = {'person':"name_to_search,'startDate':"startDate",'endDate' = "endDate"}
headers = {
'User-Agent':"Viewed in developer mode in browser yourUserAgent",
'Referer':"Browser developer mode referer Information“,
'Cookie':cookie
}
cj = http.cookiejar.CookieJar()
cookieProcessor = urllib.request.HTTPCookieProcessor(cj)
#First build and initialize an opener
opener = urllib.request.build_opener(cookieProcessor)
urllib.request.install_opener(opener)
#The parameters passed to the browser are encoded in UTF8
postdata = urllib.parse.urlencode(values).encode(encoding='UTF8')
request = urllib.request.Request(url_query,postdata,headers)
response = ulilib.request.urlopen(request)
#Parsing request return
html_cont = reponse.read()
return html_cont.decode('utf-8')HTML_ After using utf-8 code to parse cont, we can get the data we want to crawl. The crawler is now complete.
The framework in step 1 is the same as that in step 2 and step 3, except for different requests, parameters to be uploaded and carried, and request URL s. If you need to crawl a request, you don't need to verify user permissions. You don't need to be so troublesome. You can use it directly
response = ulilib.request.urlopen(request) is enough. The request only needs to contain the URL and corresponding data.