Preface
The text and pictures in this article are from the Internet. They are for study and communication only. They do not have any commercial use. The copyright is owned by the original author. If you have any questions, please contact us in time for processing.
Author: Yimou
PS: If you need Python learning materials for your child, click on the link below to get them
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
1. Preconditions
-
Fiddler installed (for package capture analysis)
-
Google or Firefox Browser
-
If it is Google Browser, you also need to install a SwitchyOmega plug-in for Google Browser to use as a proxy server
-
Compile environment with Python, generally Python 3.0 and above
Statement: This time I crawled the comments of the "Most Beautiful Kilometer" documentary in Tencent's video.The browser used for this crawl is Google Browser
2. Analysis ideas
1. Analysis Comment Page
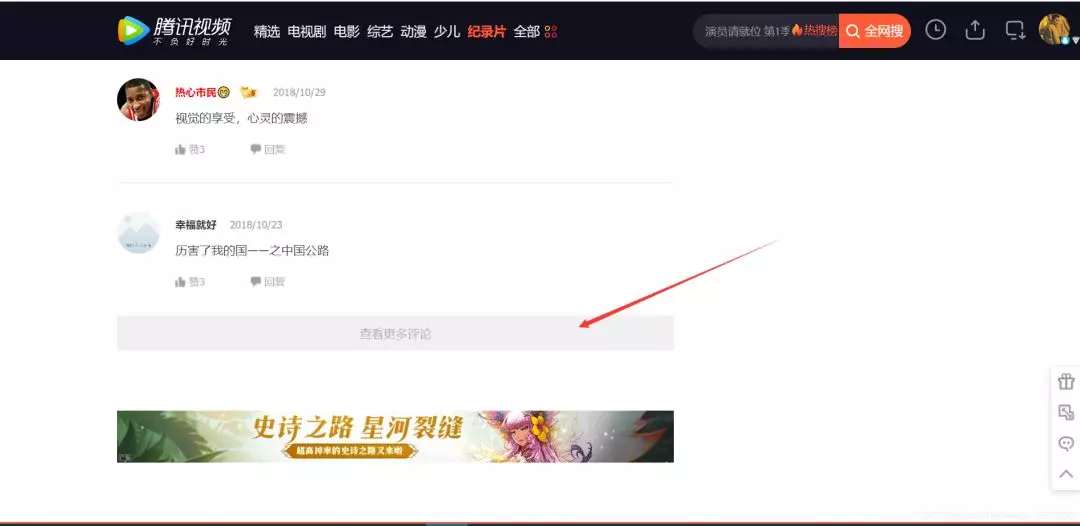
From the figure above, we can see that the review uses the new Ajax asynchronous refresh technology.That way, you can't use the previous method of analyzing the current page to find out the rules.Because only some of the comments are on the displayed page, a large number of comments have not been refreshed.
At this point, we should think of using snapping packages to analyze the rule of refreshing comment pages.In the future, most of the crawlers will use the crawling technology to analyze the rules first!
2. Use Fiddler to do package analysis - get the rule of comment Web address
How fiddler grabs packages, a point of knowledge that requires the reader to learn by himself, is beyond the scope of this blog discussion.
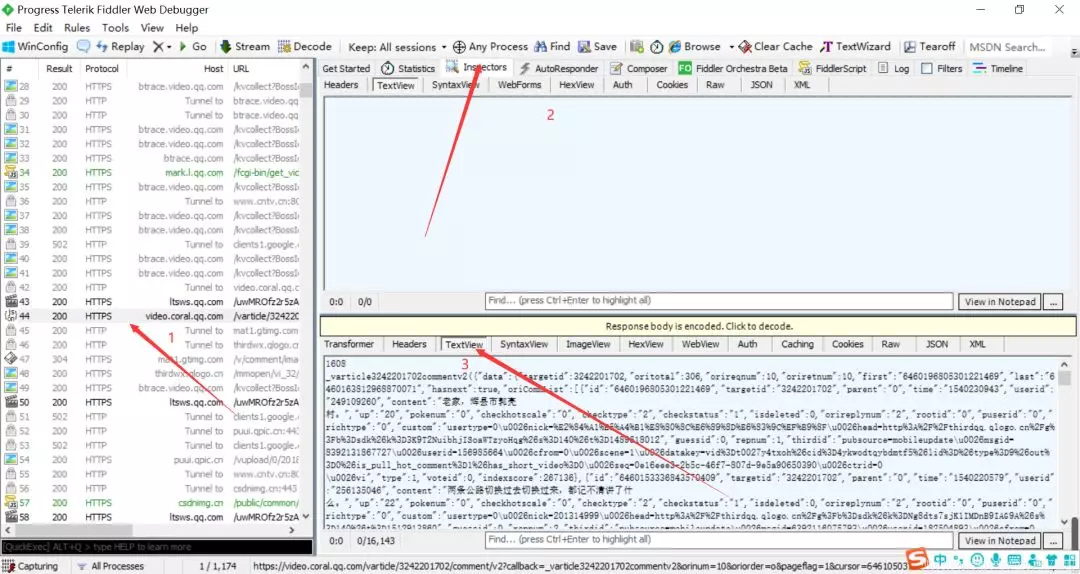
By comparing the contents of the two pictures above, you can see that this JS is the comment store page.(This requires everyone to find one by one, Ajax is usually inside JS, so this can also be compared with JS)
Let's copy the url of this JS: right click > copy > Just url
You can repeat the operation several times, find more URLs of JS, and get the rule from the url.Below is the URL of the JS I refreshed four times:
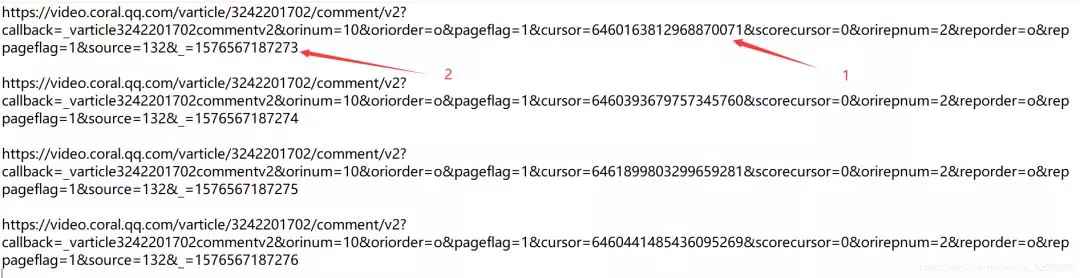
From the figure above, we find two different url s: cursor=?Second is =?.
We will soon find =?The rule is from 156567187273 plus 1.And cursor=?The rules are not visible.How can I find its rules at this time?
Baidu look to see if predecessors have ever crawled this type of website to find out the law according to their rules and methods.
Wool comes out of sheep.We need to be bold - will this cursor=? You can get it from the last JS page?It's just one of many bold ideas, so let's try one idea at a time.
We will use the second method, go to js to find.Copy one of the URLs as:
url = https://video.coral.qq.com/varticle/3242201702/comment/v2?callback=_varticle3242201702commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6460163812968870071&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1576567187273
Go to the browser and open it. Search for cursor= for the next URL of this url?Value of.We found a surprise!
The following:
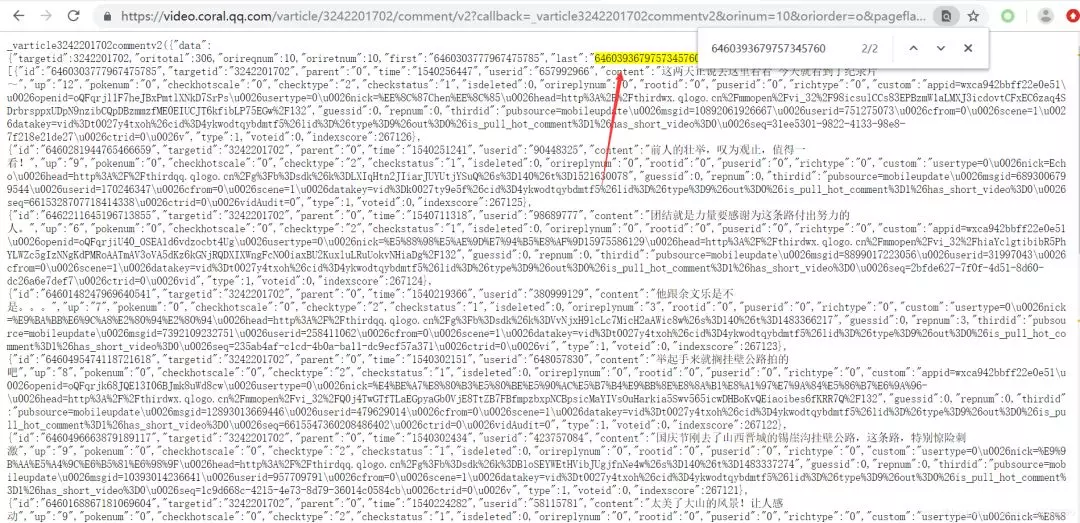
In general, we have to try a few more times to make sure that our idea is correct.
So far, we've found a pattern between the URLs of comments:
-
_=?From 156567187273 plus 1
-
cursor=?The value of exists in the previous JS.
3. Coding
1 import re 2 import random 3 import urllib.request 4 5 #Build User Agent 6 uapools=["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36", 7 "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36", 8 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0", 9 ] 10 #Randomly select a user agent from the user agent pool 11 def ua(uapools): 12 thisua=random.choice(uapools) 13 #print(thisua) 14 headers=("User-Agent",thisua) 15 opener=urllib.request.build_opener() 16 opener.addheaders=[headers] 17 #Set as Global Variable 18 urllib.request.install_opener(opener) 19 20 #Get Source Code 21 def get_content(page,lastId): 22 url="https://video.coral.qq.com/varticle/3242201702/comment/v2?callback=_varticle3242201702commentv2&orinum=10&oriorder=o&pageflag=1&cursor="+lastId+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_="+str(page) 23 html=urllib.request.urlopen(url).read().decode("utf-8","ignore") 24 return html 25 26 #Data to get comments from source 27 def get_comment(html): 28 pat='"content":"(.*?)"' 29 rst = re.compile(pat,re.S).findall(html) 30 return rst 31 32 #Get the next refresh from source ID 33 def get_lastId(html): 34 pat='"last":"(.*?)"' 35 lastId = re.compile(pat,re.S).findall(html)[0] 36 return lastId 37 38 def main(): 39 ua(uapools) 40 #Initial Page 41 page=1576567187274 42 #Initial page to refresh ID 43 lastId="6460393679757345760" 44 for i in range(1,6): 45 html = get_content(page,lastId) 46 #Get comment data 47 commentlist=get_comment(html) 48 print("------No."+str(i)+"Round Page Comments------") 49 for j in range(1,len(commentlist)): 50 print("No."+str(j)+"Comments:" +str(commentlist[j])) 51 #Get the next refresh page ID 52 lastId=get_lastId(html) 53 page += 1 54 55 main()
4. Result Display
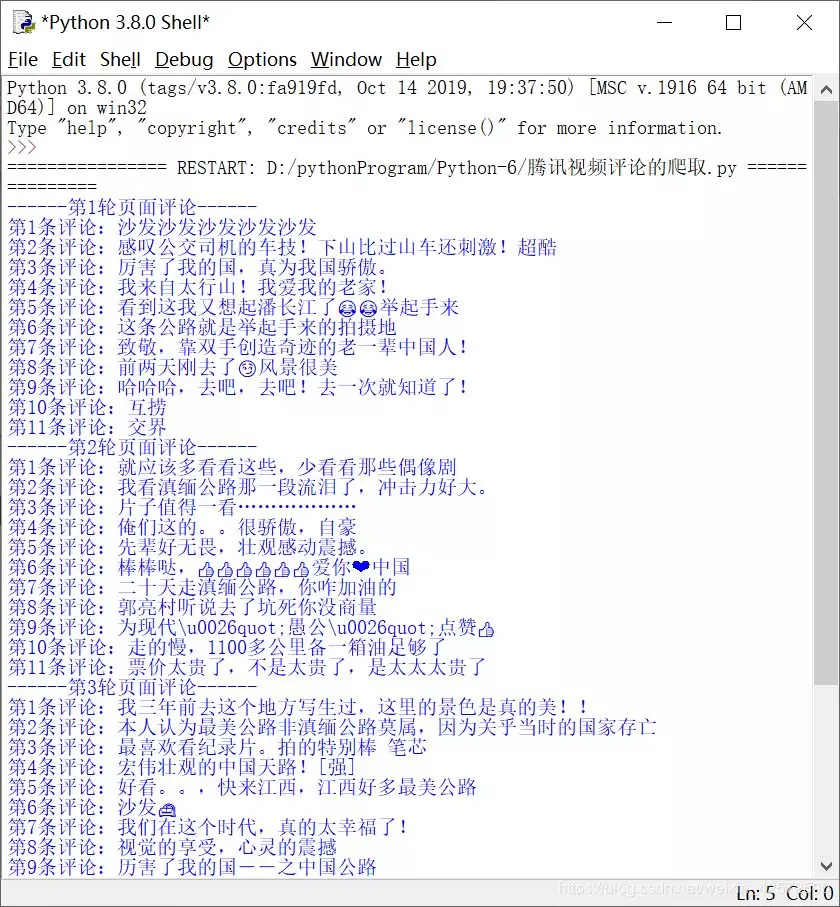 .
.