Knowledge is like rags, remember to "sew a seam" before you can show up magnificently.
Recently, there has been a strong interest in python crawlers. Here we share our learning path and welcome your suggestions. We communicate with each other and make progress together.
1. Development tools
The tool I use is sublime text3, which is so short and pithy that I'm fascinated by the word, which men probably don't like. I recommend you to use it. Of course, if your computer is well configured, pycharm may be more suitable for you. Sublime text 3 builds python development environment recommendation to check this blog: [sublime builds python development environment] [http://www.cnblogs.com/codefish/p/4806849.html]
2. Introduction to Reptiles
As the name implies, a crawler is like a worm, crawling on the Internet. In this way, we can get what we want. Since we want to climb on the Internet, we need to know the URL, the code name "Unified Resource Locator" and the nickname "Link". Its structure consists of three parts: (1) Protocol: such as the HTTP protocol that we often use in Web sites. (2) Domain name or IP address: domain name, such as www.baidu.com, IP address, which is the corresponding IP after domain name resolution. (3) Path: directory or file, etc.
3.urllib develops the simplest reptile
(1) Introduction to urllib
| Module | Introduce |
|---|---|
| urllib.error | Exception classes raised by urllib.request. |
| urllib.parse | Parse URLs into or assemble them from components. |
| urllib.request | Extensible library for opening URLs. |
| urllib.response | Response classes used by urllib. |
| urllib.robotparser | Load a robots.txt file and answer questions about fetchability of other URLs. |
(2) Developing the simplest reptiles
Baidu's home page is simple and generous, which is very suitable for our crawlers. The crawler code is as follows:
from urllib import request def visit_baidu(): URL = "http://www.baidu.com" # open the URL req = request.urlopen(URL) # read the URL html = req.read() # decode the URL to utf-8 html = html.decode("utf_8") print(html) if __name__ == '__main__': visit_baidu()
The results are as follows:
We can compare the results of our operation by right-clicking in the blank of Baidu homepage to see the review elements. Of course, request can also generate a request object, which can be opened using the urlopen method. The code is as follows:
from urllib import request def vists_baidu(): # create a request obkect req = request.Request('http://www.baidu.com') # open the request object response = request.urlopen(req) # read the response html = response.read() html = html.decode('utf-8') print(html) if __name__ == '__main__': vists_baidu()
The result is the same as before.
(3) Error handling
Error handling is handled by urllib module, mainly URLError and HTTP Error errors, where HTTP Error errors are subclasses of URLError errors, that is, HTTRPError can also be captured by URLError. HTTP Error can be captured by its code attribute. The code for handling HTTP Error is as follows:
from urllib import request from urllib import error def Err(): url = "https://segmentfault.com/zzz" req = request.Request(url) try: response = request.urlopen(req) html = response.read().decode("utf-8") print(html) except error.HTTPError as e: print(e.code) if __name__ == '__main__': Err()
The result of operation is as follows:
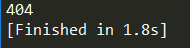
404 is the error code printed out, you can Baidu for this detailed information. URLError can be captured by its reason attribute. The code for chuliHTTPError is as follows:
from urllib import request from urllib import error def Err(): url = "https://segmentf.com/" req = request.Request(url) try: response = request.urlopen(req) html = response.read().decode("utf-8") print(html) except error.URLError as e: print(e.reason) if __name__ == '__main__': Err()
The result of operation is as follows:

Since you're dealing with errors, it's better to write both errors into your code, after all, the more detailed and clear they are. Note that HTTPError is a subclass of URLError, so you must put HTTPError in front of URLError, otherwise URLError will be output, such as 404 output as Not Found. The code is as follows:
from urllib import request from urllib import error # The first method, URLErroe and HTTPError def Err(): url = "https://segmentfault.com/zzz" req = request.Request(url) try: response = request.urlopen(req) html = response.read().decode("utf-8") print(html) except error.HTTPError as e: print(e.code) except error.URLError as e: print(e.reason)
You can change the url to see various forms of error output.
It's not easy for a new comer to come here. If you feel that you have lost something, please don't be stingy with your appreciation.