preface
In the recent working code, I encountered some small problems, resulting in my update being much slower. Today, I want to share with you the problems I encountered before, and teach you through a practical content. I hope that when you encounter similar problems in the future, you can think of my article and solve the problems.
What I want to share today is about parsing xml files.
What is XML
XML refers to extensible markup language, a subset of standard general markup language. It is a markup language used to mark electronic documents to make them have structure. XML is designed to transmit and store data. XML is a set of markup rules that define semantics. These markup will and identify many parts of a document. It is also a meta markup language, that is, it defines the syntactic language used to define semantic and structured markup languages related to other fields
Python parsing of XML
There are two common XML interfaces: DOM and SAX. These two interfaces deal with XML in different ways and use different scenarios.
- SAX(simple API for XML)
Python standard library includes SAX parser. SAX uses event driven model to process XML files by triggering events and calling user-defined callback functions in the process of parsing XML.
- DOM(Document Object Model)
Parse the XML data into a tree in memory, and operate the XML through the operation of the tree.
The XML file used in this sharing is movies XML, as follows:
<collection shelf="New Arrivals"> <movie title="Enemy Behind"> <type>War, Thriller</type> <format>DVD</format> <year>2003</year> <rating>PG</rating> <stars>10</stars> <description>Talk about a US-Japan war</description> </movie> <movie title="Transformers"> <type>Anime, Science Fiction</type> <format>DVD</format> <year>1989</year> <rating>R</rating> <stars>8</stars> <description>A schientific fiction</description> </movie> <movie title="Trigun"> <type>Anime, Action</type> <format>DVD</format> <episodes>4</episodes> <rating>PG</rating> <stars>10</stars> <description>Vash the Stampede!</description> </movie> <movie title="Ishtar"> <type>Comedy</type> <format>VHS</format> <rating>PG</rating> <stars>2</stars> <description>Viewable boredom</description> </movie> </collection>
At present, our common parsing method is to use DOM module for parsing.
Python parsing XML example
from xml.dom.minidom import parse
import xml.dom.minidom
# Open the XML document using the minidom parser
DOMTree = xml.dom.minidom.parse('movies.xml') # Return Document object
collection = DOMTree.documentElement # Get element action object
# print(collection)
if collection.hasAttribute('shelf'):
print('Root element : %s' % collection.getAttribute('shelf'))
# Get all movies in the collection
movies = collection.getElementsByTagName('movie') # Return all movie tags and save them in the list
# print(movies)
for movie in movies:
print('*******movie******')
if movie.hasAttribute('title'):
print('Title: %s' % movie.getAttribute('title'))
type = movie.getElementsByTagName('type')[0]
print('Type: %s' % type.childNodes[0].data) # Gets the content of the label element
format = movie.getElementsByTagName('format')[0]
print('format: %s' % format.childNodes[0].data)
rating = movie.getElementsByTagName('rating')[0]
print('rating: %s' % rating.childNodes[0].data)
description = movie.getElementsByTagName('description')[0]
print('description: %s' % description.childNodes[0].data)
Iqiyi barrage
Recently, there was a new play called "redundant son-in-law", which must have been seen by everyone. Today, our actual combat content is to capture the barrage sent by the audience and share the content I encountered in the process of crawling.
Analyze web pages
Generally speaking, the screen barrage cannot appear in the web source code, so the preliminary judgment is to load the barrage data asynchronously.
First, open the developer tool -- > click Network -- > and click XHR
image
To find a URL similar to the one shown above, we only need: / 54 / 00 / 7973227714515400.
Iqiyi's barrage address is as follows:
https://cmts.iqiyi.com/bullet / Parameter1_ 300_ Parameter 2 z
Parameter 1 is: / 54 / 00 / 7973227714515400
Parameter 2 is: numbers 1, 2, 3
Iqiyi will load the barrage every 5 minutes, and each episode will take about 46 minutes. Therefore, the link of the barrage is as follows:
https://cmts.iqiyi.com/bullet/54/00/7973227714515400_300_1.z https://cmts.iqiyi.com/bullet/54/00/7973227714515400_300_2.z https://cmts.iqiyi.com/bullet/54/00/7973227714515400_300_3.z . . . https://cmts.iqiyi.com/bullet/54/00/7973227714515400_300_10.z
Data decoding
When you copy the above URL to the browser, you will find that you can download one directly z is the suffix of the compressed package. windows cannot open it directly. You can only decode the compressed package through Python first.
Here, I will briefly explain the zlib library, which is used to compress and decompress data streams.
Therefore, we can decompress the downloaded packets.
First, the data packet needs to be read in binary mode, and then decompressed.
Take the compressed package I just downloaded as an example.
The specific code is as follows:
import zlib
with open('7973227714515400_300_1.z', 'rb') as f:
data = f.read()
decode = zlib.decompress(bytearray(data), 15 + 32).decode('utf-8')
print(decode)
The operation results are as follows:

image
I wonder if you find that this kind of data is very similar to XML, so we might as well write two more lines of code to save the data as an XML file.
The specific code is as follows:
import zlib
with open('7973227714515400_300_1.z', 'rb') as f:
data = f.read()
decode = zlib.decompress(bytearray(data), 15 + 32).decode('utf-8')
with open('zx-1.xml', 'w', encoding='utf-8') as f:
f.write(decode)
The obtained XML file contents are as follows:
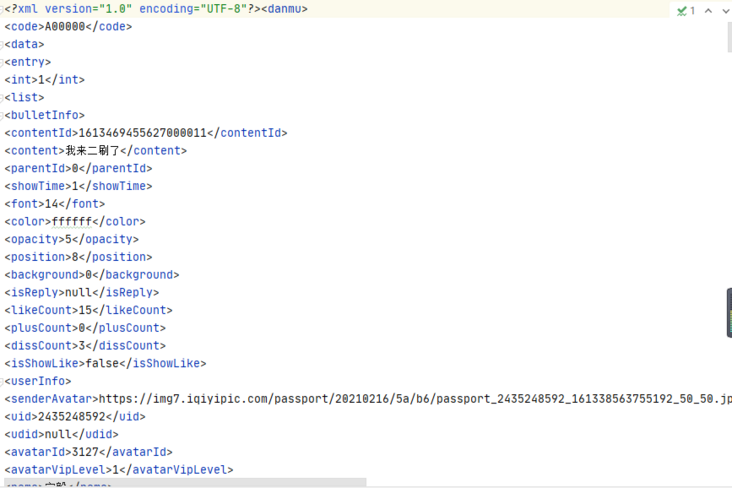
image
Is it a little surprise to see the running results? According to what I said above, we can get the data we want.
Extract data
The specific code is as follows:
from xml.dom.minidom import parse
import xml.dom.minidom
DOMTree = xml.dom.minidom.parse('zx-1.xml')
collection = DOMTree.documentElement
entrys = collection.getElementsByTagName('entry')
for entry in entrys:
content = entry.getElementsByTagName('content')[0].childNodes[0].data
print(content)
The operation results are as follows:

image
Now we all understand the idea of web page analysis and data acquisition.
Now we need to go back to the starting point. We need to construct the barrage URL, send a request to the URL, obtain its binary data, decompress it and save it as an XML file, and finally extract the barrage data from the file.
Construct URL
The specific code is as follows:
# Construct URL
def get_urls(self):
urls = []
for x in range(1, 11):
url = f'https://cmts.iqiyi.com/bullet/54/00/7973227714515400_300_{x}.z'
urls.append(url)
return urls
Save XML file
The specific code is as follows:
# Save xml file
def get_xml(self):
urls = self.get_urls()
count = 1
for url in urls:
content = requests.get(url, headers=self.headers).content
decode = zlib.decompress(bytearray(content), 15 + 32).decode('utf-8')
with open(f'../data/zx-{count}.xml', 'a', encoding='utf-8') as f:
f.write(decode)
count += 1
Pit avoidance:
1. First, the content we want to get is actually a compressed package, so our headers should read as follows:
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'Accept-Encoding': 'gzip, deflate'
}
Avoid the following errors:
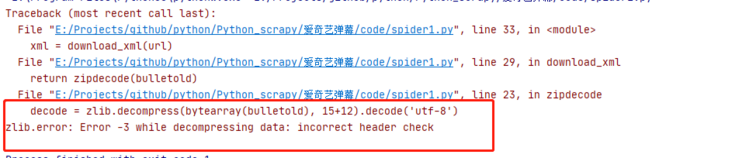
image
2. The saved xml file cannot be named in Chinese. Another point is that you'd better add one -, as follows:
zx-0 zx-1 . . . zx-9
Avoid the following errors:

image
After saving all the XML files, comment out the crawler code temporarily, because next we need to extract the data from the above files.
Extract data
# Extract data
def parse_data(self):
danmus = []
for x in range(1, 11):
DOMTree = xml.dom.minidom.parse(f'../data/zx-{x}.xml')
collection = DOMTree.documentElement
entrys = collection.getElementsByTagName('entry')
for entry in entrys:
danmu = entry.getElementsByTagName('content')[0].childNodes[0].data
danmus.append(danmu)
# print(danmus)
df = pd.DataFrame({
'bullet chat': danmus
})
return df
Here we just used the XML parsing method we just learned. So for us, there is basically no problem for us to extract the bullet screen inside.
Save data
# Save data
def save_data(self):
df = self.parse_data()
df.to_csv('../data/danmu.csv', encoding='utf-8-sig', index=False)
Comment content word cloud

image
Guys, please note that this is only the first episode. There are more than 2000 bullet screens. It can be seen that this play is still popular.
last
Nothing can be accomplished overnight. Life is like this, so is learning!
Therefore, where can there be any saying of three-day and seven-day quick success?
Only by persistence can we succeed!