Recently, I used Python and wrote several crawlers to practice. There are many online tutorials, but some can't climb. The main reason is that the website is often changed, but crawlers still have a common idea, that is, downloading data, parsing data and saving data. Let's talk about it.
1. Download data
First, open the website to be crawled and analyze the URL. Every time you open a web page to see what changes the URL has, it is possible to bring some data of the previous web page, such as xxID. Then we need to analyze HTML on the previous page and find the corresponding data. If the web source code cannot be found, it may be ajax asynchronous loading. Go to xhr to find it.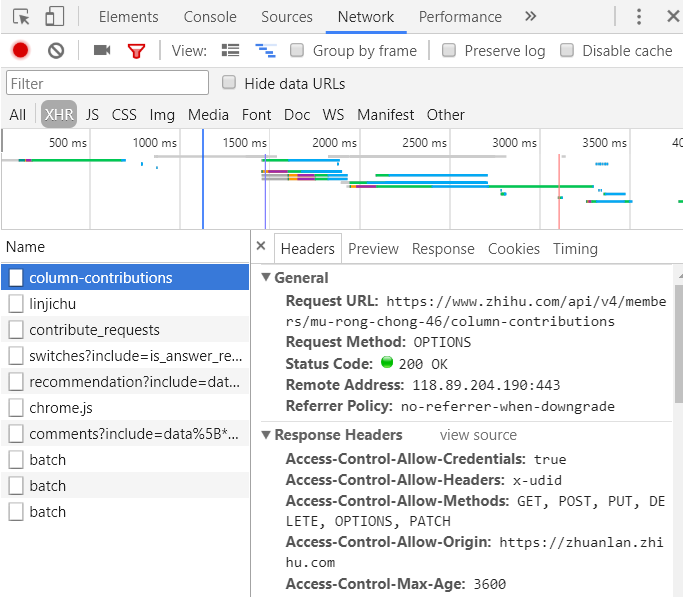
Some websites do anti crawling, and you can add user agent: judge browser
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
# Initialize headers
self.headers = {'User-Agent': self.user_agent}
If you can't, press F12 on Chrome to analyze the request header and request body to see if you need to add other information. For example, some websites have added referer to the source of the current web page, so we can bring it when we request. Press Ctrl + Shift + C to position the element on the HTML
Dynamic web page
Some web pages are dynamic web pages. When we get the web page, the data has not been requested. Of course, nothing can be extracted. There are only two ways to solve this problem with Python: directly collect the content from JavaScript code, or run JavaScript with Python's third-party library to directly collect the pages you see in the browser.
1. Find the request and see the returned content. The content of the web page may be here. Then you can copy the request. In the complex website, some messy ones can be deleted and meaningful parts can be retained. Remember to delete a small part and try to open the web page first. If it is successful, delete it again until it cannot be deleted.
2.Selenium: it is a powerful network data collection tool (but slow), which was originally developed for website automation testing. In recent years, it has also been widely used to obtain accurate website snapshots because they can run directly on browsers. Selenium library is an API called on WebDriver. It's a bit like a browser that can use WebDriver to load a website, but it can also be used to find page elements, interact with elements on the page (send text, click, etc.), and perform other actions to run a web crawler like a beautiful soup object.
Phantom JS: is a headless browser. It will load the website into memory and execute JavaScript on the page, but it will not show the user the graphical interface of the web page. By combining Selenium and phantom JS, you can run a very powerful web crawler that can handle cookie s, JavaScript, header s, and anything you need to do.
Module for downloading data
The modules for downloading data include urllib, urllib 2 and Requests
Compared with the other two, requests supports HTTP connection retention and connection pool, cookie session retention, file upload, automatic determination of response content encoding, and automatic encoding of internationalized URL and POST data. Moreover, the api is relatively simple, but requests can not be used asynchronously, and the speed is slow.
html = requests.get(url, headers=headers) #Yes, it's that simple
Urlib2 take my sister who climbed Taobao as an example
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
# Note: form data request parameters
params = 'q&viewFlag=A&sortType=default&searchStyle=&searchRegion=city%3A&searchFansNum=¤tPage=1&pageSize=100'
def getHome():
url = 'https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8'
req = urllib2.Request(url, headers=headers)
# decode ('utf - 8 ') decodes and converts other codes into unicode codes
# encode('gbk ') code converts unicode code into other codes
# "gbk".decode('gbk').encode('utf - 8')
# unicode = Chinese
# gbk = English
# utf - 8 = Japanese
# English one > Chinese one > Japanese, unicode is equivalent to converter
html = urllib2.urlopen(req, data=params).read().decode('gbk').encode('utf-8')
# json to object
peoples = json.loads(html)
for i in peoples['data']['searchDOList']:
#Go to the next page to get the data
getUseInfo(i['userId'], i['realName'])
2. Analyze data
There are also many ways to parse data. I only looked at beatifulsoup and regular. This example is parsed with regular
def getUseInfo(userId, realName):
url = 'https://mm.taobao.com/self/aiShow.htm?userId=' + str(userId)
req = urllib2.Request(url)
html = urllib2.urlopen(req).read().decode('gbk').encode('utf-8')
pattern = re.compile('<img.*?src=(.*?)/>', re.S)
items = re.findall(pattern, html)
x = 0
for item in items:
if re.match(r'.*(.jpg")$', item.strip()):
tt = 'http:' + re.split('"', item.strip())[1]
down_image(tt, x, realName)
x = x + 1
print('Download complete')
Regular expression description
- Match: matches the beginning of a string, returns Match object if successful, returns None if failed, and only matches one.
- Search: search in a string. Match object is returned if it succeeds. None is returned if it fails. There is only one match.
- Find all: find all successful matching groups in the string, that is, the parts enclosed in parentheses. Return the list object. Each list item is a list composed of all matching groups.
1).? Is a fixed collocation, *** And represent can match any infinite number of characters, plus? It means to use non greedy pattern for matching, that is, we will make matching as short as possible (2) (.?) Represents a group, if there are 5 (. *?) It means that five groups are matched
3) In regular expressions, "." The function of is to match any character except "\ n", that is, it matches in one line. The "line" here is distinguished by "\ n". The HTML tag has a "\ n" at the end of each line, but it is not visible. If re is not used S parameter, only match in each line. If there is no line, change to the next line and start again without crossing lines. And use re After the S parameter, the regular expression will take the string as a whole, add "\ n" as an ordinary character to the string, and match it in the whole.
3. Save data
After data analysis, it can be saved to a file or database. This example is saved to a file, which is very simple.
def down_image(url, filename, realName):
req = urllib2.Request(url=url)
folder = 'e:\\images\\%s' % realName
if os.path.isdir(folder):
pass
else:
os.makedirs(folder)
f = folder + '\\%s.jpg' % filename
if not os.path.isfile(f):
print f
binary_data = urllib2.urlopen(req).read()
with open(f, 'wb') as temp_file:
temp_file.write(binary_data)
Finally, thank you for reading. Each of your likes, comments and sharing is our greatest encouragement. Refill ~
If you have any questions, please discuss them in the comment area!
If there is anything wrong, welcome guidance!