1. Analyze web pages
When we go to crawl a web page, the first thing we need to do is to analyze the structure of the web page, and then we will find the corresponding laws, as follows: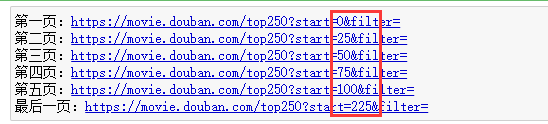
Generate link: you can write a for loop from the law of web page link to generate its link. Its interval is 25. The program is as follows:
for page in range (0,226,25):
url ="https://movie.douban.com/top250?start=%s&filter="%page
print (url)
The results are as follows: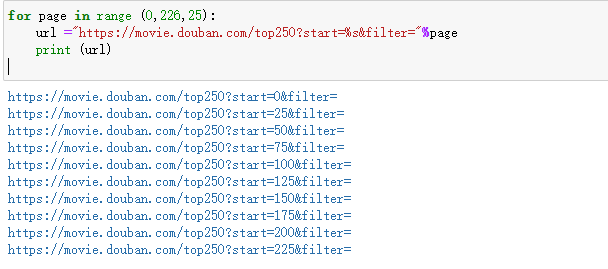
2. Request server
Before crawling the web page, we need to make a request to the server
2.1 import package
If the requests package is not installed, install it first. The steps are: 1. Run win + R - 2. Enter CMD - 3. Enter the command pip install requests
2.2 setting up browser proxy
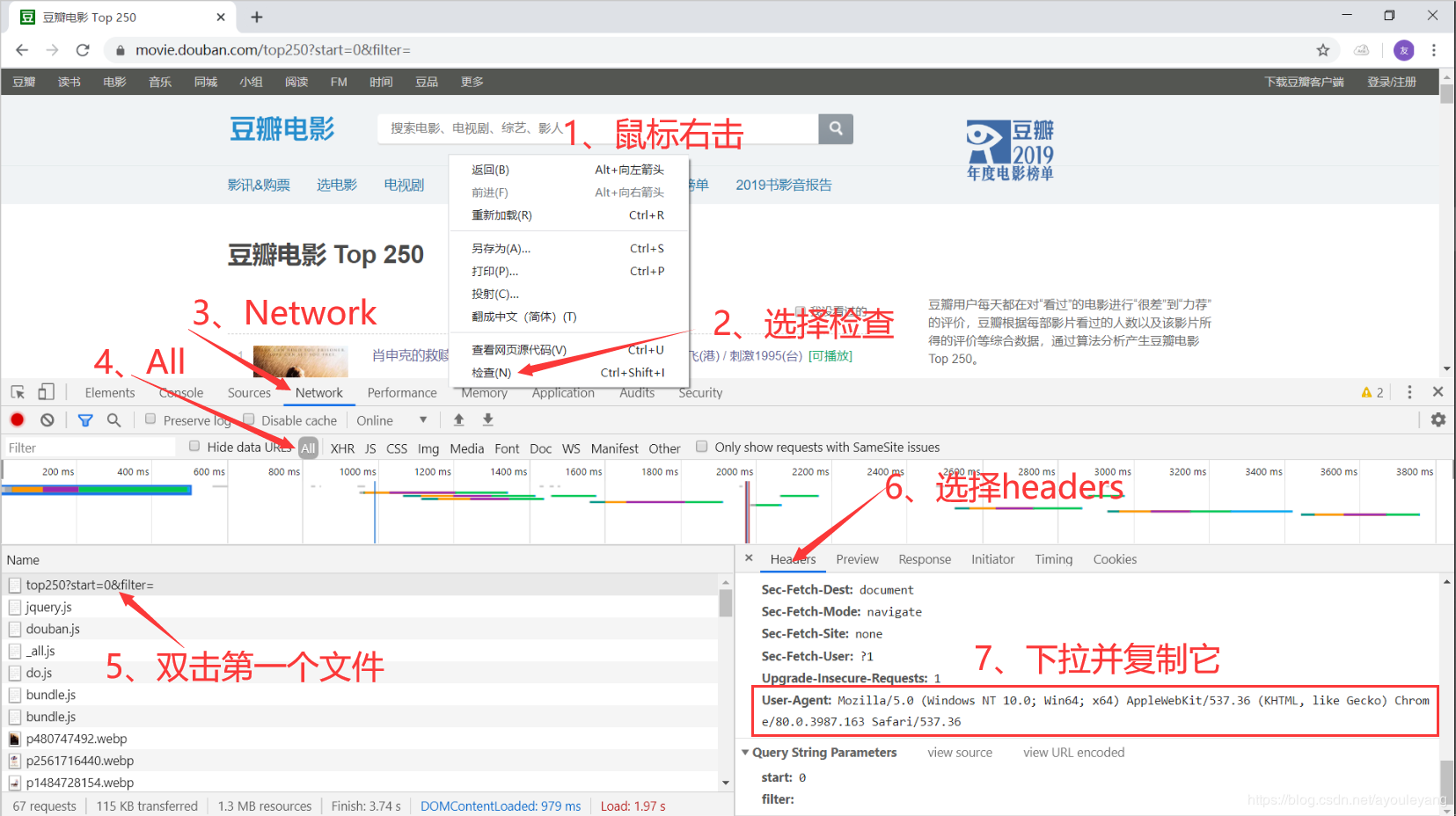
The code to set up the browser agent is as follows:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
2.3 request server format
Request source code to send a request to the server. If. Text is added after it, the output text content will be shown as follows:
requests.get(url = test_url, headers = headers)
2.4 request server code summary
import requests
#pip install requests - > Win + R, run - > CMD, enter - > pip
test_url = 'https://Movie. Double. COM / top250? Start = 0 & filter = 'ා' format as string
#Set up browser proxy, which is a dictionary
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
#Request source code, send request to server, 200 represents success
reponse = requests.get(url = test_url, headers = headers).text
# Shortcut key run, Ctrl+Enter
3.xpath extraction information
3.1 method of getting xpath node
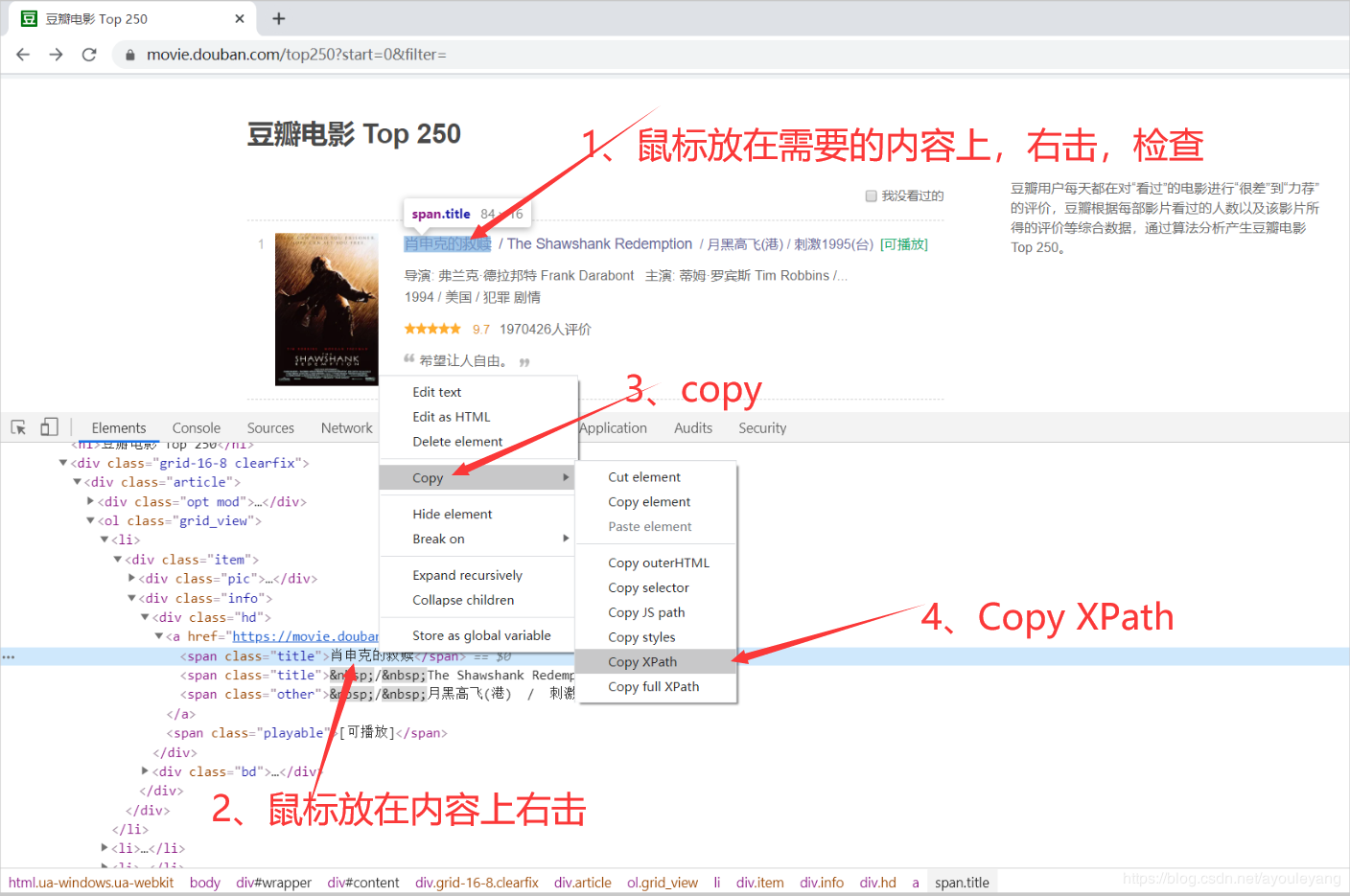
3.2xpath extract content
from lxml import etree #Import resolution Library html_etree = etree.HTML(reponse) # Think of it as a sieve, a tree
3.2.1 extract text
When we extract the text in the tag, we need to add / text() after the copied xpath
Such as farewell my concubine:
<span class="title">Farewell to my concubine</span>
xpath:
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
Extract text:
name = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]/text()')
print ("This is in array form:",name)
print ("This is in string form:",name[0])
3.2.2 extract links
When we extract the link, we need to add / @ href after the copied xpath to specify the extraction link,
movie_url = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/@href')
print ("This is in array form:",movie_url)
print ("This is in string form:",movie_url[0])
The results are as follows:
3.2.3 extract label elements
Extracting tag elements is the same as extracting links, but you need to add / @ class after it,
rating = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[1]/@class')
print ("This is in array form:",rating)
print ("This is in string form:",rating[0])
The results are as follows:
4. Regular expression
4.1 extraction of fixed position information
In regular expressions, we use (. *?) to extract the information we want. When we use regular expressions, we usually import the re package first. For example:
import re
test = "I am js"
text = re.findall("I am.*?",test)
print (text)
The results are as follows:
4.2 match numbers
For example, if we want to match how many people evaluate this movie, we can write as follows:
import re
data = "1059232 Human evaluation"
num = re.sub(r'\D', "", data)
print("The number here is:", num)
The results are as follows: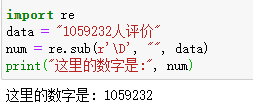
5. Extract all information from a page
For example, here we extract the movie name of the last page, as follows:
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
name = item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
print (name)
The results are as follows: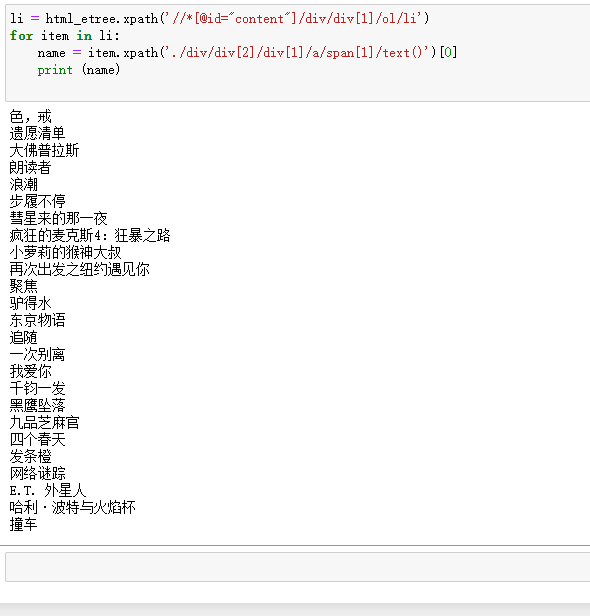
In this way, we can get everything down.
6. Write content to text csv
The code is as follows:
import csv
# Create folder and open
fp = open("./Bean paste top250.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #I want to write
# Write contents
writer.writerow(('ranking', 'Name', 'link', 'Star class', 'score', 'Number of people assessed'))
#Close file
fp.close()
7. Summarize all the codes
import requests, csv, re
from lxml import etree
#Set up browser proxy, which is a dictionary
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
# Create folder and open
fp = open("./Bean paste top250.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #I want to write
# Write contents
writer.writerow(('ranking', 'Name', 'link', 'Star class', 'score', 'Number of people assessed'))
for page in range(0, 226, 25): #226
print ("Getting%s page"%page)
url = 'https://movie.douban.com/top250?start=%s&filter='%page
#Request source code, send request to server, 200 represents success, back to it, Ctrl +]
reponse = requests.get(url = url, headers = headers).text
# Shortcut key run, Ctrl+Enter
html_etree = etree.HTML(reponse) # Think of it as a sieve, a tree
# filter
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
#ranking
rank = item.xpath('./div/div[1]/em/text()')[0]
#Movie title
name = item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
#link
dy_url = item.xpath('./div/div[2]/div[1]/a/@href')[0]
#score
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
rating = re.findall('rating(.*?)-t', rating)[0]
if len(rating) == 2:
star = int(rating) / 10 #int() converted to number
else:
star = rating
# Note ctrl+?
rating_num = item.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]
content = re.sub(r'\D', "", content)
# print (rank, name, dy_url, star, rating_num, content)
# Write contents
writer.writerow((rank, name, dy_url, star, rating_num, content))
fp.close()
The results are as follows: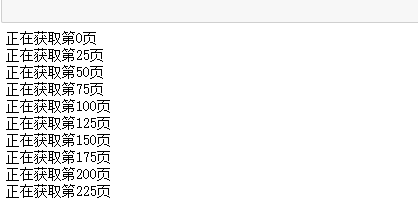
Results in csv file: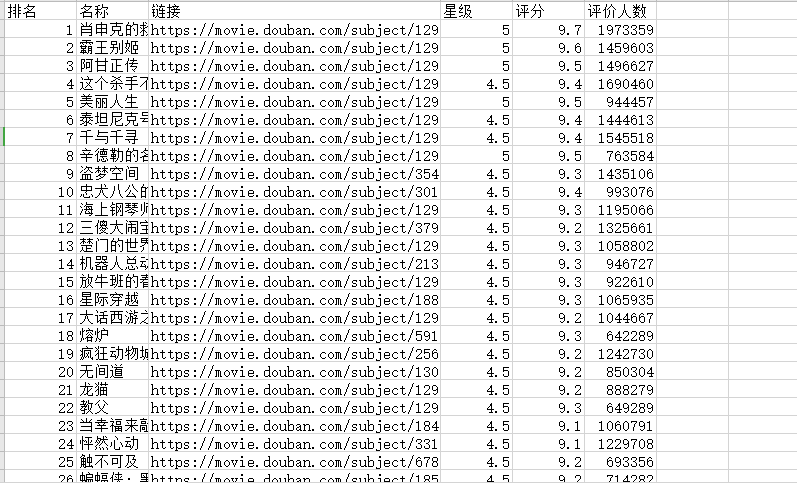
The last climb is over.