As mentioned earlier, we usually need to clean up the data before we can use large data sets to train learning algorithms. In other words, we need a method to detect and correct errors in the data. Although any given data set may have various bad data, such as outliers or incorrect values, the bad data type we almost always encounter is the lack of values. As we saw earlier, Pandas assigns NaN values to missing values. In this, we will learn how to detect and process NaN values.
First, we will create a DataFrame with some NaN values.
# We create a list of Python dictionaries
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes':8, 'suits':45},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5, 'shirts': 2, 'shoes':5, 'suits':7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes':10}]
# We create a DataFrame and provide the row index
store_items = pd.DataFrame(items2, index = ['store 1', 'store 2', 'store 3'])
# We display the DataFrame
store_items
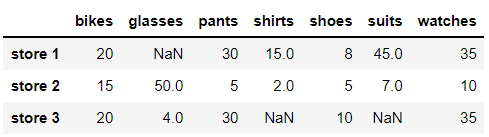
It can be clearly seen that the DataFrame we created has three NaN values: one in store 1 and two in store 3. However, if we load a very large dataset into the DataFrame, which may have millions of data, it is not easy to intuitively find the number of NaN values. For these cases, we use a combination of methods to calculate the number of NaN values in the data. The following example uses both. isnull() and sum() methods to calculate the number of NaN values in our DataFrame.
# We count the number of NaN values in store_items
x = store_items.isnull().sum().sum()
# We print x
print('Number of NaN values in our DataFrame:', x)
umber of NaN values in our DataFrame: 3
In the above example, the. isnull() method returns a size and store_ Boolean DataFrame like items, with True representing elements with NaN value and False representing elements with non NaN value. Let's take an example:
store_items.isnull()
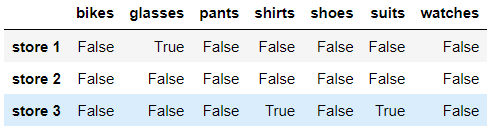
In Pandas, the numeric value of the logical value True is 1 and the numeric value of the logical value False is 0. Therefore, we can count the number of NaN values by counting the number of logical values True. To count the total number of logical values True, we use the. sum() method twice. This method is used twice because the first sum() returns a Pandas Series, which stores the total number of logical values True on the column, as shown below:
store_items.isnull().sum()
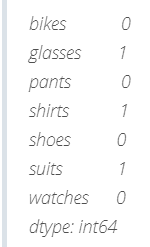
The second sum() adds the 1 in the above Pandas Series.
In addition to counting the number of NaN values, we can also count the number of non NaN values in the opposite way. To do this, we can use the. count() method as follows:
# We print the number of non-NaN values in our DataFrame
print()
print('Number of non-NaN values in the columns of our DataFrame:\n', store_items.count())

Now that we know how to determine whether there are any NaN values in the dataset, the next step is to decide how to deal with these NaN values. In general, we have two options to delete or replace NaN values. In the following example, we will introduce these two methods.
First, we will learn how to delete rows or columns containing any NaN values from the DataFrame. If axis = 0, the. dropna(axis) method deletes any rows containing NaN values, and if axis = 1, the. dropna(axis) method deletes any columns containing NaN values. Let's look at some examples:

Note that the. dropna() method does not delete rows or columns with NaN values in place. That is, the original DataFrame will not change. You can always set the keyword inplace to True in the dropna() method to delete the target row or column in place.
Now, instead of deleting NaN values, we replace them with appropriate values. For example, we can choose to replace all NaN values with 0. To do this, we can use the. fillna() method, as shown below.
# We replace all NaN values with 0 store_items.fillna(0)
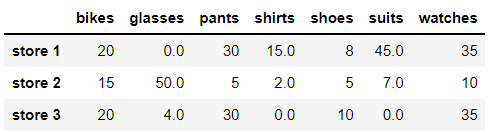
We can also use the. fillna() method to replace the NaN value with the previous value in the DataFrame, which is called forward padding. When replacing NaN values with forward padding, we can use the previous value in the column or row Fillna (method = 'fill', axis) will replace the NaN value with the last known value along the given axis through the fill forward method. Let's look at some examples
# We replace NaN values with the previous value in the column store_items.fillna(method = 'ffill', axis = 0)
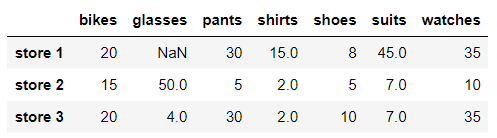
Note that the two NaN values in store 3 are replaced with the previous value in their column. Note, however, that the NaN value in store 1 is not replaced. Because there is no value in front of this column, because the NaN value is the first value of this column. However, this does not happen if the previous row value is used for forward padding. Let's take a look at the specific situation:
# We replace NaN values with the previous value in the row store_items.fillna(method = 'ffill', axis = 1)
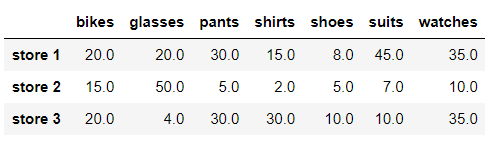
We see that in this case, all NaN values are replaced with the previous row values.
Similarly, you can choose to replace the NaN value with the later value in the DataFrame, which is called backward padding fillna(method = 'backfill', axis) replaces the NaN value with the next known value along the given axis through the backfill method. As with forward padding, we can choose to use row or column values. Let's look at some examples:
# We replace NaN values with the next value in the column store_items.fillna(method = 'backfill', axis = 0)
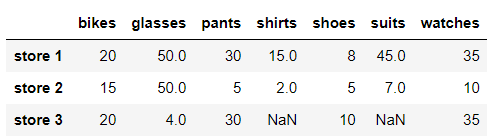
Notice that the NaN value in store 1 is replaced with the next value in the column in which it is located. Note, however, that the two NaN values in store 3 are not replaced. Because there is no next value in these columns, these NaN values are the last value in these columns. However, this does not happen if you use the next row value for backward padding. Let's take a look at the specific situation:
# We replace NaN values with the next value in the row store_items.fillna(method = 'backfill', axis = 1)
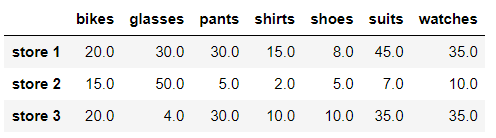
Note that the. Fillna () method does not replace (populate) NaN values in place. That is, the original DataFrame will not change. You can always set the keyword inplace to True in the fillna() function to replace the NaN value in place.
We can also choose to replace NaN values with different interpolation methods. For example, the. interpolate(method = 'linear', axis) method will replace the NaN value with a value along a given axis through linear interpolation. Let's look at some examples:
# We replace NaN values by using linear interpolation using column values store_items.interpolate(method = 'linear', axis = 0)
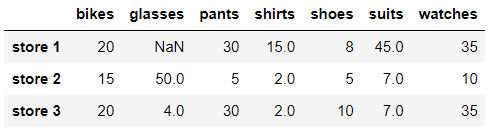
Note that the two NaN values in store 3 are replaced by linear interpolation. Note, however, that the NaN value in store 1 is not replaced. Because the NaN value is the first value in the column and there is no data in front of it, the interpolation function cannot calculate the value. Now we insert values using row values:
# We replace NaN values by using linear interpolation using row values store_items.interpolate(method = 'linear', axis = 1)
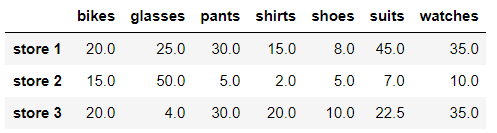
Like the other methods we've seen, the. interpolate() method doesn't replace the NaN value in place.