[python] download the video of Chinese University MOOC
Script target:
Enter the course id and cookie to download the video file of the whole course for easy review
Analysis of anti climbing mechanism of website:
Purpose of analyzing data package: find the path to get m3u8 file
1. From the first step of analyzing the data package, I felt that the programmer must have made an anti crawling mechanism and took precautions from the beginning. When the website opens the debugging tool, it will loop on the debugger. For the code writing method and principle, please refer to this article[ How to prevent pages from being debugged_ Xiaominge's column - CSDN blog_ Web page debugging prohibited ], you only need to disable the breakpoint to continue debugging and view the data packet in the network
2. Search the keyword m3u8 to get the link to download m3u8
https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144bxxxxxxxxxxxx8ef_sd.m3u8?ak=7909bff134372bffca53cdc2c17adc27a4c38c6336120510aea1ae1790819de820f66b1081b2dbb1d6300ca9e91c8b349a14ab1e5b4e06c0887fe54fe47de9823059f726dc7bb86b92adbc3d5b34b1320647b25cf54eb8ac6ed1f0d7db7826b19bb0a5ea14ff29775bd482caa79ccf8b
Simplified get
https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144bxxxxxxxxxxxx8ef_sd.m3u8
Through get, download and view, the ts download link inside can be spliced, and the file is not encrypted. Therefore, you only need to send the data packet with request to download it. Next, look for the basis for constructing the data packet
3. After analyzing the data package, the download link of m3u8 file appears in the content accessed by another link
The link is: https://vod.study.163.com/eds/api/v1/vod/video?videoId=1215086738&signature=75584967794f373450387775426e39512b565a6d4a4643384a366b3743766e556474475a7454466252672b6c5252306a744e585a61365031766269547650504454724750544c683252715a475876585962727a536f7431736a596d4f7843593577306d714654534864385873446e5470397a5675537a7233486836336d7a4355576e506745582b47762f2b37574b6972745365744d673d3d&clientType=1
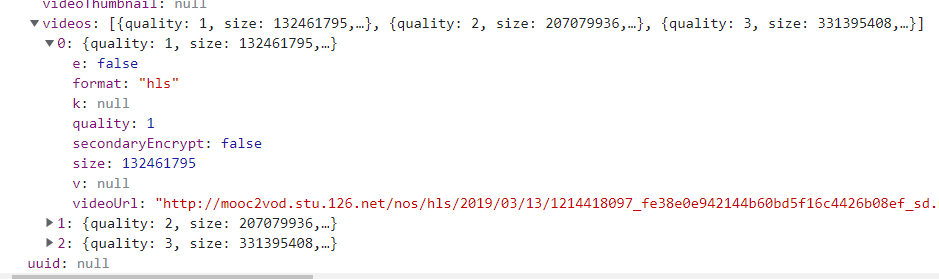
The link needs to be composed of two variables, videoId and signature. The two variables must correspond, otherwise they cannot be accessed, and they are transmitted in the form of http2, which is equivalent to ban dropping the request library. Next, you need to find the videoId and its corresponding signature
4. The signature value obtained by analyzing the data packet is included in the following url, which needs to be accessed through http2, and a data packet needs to be submitted by POST at the same time of access. The content of the data packet is "bizid = 1268148xxx & biztype = 1 & contenttype = 1"
https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=7d56f95de17346eeb0e0fd1d2d6b5751"
At this time, you need to find the values of bizId and csrfKey
5. After analyzing the data packet, bizid, the name of each class and the videoid (contentId) of each class are stored in the following url, which needs to be accessed through http2, and a data packet needs to be submitted POST at the same time. The content of the data packet is "termId: 1465388xxx"
https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey=7d56f95de17346eeb0e0fd1d2d6b575
The submitted value is the same as the value after tid in the course link. Only csrfKey needs to be filled in
6. The csrfKey is stored in the NTESSTUDYSI = of the cookie. You only need the cookie to get the csrfKey. At this point, you only need the cookie and course id to get the m3u8 file download link for each course
Known information:
1. Anti crawling mechanism of website
2. The video ts file is not encrypted
3. The website uses http2 protocol and httpx instead of request
4. After you get the download link of m3u8 file, you can directly throw it to the downloader of m3u8 written in the previous article. Change it and splice it together. It's OK to use it
5. Although the prompt during debugging is "illegal cross domain request", the value of referer is not judged, but the cookie value is judged
Script idea:
1. Get your own cookie and extract NTESSTUDYSI = csrfKey from the cookie
2. Use http2 x. And it is accessed by post“ https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey=csrfKey ", construct post packet termId: tid. Get the name of each class, videoid (contentId) and bizId (id) of each class in the obtained packet
3. Use http2 0, and it is accessed by post, and the access is subject to cross domain restrictions“ https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=csrfKey ”Construct post packet bizid = bizid & biztype = 1 & contenttype = 1. Get signature
4. Use http2 0, and is accessed by get https://vod.study.163.com/eds/api/v1/vod/video/videoId=videoId&signature=signature&clientType=1 Get the videoUrl, which is a m3u8 download address. Delete the content behind the question mark and directly access it to download it
5. Splice last script
Final function code:
import os import re import httpx import time import requests import aiohttp import asyncio import aiofiles obj = re.compile(r".*?NTESSTUDYSI=(?P<csrfkey>.*?);") obj2 = re.compile(r".*?'units': \[{'id':(?P<id>.*?),") obj3 = re.compile(r".*?'contentType': 1, 'contentId':(?P<bizld>.*?),") obj4 = re.compile('.*?"signature":"(.*?)",') obj5 = re.compile('.*?"videoUrl":"(?P<m3u8>.*?)\?ak') obj6 =re.compile('.*?"name":"(.*?)",') def init(): if not os.path.exists("./temp_data"): os.mkdir("./temp_data") if not os.path.exists("./cookie.txt"): cookie = str(input("Not detected cookie,Please enter cookie>")) with open("./cookie.txt", "w") as f: f.write(f"{cookie}") with open("cookie.txt", "r") as f: cookie = f.read() return cookie def get_video_id(csrfkey): tid = str(input("Enter the name of the course tid>")) data = {"termId": f"{tid}"} client = httpx.Client(http2=True) resp = client.post(f"https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey={csrfkey}",headers=header, data=data) resp.close() json = resp.json() shu_ju = str(json["result"]["mocTermDto"]["chapters"]) bizld = str(obj2.findall(shu_ju)).replace(" ","").replace("[","").replace("]","").replace("'","").split(",") video_id = str(obj3.findall(shu_ju)).replace("' None', ","").replace(" ","").replace("'","").replace("[","").replace("]","").split(",") print("obtain bzid and video_id") return bizld,video_id def get_signature(bizlds,csrfkey): signatures=[] client = httpx.Client(http2=True) for bizld in bizlds: data = {"bizId":f"{bizld}","bizType":"1","contentType":"1"} resp=client.post(f"https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey={csrfkey}",headers=header,data=data) resp.close() signatures = signatures+obj4.findall(resp.text) print("obtain signatures") return signatures def get_m3u8_url(video_ids,signatures): m3u8_urls = [] merge_name = [] client = httpx.Client(http2=True) for video_id,signature in zip(video_ids,signatures): resp = client.get(f"https://vod.study.163.com/eds/api/v1/vod/video?videoId={video_id}&signature={signature}&clientType=1",headers=header) resp.close() time.sleep(2) merge_name.append(str(obj6.findall(resp.text)).replace("[", "").replace("]", "").replace("'", "")) m3u8_url = obj5.findall(resp.text)[0] m3u8_urls.append(m3u8_url) print("Here are the merged file names:",merge_name) return m3u8_urls,merge_name async def download_ts(file_name,download_url,session): async with session.get(download_url,headers=header) as resp: async with aiofiles.open(f"temp_data/{file_name}",mode="wb") as f: await f.write(await resp.content.read()) async def starter(name,m3u8_url): tasks=[] async with aiohttp.ClientSession() as session: #https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144b60bd5f16c4426b08ef_sd0.ts url = str(m3u8_url).rsplit("/",1)[0] with open(f"temp_data/{name}.txt", "r") as f: for line in f: if line.startswith("#"): continue else: line = line.strip() file_name = line # I have to download it ts file name download_url = url + "/" + line print("The download link is:",download_url) task = download_ts(file_name, download_url, session) tasks.append(task) await asyncio.wait(tasks) # Wait for the end of task execution print("File download complete") def m3u8_files_download(url,name): #download m3u8 file resp = requests.get(url) with open(f"temp_data/{name}.txt",mode="wb") as f: f.write(resp.content) resp.close() def verification(name): files=[] with open(f"temp_data/{name}.txt","r") as f: for line in f: if line.startswith("#"): continue else: line=line.strip() if os.path.exists(f"temp_data/{line}"): continue else: files.append(line) print("The following files are missing, please check manually:",files) def merge_ts(file_name,merge_name): new_name = str(merge_name) with open(f"./{new_name}.mp4", "ab+") as f: with open(f"temp_data/{file_name}.txt","r") as f2: for line in f2: if line.startswith("#"): continue else: line = line.strip().split("/")[-1].strip() ts_name = line try: with open(f"temp_data/{ts_name}","rb") as f3: f.write(f3.read()) except: continue def m3u8_main(m3u8_urls,merge_names): print("obtain m3u8 Link to start the download task") for url,merge_name in zip(m3u8_urls,merge_names): name = url.rsplit("/")[-1] m3u8_files_download(url, name) # download m3u8 file asyncio.run(starter(name,url)) print("Verify file integrity") verification(name) merge_ts(name,merge_name) if __name__=="__main__": cookie = init() header = {"cookie": f"{cookie}"} csrfkey = obj.findall(cookie)[0] print("obtain csrfkey") bizid,video_id= get_video_id(csrfkey) signatures = get_signature(bizid,csrfkey) m3u8_urls,merge_name = get_m3u8_url(video_id,signatures) m3u8_main(m3u8_urls,merge_name)