Dictionaries
Sequences are indexed by consecutive integers. Unlike this, dictionaries are indexed by "Keywords". Keywords can be of any immutable type, usually strings or numbers. Dictionary is the only mapping type in Python. String, tuple and list belong to sequence type.
How to judge whether a data type is variable? There are two ways:
1. Use the id(X) function to perform some operation on X. compare the IDS before and after the operation. If they are different, then x is immutable. If they are the same, then x is mutable.
i=1 print(id(i)) i=i+2 print(id(i))
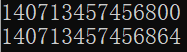
The id of the integer i after plus 2 is not the same as before, so the integer is a data type that cannot be changed.
l=[1,2] print(id(l)) l.append('abc') print(id(l))
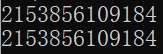
The id of list l after "Python" is attached is the same as before, so the list is changeable.
2. With hash(X), as long as no error is reported, it is proved that X can be hashed, that is, immutable, and vice versa.
print(hash(3)) print(hash('Python')) print(hash((1,2,'abc'))) print(hash([1,2,'abc']))
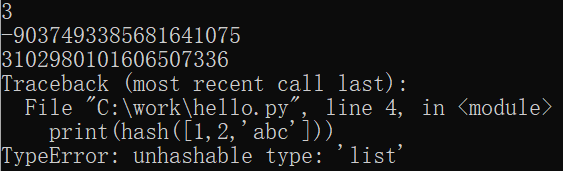
It can be seen from the running results that hash can be used for integers, strings and tuples, and no error will be reported, while hash can be used for lists. It can be seen that integers, strings and tuples are immutable data types, while lists are variable.
Dictionary definition syntax
{element 1, element 2,..., element n}Be careful:
1. Each element is a key value pair -- key: value
2. The key points are braces' {} ', commas',' and colons: '
3. Braces bind all elements together, commas separate each key value pair one by one, and colons separate key and value
Creating and accessing Dictionaries
A dictionary is an unordered set of key value pairs. Keys must be different from each other in the same dictionary.
dict={'Monday':'Monday','Tuesday':'Tuesday','Wednesday':'Wednesday'} print(dict) print(dict['Tuesday'])

Built in method of dictionary
dict.fromkeys(seq,value) is used to create a new dictionary. The key of the dictionary is the element in the sequence seq, and value is the initial value corresponding to all keys of the dictionary.
seq=('name','age','gender') dict=dict.fromkeys(seq) print(dict) dict=dict.fromkeys(seq,('Meng')) print(dict) dict=dict.fromkeys(seq,('Meng','12','M')) print(dict)

dict.keys() returns an iterative object that can be converted to a list using list().
dict={'name':'Meng','age':'18'} print(dict.keys()) print(list(dict.keys()))

dict.values() returns an iterator that can be converted to a list using list(), which is all the values in the dictionary.
dict={'name':'Meng','age':'18'} print(dict.values()) print(list(dict.values()))
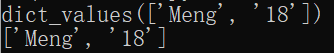
dict.items() returns an array of traversable (key, value) tuples as a list.
dict={'name':'Meng','age':'18'} print('value:',dict.items()) print(tuple(dict.items()))

dict.get(key, default=None) returns the value of the specified key, if the value is not in the dictionary, it returns the default value.
dict={'name':'Meng','age':'18'} print('name The value is:',dict.get('name')) print('gender The value is:',dict.get('gender','M'))

The key in dict in operator is used to determine whether the key exists in the dictionary. If the key returns true in the dictionary dict, otherwise it returns false. On the contrary, if the key returns false in the dictionary dict, otherwise it returns true.
dict={'name':'Meng','age':'18'} if 'name' in dict: print("key name existence") else: print("key name Non-existent") if 'sex' not in dict: print("key sex Non-existent") else: print("key sex existence")
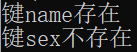
dict.clear() is used to delete all elements in the dictionary.
dict={'name':'Meng','age':'18'} print("Dictionary length:",len(dict)) dict.clear() print("Dictionary length after deletion:",len(dict))

dict.copy() returns a shallow copy of a dictionary.
dict={'name':'Meng','age':'18'} dict2=dict.copy() print(dict2)

dict.pop(key,default) deletes the value corresponding to the key given in the dictionary, and the return value is the deleted value.
The key value must be given. Otherwise, the default value is returned.
dict={'name':'Meng','age':'18'} dict.pop('name') print(dict)

del dict[key] delete the value corresponding to the key given in the dictionary.
dict={'name':'Meng','age':'18'} del dict['name'] print(dict)

dict.popitem() randomly returns and deletes a pair of keys and values in the dictionary. If the dictionary is empty but this method is called, a KeyError exception is reported.
dict={'name':'Meng','age':'18'} dict.popitem() print(dict)

dict.setdefault(key, default=None) is similar to the get() method. If the key does not exist in the dictionary, the key will be added and the value will be set to the default value.
dict={'name':'Meng','age':'18'} print("name The value of the key is:",dict.setdefault('name', None)) print("Sex The value of the key is:",dict.setdefault('Sex', None)) print("The new dictionary is", dict)

dict.update(dict2) updates the key / value pair of dict2 to dict.
dict={'name':'Meng','age':'18'} dict2={'gender':'M','age':'19'} dict.update(dict2) print("Update dictionary dict:", dict)

aggregate
Similar to dict, set is also a set of keys, but does not store value. Because the key cannot be repeated, there is no duplicate key in the set.
Collection creation
Directly enclose a bunch of elements with curly brackets {element 1, element 2,... , element n}, duplicate elements are automatically filtered in the set.
set={'cat','dog','rabbit'} print(set)

Use the set(value) factory function to convert a list or tuple into a set.
a = set('rabbit') print(a) b = set(('rabbit','cat','dog','rabbit')) print(b) c = set(['rabbit','cat','dog','rabbit']) print(c)
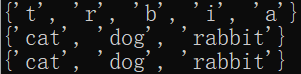
From the results, two characteristics of set are found: unordered and unique. Because set stores unordered sets, we can't access them through index, but we can judge whether an element is in the set.
Built in methods for collections
set.add(elmnt) is used to add elements to the collection. If the added elements already exist in the collection, no operation is performed.
a = {'rabbit','cat','dog'} a.add('rabbit') print(a) a.add('apple') print(a)

set.remove(item) is used to remove the specified element from the collection.
a = {'rabbit','cat','dog'} a.remove('rabbit') print(a)

set.update(set) is used to modify the current collection. You can add new elements or collections to the current collection. If the added element already exists in the collection, the element will only appear once, and repeated elements will be ignored.
a={'rabbit','cat','dog'} b={'google', 'baidu','dog'} a.update(b) print(a)

Because set is a collection of disordered and unrepeatable elements, two or more sets can do set operations in the mathematical sense. set.intersection(set1, set2... )Used to return elements contained in two or more collections, that is, intersections. set.union(set1, set2... )Returns the union of two sets, that is, the elements that contain all sets, and the repeated elements only appear once. set.difference(set) returns the difference set of the set, that is, the returned set element is contained in the first set, but not in the second set (the parameter of the method).
a={'rabbit','cat','dog'} b={'google', 'baidu','dog'} print(a & b) c = a.intersection(b) print(c) c = a.union(b) print(c) c = a.difference(b) print(c)

set.issubset(set) is used to determine whether all elements of the set are included in the specified set. If it is, it returns True; otherwise, it returns False.
a={'rabbit','cat','dog'} b={'google', 'baidu','dog','rabbit','cat'} print(a.issubset(b)) #True
set.issuperset(set) is used to determine whether all elements of the specified set are included in the original set. If it is, it returns True; otherwise, it returns False.
x = {"f", "e", "d", "c", "b"} y = {"a", "b", "c"} z = x.issuperset(y) print(z) # False
frozenset([iterable]) returns a frozen collection. After freezing, the collection cannot add or delete any elements.
a={'rabbit','cat','dog'} b=frozenset(a) print(a)
