1, read_sql and to_sql function
1.1 read_sql function
- Reading data is generally read from the database, so in read_ Fill in the corresponding SQL statement in the SQL () function to read the data we want
- pd.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
1) sql: SQL command string;
2) con: the Engine connecting to the SQL database is generally established with modules such as SQLAlchemy or PyMysql;
3)index_col: select a column as the Index;
4)coerce_float: read the string in digital form directly in float type;
5)parse_dates: convert a column of date type string to datatime type data. You can directly provide the column name to be converted and convert it in the default date form, or you can also provide the column name in dictionary form and the format of conversion date;
#Use pymysql module to establish database connection and read the data in the database import pandas as pd from pymysql import * conn=connect(host='localhost',port=3306, database='database_name', user='root', password='123456',charset='utf8') #Host is the IP address of the host connecting to the database, the default port of mysql is 3306, database is the name of the database, user and password are the account and password connecting to the database respectively, and charset is the character code of the database #Write an SQL statement and use read_sql() function to read sql_cmd='SELECT * FROM table_name' df=pd.read_sql(sql_cmd, conn) df.head()
#Test the parameter parse_ The role of dates sql_cmd_2 = "SELECT * FROM test_date" df_1 = pd.read_sql(sql_cmd_2, conn) df_1.head() """ output number date_columns 0 1 2021-11-11 1 2 2021-10-01 2 3 2021-11-10 """ df_1.info() """ <class 'pandas.core.frame.DataFrame'> RangeIndex: 3 entries, 0 to 2 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 number 3 non-null int64 1 date_columns 3 non-null object dtypes: int64(1), object(1) memory usage: 176.0+ bytes """ #Normally, by default, date_columns is also treated as String data. If we pass parse_ The dates parameter applies date resolution to the column
df_2 = pd.read_sql(sql_cmd_2, conn, parse_dates="date_columns")
df_2.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 number 3 non-null int64
1 date_columns 3 non-null datetime64[ns]
dtypes: datetime64[ns](1), int64(1)
memory usage: 176.0 bytes
"""
#It is converted into the corresponding date format. Of course, we can also use another format mentioned above
parse_dates={"date_column": {"format": "%d/%m/%y"}}
df_3 = pd.read_sql(sql_cmd_2, conn, parse_dates=parse_dates)
df_3.info()
1.2 to_sql function
- DataFrame.to_sql(name,con,schema=None,if_exists='fail',index=True, index_label=None,chunksize=None,dtype=None,method=None)
1) Name: is the name of the table in the input database;
2) con: the way to link with the database. The engine type of sqlalchemy is recommended;
3) schema: the engine of the corresponding database. If it is not set, the default engine of the database will be used, such as innodb engine in mysql;
4)if_exists: when the data table already exists in the database, the operations on the data table include replace, append and append. If fail, ValueError will be prompted when the table exists;
5) Index: process the index of DataFrame. When it is True, the index will also be written into the data table as data;
6)index_label: when the previous parameter index is True, set the column name of index when writing the data table;
7) Chunksize: set an integer, such as 20000, the number of data lines when writing data at one time. When the amount of data is large, it needs to be set, otherwise the link timeout and writing failure will occur;
8) dtype: when writing the data table, you can set the name of the column (the keys should be the column names and the values should be the sqlchemy types or strings for the SQLite3 legacy mode). When setting, the type should be consistent with the type of sqlalchemy When not set, to_ When SQL generates a table, it will automatically be compatible with the largest type; - to_ In the SQL () parameter, except name and con are required, the optional parameter index is recommended to be False, and dtype is not recommended.
- to_ The SQL method is created when the data table does not exist. If it exists, it is created according to if_ replace, append and fail set by the exists parameter correspond to replacement, append and failure respectively.
#sqlalchemy. create_ The engine() function creates engine in two ways:
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://user:passwd@127.0.0.1/database?charset=utf8')
engine = create_engine('mysql+mysqlconnector:// user:passwd@127.0.0.1/database?charset=utf8')
#user: passwd@127.0.0.1 /Database -- > format: user name: password @ server address / database name
from sqlalchemy import create_engine
DB_STRING = 'mysql+mysqlconnector://user:passwd@127.0.0.1/database?charset=utf8'
engine = create_engine(DB_STRING)
data.to_sql('Table name',con = engine)
#This is used in mysql5 Before version 7, there was no problem, but after version 8, mysql8 changed the password encryption method, and an error will be prompted when using this method.
#In use to_ When writing SQL to versions above mysql8, you need to use mysqldb as the driver
#When importing pymysql, you need pymysql install_ as_ Only mysqldb() can be used
import pymysql
pymysql.install_as_MySQLdb()
DB_STRING = 'mysql+mysqldb://user:passwd@127.0.0.1/db_name?charset=utf8'
engine = create_engine(DB_STRING)
data.to_sql('Table name',con = engine)
#Parameter dtype usage
#DATE,CHAR,VARCHAR... You can go to the official document of sqlalchemy to view all sql data types: [‘TypeEngine’, ‘TypeDecorator’, ‘UserDefinedType’, ‘INT’, ‘CHAR’, ‘VARCHAR’, ‘NCHAR’, ‘NVARCHAR’, ‘TEXT’, ‘Text’, ‘FLOAT’, ‘NUMERIC’, ‘REAL’, ‘DECIMAL’, ‘TIMESTAMP’, ‘DATETIME’, ‘CLOB’, ‘BLOB’, ‘BINARY’, ‘VARBINARY’, ‘BOOLEAN’, ‘BIGINT’, ‘SMALLINT’, ‘INTE GER’, ‘DATE’, ‘TIME’, ‘String’, ‘Integer’, ‘SmallInteger’, ‘BigInteger’, ‘Numeric’, ‘Float’, ‘DateTime’, ‘Date’, ‘Time’, ‘LargeBinary’, ‘Binary’, ‘Boolean’, ‘Unicode’, ‘Concatenable’, ‘UnicodeText’, ‘PickleType’, ‘Interval’, ‘Enum’, ‘Indexable’, ‘ARRAY’, 'JSON'] you can select the appropriate type to correspond to the database
from sqlalchemy.types import DATE,CHAR,VARCHAR
DTYPES = {'col_1 Field name' : DATE, 'col_2':CHAR(4),'col_3':VARCHAR(10)}
df.to_sql('Table name',con = engine,dtype = DTYPES)
#The data will be written into the df of the data table. dtype specifies the data type field corresponding to the column name
#Execute the SQL statement to view the written database data
engine.execute("SELECT * FROM table_name").fetchall()
2, from_dict function and to_dict function
2.1 from_dict function
a_dict = {
'school': 'Tsinghua University',
'geographical position': 'Beijing',
'ranking': 1
}
df = pd.json_normalize(a_dict) #Convert data in dictionary format to DataFrame
df

df = pd.DataFrame(a_dict, index = [0])#Convert data in dictionary format to DataFrame df
df = pd.DataFrame.from_dict(a_dict,orient='index')#Convert data in dictionary format to DataFrame df
data = {'col_1': [1, 2, 3, 4],
'col_2': ['A', 'B', 'C', 'D']}
df = pd.DataFrame.from_dict(data, orient='columns')#Convert data in dictionary format to DataFrame
df
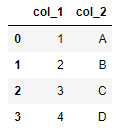
df = pd.DataFrame.from_dict(data, orient='index')#Convert data in dictionary format to DataFrame df
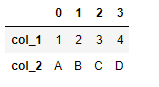
2.2 to_dict function
- to_dict(orient): the values of orient include dict (default), list, split, records and index
df = pd.DataFrame({'shape': ['square', 'circle', 'triangle'],
'degrees': [360, 360, 180],
'sides': [4, 5, 3]})
df
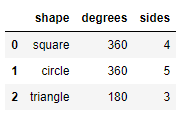
- Output as dict: the value of orient is' dict '
#Output as dict
dict_out=df.to_dict(orient='dict')
dict_out
#output
"""
{'shape': {0: 'square', 1: 'circle', 2: 'triangle'},
'degrees': {0: 360, 1: 360, 2: 180},
'sides': {0: 4, 1: 5, 2: 3}}
"""
#read
df=pd.DataFrame.from_dict(dict_out)
df
#result
"""
shape degrees sides
0 square 360 4
1 circle 360 5
2 triangle 180 3
"""
- The output is dict: orient, and the value is' split '
#Output as dict
dict_out=df.to_dict(orient='split')
dict_out
#output
"""
{'index': [0, 1, 2],
'columns': ['shape', 'degrees', 'sides'],
'data': [['square', 360, 4], ['circle', 360, 5], ['triangle', 180, 3]]}
"""
#read
df=pd.DataFrame.from_dict(dict_out)
df
#result
"""
index columns data
0 0 shape [square, 360, 4]
1 1 degrees [circle, 360, 5]
2 2 sides [triangle, 180, 3]
"""
- The output is dict: orient, and the value is' list '
#Output as dict
dict_out=df.to_dict(orient='list')
dict_out
#output
"""
{'shape': ['square', 'circle', 'triangle'],
'degrees': [360, 360, 180],
'sides': [4, 5, 3]}
"""
#read
df=pd.DataFrame.from_dict(dict_out)
df
#result
"""
shape degrees sides
0 square 360 4
1 circle 360 5
2 triangle 180 3
"""
- The output is dict: orient, and the value is' index '
#Output as dict
dict_out=df.to_dict(orient='index')
dict_out
#output
"""
{0: {'index': 0, 'columns': 'shape', 'data': ['square', 360, 4]},
1: {'index': 1, 'columns': 'degrees', 'data': ['circle', 360, 5]},
2: {'index': 2, 'columns': 'sides', 'data': ['triangle', 180, 3]}}
"""
- The output is dict: orient, and the value is' records'
#Output as dict
dict_out=df.to_dict(orient='records')
dict_out
#output
"""
[{0: 0, 1: 1, 2: 2},
{0: 'shape', 1: 'degrees', 2: 'sides'},
{0: ['square', 360, 4], 1: ['circle', 360, 5], 2: ['triangle', 180, 3]}]
"""
3, read_json function and to_json function
3.1 read_json function
-
pandas.read_json()
1) Parameter orient: the format of the corresponding JSON string
2) split: the format is similar to: {index: [index], columns: [columns], data: [values]}
3) records: format is similar to: [{column: value},..., {column: value}]
4) Index: the format is similar to: {index: {column: value}}
5) columns: the format is similar to: {column: {index: value}}
6) values: array -
split format: the format is similar to: {index: [index], columns: [columns], data: [values]}
import pandas as pd
#split: the format is similar to: {index: [index], columns: [columns], data: [values]}
#For example, our JSON string is so long
a='{"index":[1,2,3],"columns":["a","b"],"data":[[1,3],[2,8],[3,9]]}'
df = pd.read_json(a, orient='split')
df
#output
"""
a b
1 1 3
2 2 8
3 3 9
"""
- records format: similar to: [{column: value},..., {column: value}]
import pandas as pd
#For example, our JSON string is so long
#records: format is similar to: [{column: value},..., {column: value}]
#For example, our JSON string is so long
a = '[{"name":"Tom","age":"18"},{"name":"Amy","age":"20"},{"name":"John","age":"17"}]'
df_1 = pd.read_json(a, orient='records')
df_1
#output
"""
name age
0 Tom 18
1 Amy 20
2 John 17
"""
- Index format: similar to: {index: {column: value}}
import pandas as pd
#For example, our JSON string is so long
#index: {index: {column: value}}
#For example, our JSON string is so long
a = '{"index_1":{"name":"John","age":20},"index_2":{"name":"Tom","age":30},"index_3":{"name":"Jason","age":50}}'
df_1 = pd.read_json(a, orient='index')
df_1
#output
"""
name age
index_1 John 20
index_2 Tom 30
index_3 Jason 50
"""
- columns format: the format is similar to: {column: {index: value}}
import pandas as pd
#columns: the format is similar to: {column: {index: value}}
a = '{"index_1":{"name":"John","age":20},"index_2":{"name":"Tom","age":30},"index_3":{"name":"Jason","age":50}}'
df_1 = pd.read_json(a, orient='columns')
df_1
#output
"""
index_1 index_2 index_3
name John Tom Jason
age 20 30 50
"""
- values array
import pandas as pd #values: array #For example, our JSON string is so long v='[["a",1],["b",2],["c", 3]]' df_1 = pd.read_json(v, orient="values") df_1 #output """ 0 1 0 a 1 1 b 2 2 c 3 """
3.2 to_json function
- To output the DataFrame data object as a JSON string, you can use to_json() method, in which the orient parameter can output strings in different formats, and the usage is roughly the same as that above
4, read_html functions and to_html function
4.1 read_html function
- Sometimes we need to grab a table information on the web page. Compared with using Xpath or beautiful soup, we can use the encapsulated function read in pandas_ HTML to get it quickly. For example, we use it to grab part of the content on the novice tutorial Python website
#!pip3 install lxml #Use read for the first time_ HTML, you need to install the lxml package
from lxml import *
url = "https://www.runoob.com/python/python-exceptions.html"
dfs = pd.read_html(url, header=None, encoding='utf-8')#The return is a list
df=dfs[0]
df.head()
#output
"""
Exception name describe
0 NaN NaN
1 BaseException Base class for all exceptions
2 SystemExit Interpreter requests exit
3 KeyboardInterrupt User interrupt execution(Usually input^C)
4 Exception Base class for general errors
"""
4.2 to_html function
import numpy as np
df = pd.DataFrame(np.random.randn(3, 3),columns=['A','B','C'])
df.to_html("test_1.html",index=False)
dfs = pd.read_html("test_1.html")
dfs[0]
#output
"""
A B C
0 -0.348165 -0.572741 -0.190966
1 0.700785 -0.848750 -1.853054
2 0.941161 -0.944569 0.749450
"""
5, read_csv function and to_csv function
5.1 read_csv function
#Parameter filepath_or_buffer: the path of data input, which can be URL
#sep: the separator specified when reading csv files. The default is comma
#index_col: after reading the file, we can specify a column as the index of the DataFrame
pd.read_csv(filepath_or_buffer='data.csv',index_col=0)
#output
"""
num1 num2 num3 num4
0 1 2 3 4
1 6 12 7 9
2 11 13 15 18
3 12 10 16 18
"""
#index_col in addition to specifying a single column, we can also specify multiple columns
pd.read_csv(filepath_or_buffer='data.csv',index_col=['num1','num2'])
#output
Unnamed: 0 num3 num4
num1 num2
1 2 0 3 4
6 12 1 7 9
11 13 2 15 18
12 10 3 16 18
#usecols: this parameter can be used if there are many columns in the dataset, and we don't want all the columns, but only the specified columns
#pd.read_csv('data.csv', usecols = ["column name 1", "column name 2",...])
pd.read_csv('data.csv', usecols=["num1", "num2"])
#output
num1 num2
0 1 2
1 6 12
2 11 13
3 12 10
#usecols in addition to specifying the column name, you can also select the desired column by index. The example code is as follows
df = pd.read_csv("data.csv", usecols = [1, 2])
df
#output
num1 num2
0 1 2
1 6 12
2 11 13
3 12 10
#The usecols parameter can receive a function and pass the column name as a parameter to the function. If the condition is satisfied, the column is selected, otherwise the column is not selected.
pd.read_csv("data.csv", usecols = lambda x:len(x)<5)
#output
num1 num2 num3 num4
0 1 2 3 4
1 6 12 7 9
2 11 13 15 18
3 12 10 16 18
#Prefix: when the imported data does not have a header, it can be used to prefix the column name
pd.read_csv("data.csv", prefix="test_", header = None)
#output
test_0 test_1 test_2 test_3 test_4
0 NaN num1 num2 num3 num4
1 0.0 1 2 3 4
2 1.0 6 12 7 9
3 2.0 11 13 15 18
4 3.0 12 10 16 18
#Skirows: which rows are filtered out and the index of the rows filled in the parameters
pd.read_csv("data.csv", skiprows=[0, 1])
#The above code filters out the data of the first two lines and directly outputs the data of the third and fourth lines. You can see that the data of the second line is taken as the header
#output
1 6 12 7 9
0 2 11 13 15 18
1 3 12 10 16 18
#nrows: this parameter sets the number of file lines read in at one time, which is very useful for reading large files. For example, a PC with 16G memory cannot hold hundreds of G large files
pd.read_csv("data.csv", nrows=2)
#output
Unnamed:0 num1 num2 num3 num4
0 0 1 2 3 4
1 1 6 12 7 9
5.2 to_csv function
5.2.1 save csv format
#This method is mainly used to write DataFrame into csv file. The example code is as follows
df=pd.read_csv("data.csv", usecols = lambda x:len(x)<5)
df.to_csv("file name.csv", index = False)
5.2.2 save in zip format
#We can also output to a zip file format
df = pd.read_csv("data.csv")
compression_opts = dict(method='zip',
archive_name='output.csv')
df.to_csv('output.zip', index=False,
compression=compression_opts)
6, read_excel functions and to_excel function
6.1 read_excel function
#! pip install xlrd #Execute read for the first time_ When using Excel, you need to install xlrd package
#!pip install openpyxl #Execute read for the first time_ When using Excel, you need to install openpyxl package
df = pd.read_excel("data.xlsx",engine='openpyxl') #Because of the version problem of xlrd package, you must add engine='openpyxl '
df
#output
Unnamed: 0 num1 num2 num3 num4
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18
#dtype: this parameter can set the data type of a specified column
df = pd.read_excel("data.xlsx",engine='openpyxl',dtype={'Unnamed: 0': str, 'num1': float})
print(df.info())
df
#output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 4 non-null object
1 num1 4 non-null float64
2 num2 4 non-null int64
3 num3 4 non-null int64
4 num4 4 non-null int64
dtypes: float64(1), int64(3), object(1)
memory usage: 288.0+ bytes
None
Unnamed: 0 num1 num2 num3 num4
0 0 1.0 2 3 4
1 1 6.0 12 7 9
2 2 11.0 13 15 18
3 3 12.0 10 16 18
#heet_name: set which sheet in excel to read
df = pd.read_excel("data.xlsx",engine='openpyxl', sheet_name="Sheet2")
df
#output
Unnamed: 0 num5 num6 num7 num8
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18
#Of course, if we want to read the data in multiple sheets at one time, it is also possible. The last returned data is returned in the form of dict
df = pd.read_excel("data.xlsx",engine='openpyxl',sheet_name=["Sheet1", "Sheet2"])
df
#output
{'Sheet1': Unnamed: 0 num1 num2 num3 num4
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18,
'Sheet2': Unnamed: 0 num5 num6 num7 num8
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18}
#For example, if we only want the data of Sheet1, we can use the get function
df.get("Sheet1")
#output
Unnamed: 0 num1 num2 num3 num4
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18
6.2 to_excel function
#In addition to writing DataFrame objects into Excel tables, the ExcelWriter() method also plays a similar role
df1 = pd.DataFrame([['A', 'B'], ['C', 'D']],
index=['Row 1', 'Row 2'],
columns=['Col 1', 'Col 2'])
df1.to_excel("output1.xlsx")
#Specifies the name of the Sheet
df1.to_excel("output1.xlsx", sheet_name='Sheet_Name_1_1_1')
#Output multiple DataFrame datasets to different sheets in one Excel
df2 = df1.copy()
with pd.ExcelWriter('output2.xlsx') as writer:
df1.to_excel(writer, sheet_name='Sheet_name_1_1_1')
df2.to_excel(writer, sheet_name='Sheet_name_2_2_2')
#Add another Sheet based on the existing Sheet
df3 = df1.copy()
with pd.ExcelWriter('output2.xlsx', mode="a", engine="openpyxl") as writer:
df3.to_excel(writer, sheet_name='Sheet_name_3_3_3')
#There are two mode parameters: W and A. w refers to overwrite writing, which will overwrite the original Sheet; a refers to append writing, which will add a Sheet again
#It can be generated to Excel file and compressed
import zipfile
with zipfile.ZipFile("output_excel.zip", "w") as zf:
with zf.open("output_excel.xlsx", "w") as buffer:
with pd.ExcelWriter(buffer) as writer:
df1.to_excel(writer)
#Data in date format or date time format can also be processed accordingly
from datetime import date, datetime
df = pd.DataFrame(
[
[date(2019, 1, 10), date(2021, 11, 24)],
[datetime(2019, 1, 10, 23, 33, 4), datetime(2021, 10, 20, 13, 5, 13)],
],
index=["Date", "Datetime"],
columns=["X", "Y"])
df
#output
X Y
Date 2019-01-10 00:00:00 2021-11-24 00:00:00
Datetime 2019-01-10 23:33:04 2021-10-20 13:05:13
#Store and write according to date format
with pd.ExcelWriter(
"output_excel_date.xlsx",
date_format="YYYY-MM-DD",
datetime_format="YYYY-MM-DD HH:MM:SS"
) as writer:
df.to_excel(writer)
7, read_table function
- For txt files, you can use read_csv() method, or read_table() method, where the parameters and read_ The parameters in CSV () are roughly the same
#Read data separated by spaces
import pandas as pd
df = pd.read_table('sentences.txt',header=None, encoding='utf8') #When enconding='utf8 'is not added, Chinese will display garbled code
df
#output
0
0 I love you China!
1 China is great and the motherland is safe!
2 People's happiness!
8, read_pickle function and to_pickle function
- The Pickle module in Python implements the binary sequence and deserialization of a python object structure. The serialization process is to convert the text information into a binary data stream and save the data type at the same time. For example, in the process of data processing, if you suddenly have something to leave, you can directly serialize the data to the local. At this time, the type of data in processing is the same as that saved locally. After deserialization, it is also the data type, rather than processing from scratch.
8.1 read_pickle function
from datetime import date, datetime
df = pd.DataFrame(
[
[date(2019, 1, 10), date(2021, 11, 24)],
[datetime(2019, 1, 10, 23, 33, 4), datetime(2021, 10, 20, 13, 5, 13)],
],
index=["Date", "Datetime"],
columns=["X", "Y"])
df.to_pickle('test.pkl')
df
#result
X Y
Date 2019-01-10 00:00:00 2021-11-24 00:00:00
Datetime 2019-01-10 23:33:04 2021-10-20 13:05:13
8.2 to_pickle function
df2 = pd.read_pickle("test.pkl")
df2
#result
X Y
Date 2019-01-10 00:00:00 2021-11-24 00:00:00
Datetime 2019-01-10 23:33:04 2021-10-20 13:05:13
9, read_clipboard function and to_clipboard function
9.1 read_clipboard function
- Sometimes it is inconvenient to obtain data. We can copy the data in any place of the computer, and then use read in Pandas_ The clipboard () method is used to read the data copied successfully
df=pd.read_clipboard() df #result X Y Date 2019-01-10 00:00:00 2021-11-24 00:00:00 Datetime 2019-01-10 23:33:04 2021-10-20 13:05:13
to_clipboard function
- If there is copy, there will be paste. We can output the DataFrame dataset to the clipboard
df.to_clipboard()