3.1 documents and folders
① Review file access mode

We have also talked about the things returned by with... as before, which can make the returned things ineffective outside the with... as statement. That is, it only takes effect within its own scope. It is equivalent to automatic destruction. The cycle is relatively short. So we can use with... as for file operation, so we don't need to close the file.
② pandas can also read Notepad files
pandas.read_csv('path of file ') its file stores table data in plain text. We will read it in separate lines with index number.
csv data object to_csv('storage path ', index=False) index=False is to write a file without a number for storage.
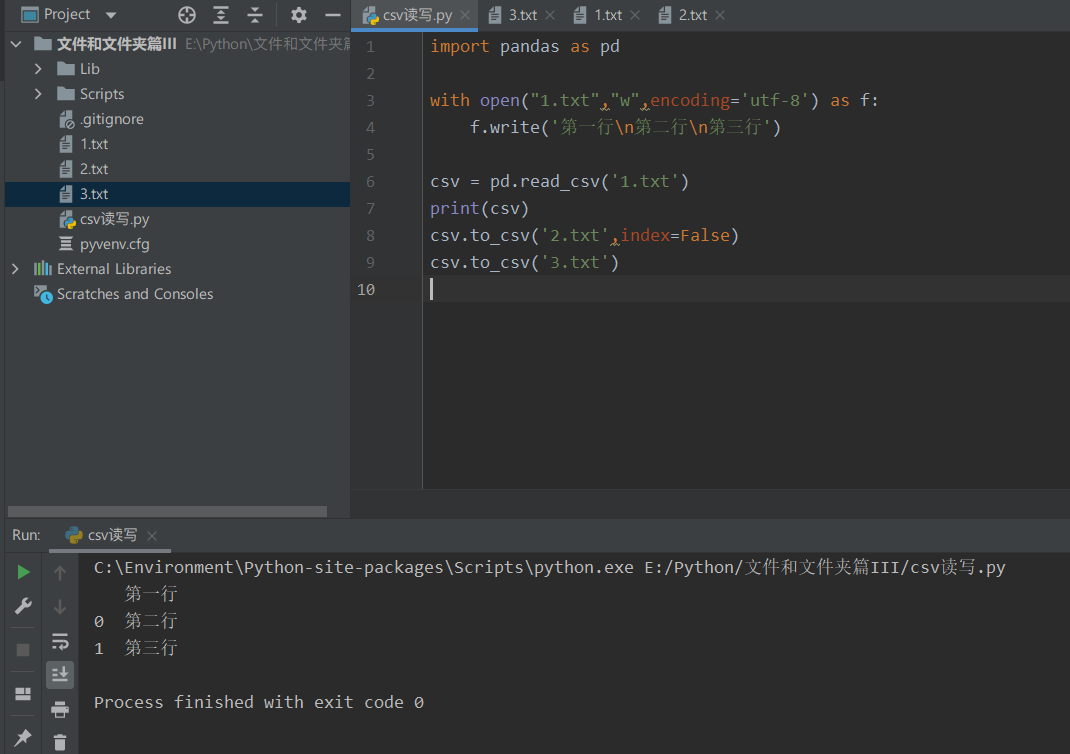
import pandas as pd
with open("1.txt","w",encoding='utf-8') as f:
f.write('first line\n Second line\n Third line')
csv = pd.read_csv('1.txt')
print(csv)
csv.to_csv('2.txt',index=False)
csv.to_csv('3.txt')
③ Concept of temporary file and temporary file module < recommended for crawler >
Python file reading and writing is an adaptive temporary file!!! When you perform partial read and write operations on a large amount of data, temporary files will be created. The temporary file will not block the buffer, but also improve the efficiency.
Therefore, we always see that when it comes to file reading and writing, it is divided into how many bytes and how many bytes to read and write step by step. Basically not written all at once.. Read this situation at once ~ ~ unless you are a novice..
In addition, we can also manually create temporary files and temporary folders.
TemporaryFile('Access mode ') creates a temporary file and operates on it accordingly
TemporaryDirectory() creates a temporary folder
from tempfile import TemporaryFile
from tempfile import TemporaryDirectory
with TemporaryDirectory() as Temporary folder:
print(f"Temporary folder path:{Temporary folder}")
with TemporaryFile('w') as Temporary documents:
print(f"Temporary file path:{Temporary documents.name}")
print(f"Temporary file object:{Temporary documents}")

3.2.1 Python decompress ZIP file [zipfile module]
① ZipFile('zip file path ',' access mode ')
Zip object namelist() reads the names of the files in the zip package, and it returns a list.
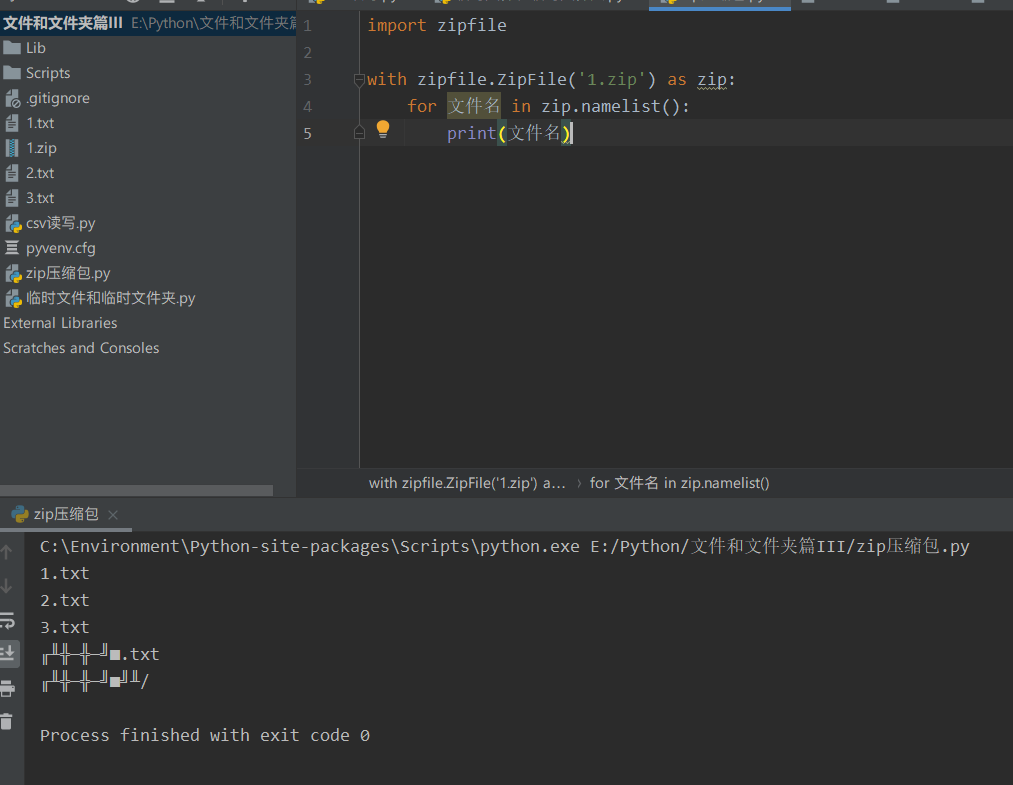
import zipfile
with zipfile.ZipFile('1.zip') as zip:
for file name in zip.namelist():
print(file name)
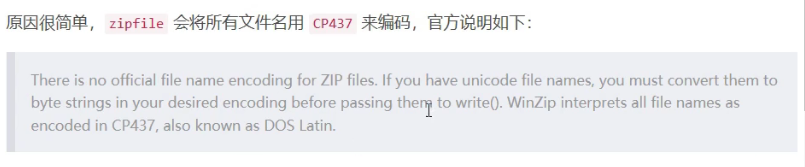
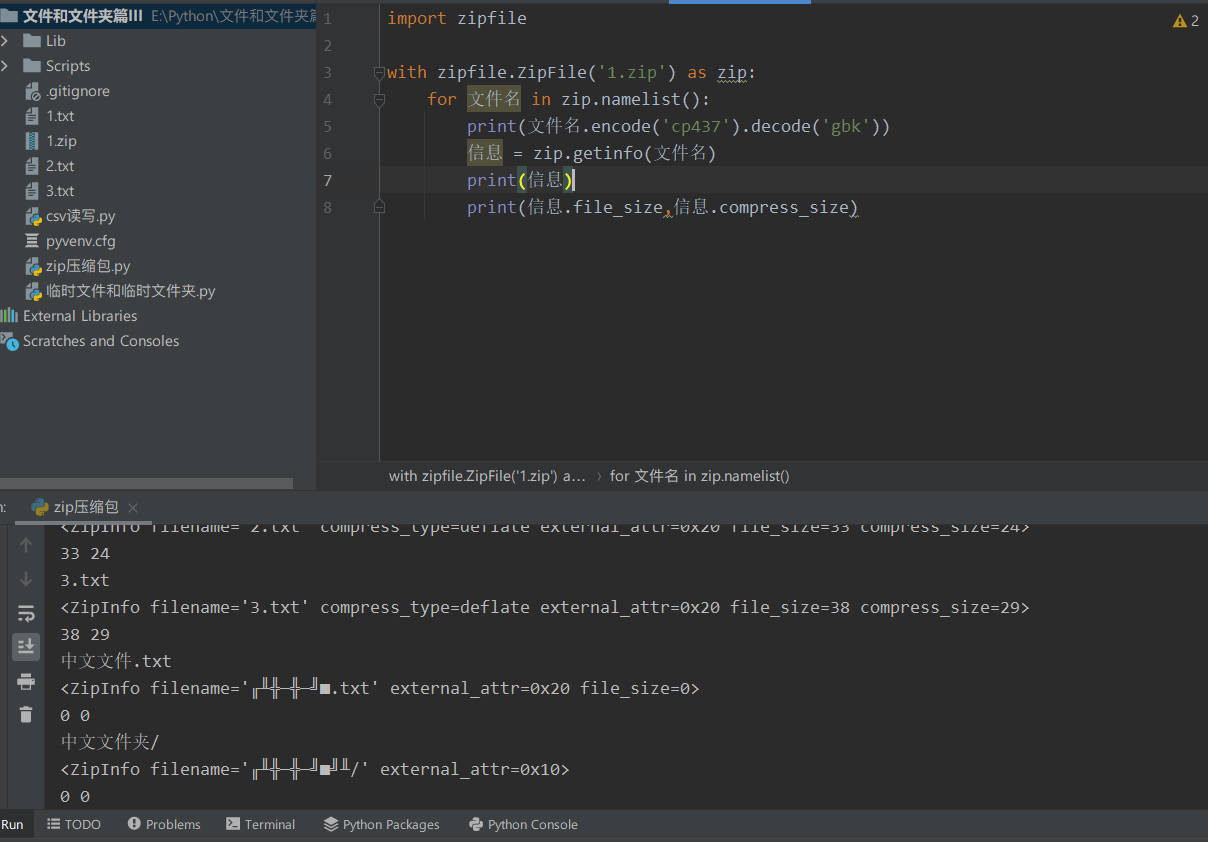
It is normal for Chinese to be garbled. Because the zipfile encodes the file name in CP437, we need to encode it in CP437 first, and then because the encoding is in Chinese. Therefore, gbk decoding is enough.

② View information for each file < file_ Size size before compression, compress_size compressed size >
zip object Getinfo (file name) obtains the information of relevant files from the compressed package
import zipfile
with zipfile.ZipFile('1.zip') as zip:
for file name in zip.namelist():
print(file name.encode('cp437').decode('gbk'))
information = zip.getinfo(file name)
print(information)
print(information.file_size,information.compress_size)
③ Decompression < in read mode, we can decompress >
zip. Extract (file name, storage path and location) decompresses a single file to a specified location
zip.extractall('stored path location ') decompresses all files to the specified location
import zipfile
import os
from pathlib import Path
if not os.path.isdir('folder'):
os.mkdir('folder')
with zipfile.ZipFile('1.zip') as zip:
for file name in zip.namelist():
information = zip.getinfo(file name)
Unzipped file = Path(zip.extract(file name,'folder'))
print(Unzipped file.name)
Unzipped file.rename('folder\\'+file name.encode('cp437').decode('gbk'))
When decompressing, we should also note that if there is Chinese, we will rename the garbled code. You can use the pathlib module or directly use OS Rename() personal recommendation: directly use OS rename()
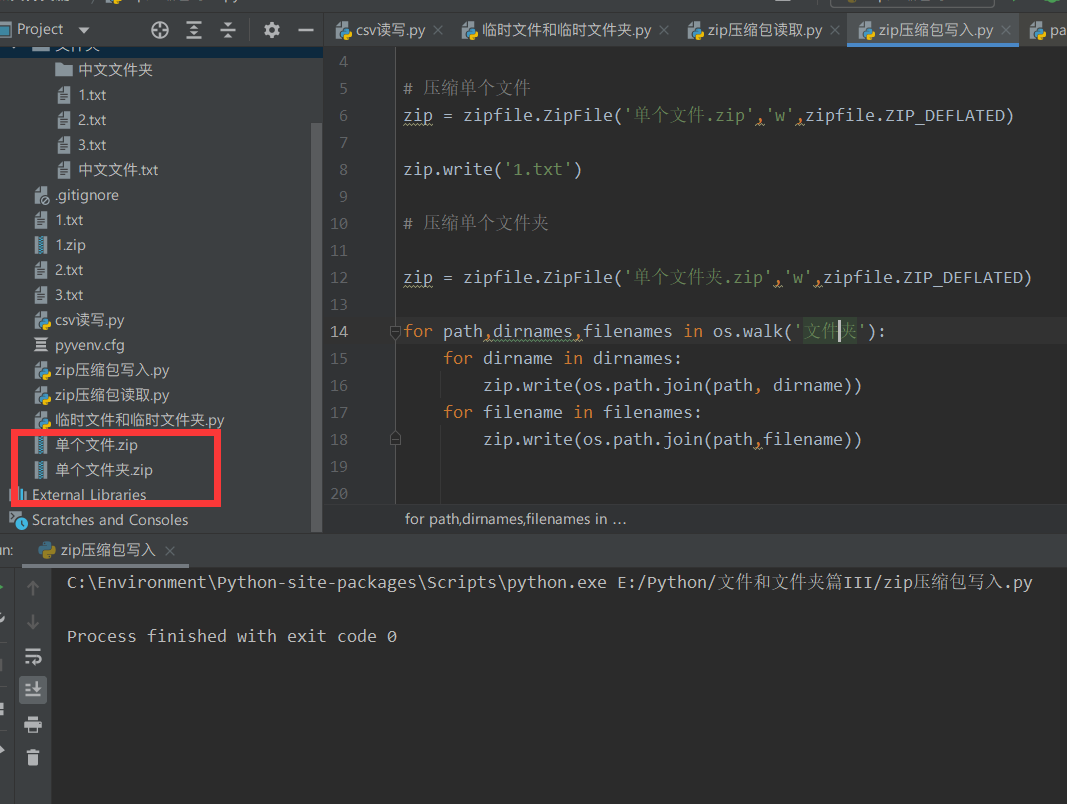
④ A single file and a single folder are compressed to a specified compressed package.
import os
import zipfile
import os
# Compress a single file
zip = zipfile.ZipFile('Single file.zip','w',zipfile.ZIP_DEFLATED)
zip.write('1.txt')
# Compress a single folder
zip = zipfile.ZipFile('Single folder.zip','w',zipfile.ZIP_DEFLATED)
for path,dirnames,filenames in os.walk('folder'):
for dirname in dirnames:
zip.write(os.path.join(path, dirname))
for filename in filenames:
zip.write(os.path.join(path,filename))
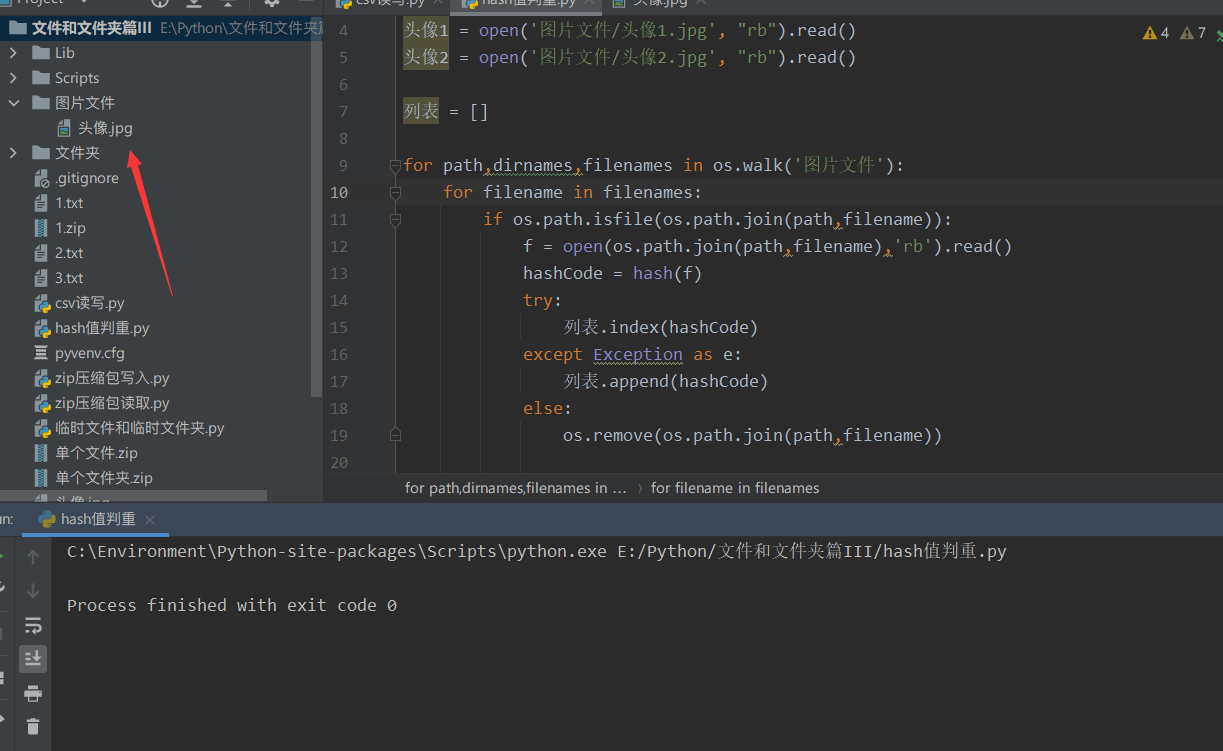
3.3.1 according to the file hash value, it is judged that the duplicate is deleted

For example, we have three duplicate files here, not just duplicate file names. But the data itself is the same! Such repetition can only be judged by the hash value.
head portrait = open('head portrait.jpg',"rb").read()
Avatar 1 = open('Avatar 1.jpg',"rb").read()
Avatar 2 = open('Avatar 2.jpg',"rb").read()
print(hash(head portrait))
print(hash(Avatar 1))
print(hash(Avatar 2))

Depending on the list to store the first hash value encountered and there is no hash value in the list, we can keep 1 and delete duplicate!
import os
head portrait = open('Picture file/head portrait.jpg', "rb").read()
Avatar 1 = open('Picture file/Avatar 1.jpg', "rb").read()
Avatar 2 = open('Picture file/Avatar 2.jpg', "rb").read()
list = []
for path,dirnames,filenames in os.walk('Picture file'):
for filename in filenames:
if os.path.isfile(os.path.join(path,filename)):
f = open(os.path.join(path,filename),'rb').read()
hashCode = hash(f)
try:
list.index(hashCode)
except Exception as e:
list.append(hashCode)
else:
os.remove(os.path.join(path,filename))