In today's computerized (or paperless) office environment, some materials often need to be transferred between different office documents due to work needs. If you need to present a briefing (. ppt), you may need to copy some words of word to ppt; If you need to analyze the tabular data in the paper, you may need to convert pdf to excel. However, if only a few files are converted, it may be simply handled with the function of copying and pasting, but if it is batch conversion, in order to avoid repetitive labor and error prone, batch conversion with tools is the correct way of working.
Imagine a situation. When the enterprise handles the lecture activities, it sends out application forms to each invited unit. When multiple application forms are recovered, it needs a summary list to further understand the background / enterprise treasure number / professional title of the students participating in the lecture. The following is an example of the situation. Before the example, briefly describe the tool structure to complete the work, as follows.
1. In Python, there are two installation packages commonly used to process PDF, pdfminer3k and pdfplumber. The differences are briefly described as follows:
pdfminer3k: convert PDF into plain text, which is often used in natural language analysis.
pdfplumber: it can process PDF files according to the number of pages, and output the tables in PDF into a list at the same time.
2. In addition, for PDF reading results, Python needs to write the results into Excel files, which can be processed by operating the excel installation package, openpyxl.
3. In order to match the number of pdf files automatically found, you need to borrow the installation package and os to operate the file and directory system.
The sample of batch registration form (. pdf) is converted into excel file as follows:
a. The original pdf screenshot of the application form is as follows. There are three pdf files.

b. Several main code segments are described as follows:
1. In order to cope with the unknown number of files and achieve batch conversion, the os instruction is used to filter the target file (. pdf) in the folder, such as # find Code snippet of PDF file in the folder.
2. Import pdf into pyrhon, and extract and convert the name / Title / mobile phone / email data in each pdf file into a list, such as the code segment of # pdf import.
3. Save the extracted data into the excel file, which contains the definition sheet and header name. For example, # open the blank excel and save it into pdf to read the code segment of the table data.
import pdfplumber
from openpyxl import Workbook # Access the installation package of xlsx
import os
# list files in the path
file_list = os.listdir()
# find .pdf file in the folder
pdf_file = list() # build empty list
for file_name in file_list:
sub_name = file_name.split('.')[1]
if sub_name == 'pdf':
pdf_file.append(file_name)
# pdf import
pdf_table = list()
name = list()
title = list()
mobile = list()
email = list()
for i in range(len(pdf_file)):
pdf = pdfplumber.open(pdf_file[i])
page = pdf.pages[0] # get page.1
pdf_table.append(page.extract_table())
if pdf_table[i][2][1] != '':
name.append(pdf_table[i][2][1])
title.append(pdf_table[i][3][1])
mobile.append(pdf_table[i][4][1])
email.append(pdf_table[i][5][1])
# Open the blank excel and save it into pdf to read the table data
workbook = Workbook()
sheet = workbook.active
sheet.title = "Registration summary"
# Setting A1: name B1: Title C1: mobile phone D1:E-mail
row0 = ["full name", "Position", "Mobile phone", "E-mail"]
sheet.append(row0)
for i in range(len(name)):
sheet.cell(row=2 + i, column=1).value = name[i]
sheet.cell(row=2 + i, column=2).value = title[i]
sheet.cell(row=2 + i, column=3).value = mobile[i]
sheet.cell(row=2 + i, column=4).value = email[i]
workbook.save(filename="Registration list.xlsx")
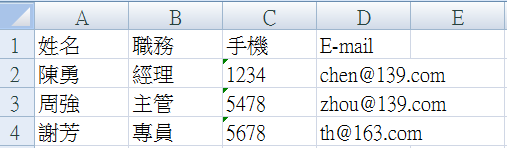
c. The output results are shown in the figure below.
-----If the article is helpful to you, open wechat to scan and invite the author to have a cup of coffee-----
