Reference and Preface
This is mainly about how the python hydra library is used. If you don't know what it is, give a brief introduction:
Hydra is an open source Python framework that simplifies research and development of other complex applications.
The key feature is the ability to dynamically create hierarchical configurations with ** combinations and override it with configuration files and command lines. The name Hydra comes from the fact that it can run many similar jobs - like a Hydra with multiple heads.
Simply put, it is easier to manage the yaml config configuration file, although it can also be yaml.load(), but this is the difference between some tools and not encountered, such as tensorboard and wandb, wandb is really fragrant, mainly yaml, which I haven't used. Recently, I think it should be more standardized, so read it and learn hydra, yaml.load should be more than sufficient for small networks and tests
- Official documents: https://hydra.cc/docs/intro/
- English Tutorials on towards: Complete tutorial on how to use Hydra in Machine Learning projects
- In combination with OmegaConf: https://omegaconf.readthedocs.io/en/latest/index.html
1. Brief introduction
install
pip install hydra-core
Notice the relationship between its version and python:
| Version | Release notes | Python Versions | |
|---|---|---|---|
| ► | 1.1 (Stable) | Release notes | 3.6 - 3.9 |
| 1.0 | Release notes | 3.6 - 3.8 | |
| 0.11 | Release notes | 2.7, 3.5 - 3.8 |
Preliminary Test
Suppose the code location and the configuration file location are as follows:
folder ├── config │ └── config.yaml └── main.py
Where main.py is as follows:
import hydra
from omegaconf import DictConfig, OmegaConf
from pathlib import Path
@hydra.main(config_path="config", config_name="config")
def main(config):
running_dir = str(hydra.utils.get_original_cwd())
working_dir = str(Path.cwd())
print(f"The current running directory is {running_dir}")
print(f"The current working directory is {working_dir}")
# To access elements of the config
print(f"The batch size is {config.batch_size}")
print(f"The learning rate is {config['lr']}")
if __name__ == "__main__":
main()
config.yaml is:
### config/config.yaml batch_size: 10 lr: 1e-4
The results are:
The current running directory is C:\Users\xx\xx\xx\folder\ The current working directory is C:\Users\xx\xx\xx\folder\outputs\2021-12-26\22-47-06 The batch size is 10 The learning rate is 0.0001
First, we can see that when hydra runs, an output folder containing date and time information is automatically created, and then the path is adjusted directly to save everything in the script. This is a preliminary test, all in this line: the configured path is "config" and the configured file name is "config"
@hydra.main(config_path="config", config_name="config")
2. Use in detail
Doll usage
This is mainly about doll use, assuming our conf file is so complex:
├───conf │ │ evaluate.yaml │ │ preprocess.yaml │ │ train.yaml │ │ │ ├───data │ │ vectornet_train.yaml │ │ vectornet_val.yaml │ │ │ ├───hparams │ │ vectornet_baseline.yaml │ │ │ ├───model │ │ vectornet.yaml │ │ │ └───status │ debug.yaml │ train.yaml
There are three yaml files under the main conf folder, train.yaml is as follows:
resume:
save_dir: models/
log_dir: ${name}/
defaults:
- data: vectornet_train
- model: vectornet
- hparams: vectornet_baseline
- status: train
The first three variables are all directly fetched values, and the defaults are dolls, such as jumping into the data folder to read vectornet_ The yaml of the train file name, and the rest of the variables read in are directly members of config's dictionary... I don't know the description that config is also a custom format for DictConfig, and then defaults reads it directly as Dict, because it declares global under its yaml, as shown in the following figure:
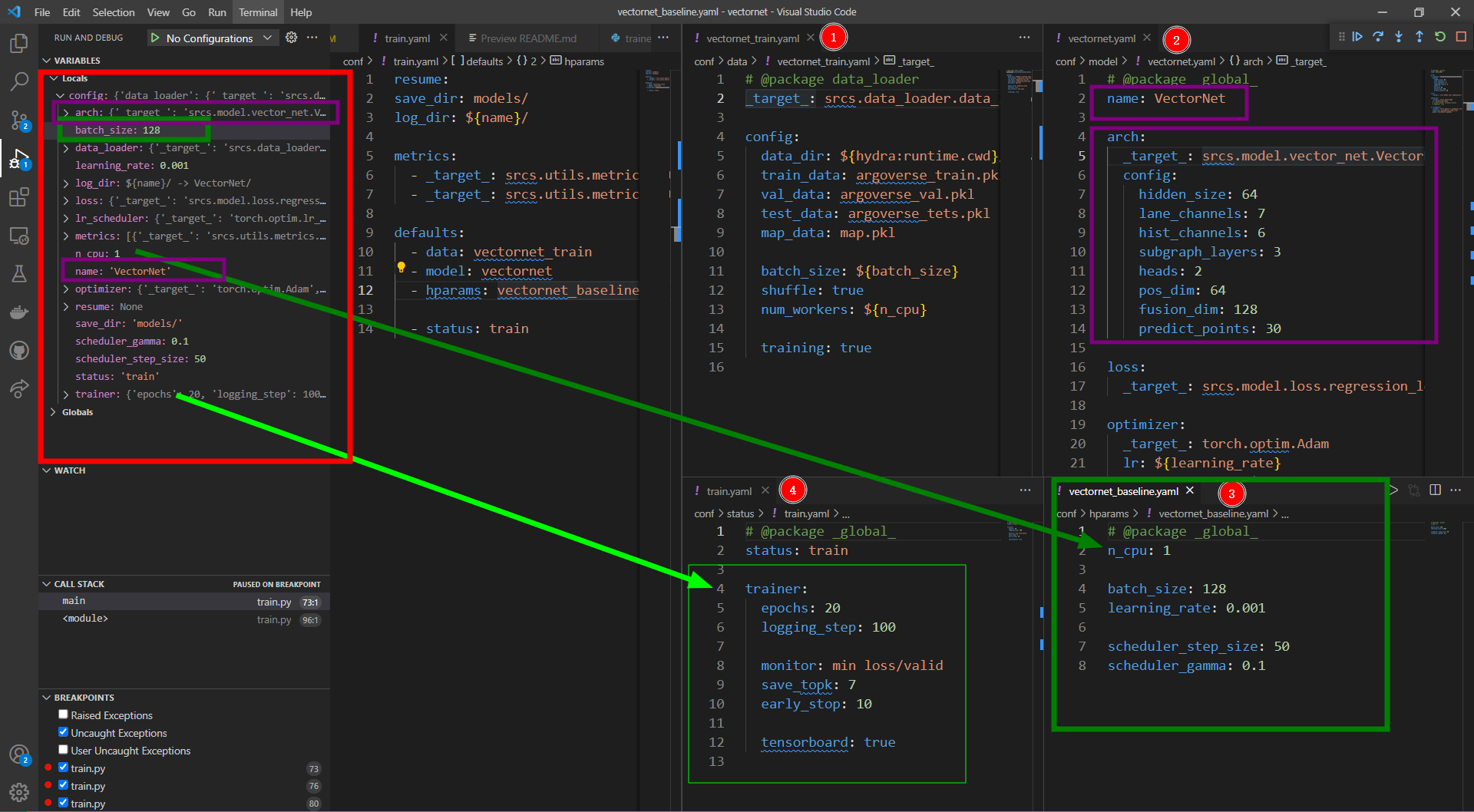
For each line at the beginning of the Yaml file, the properties of the configuration variables within this package are defined. Below is an excerpt from the official document:
PACKAGE : _global_ | COMPONENT[.COMPONENT]* COMPONENT : _group_ | _name_ | \w+ _global_ : the top level package (equivalent to the empty string). _group_ : the config group in dot notation: foo/bar/zoo.yaml -> foo.bar _name_ : the config file name: foo/bar/zoo.yaml -> zoo
The direct way to use this is to optionally add one of the lines at the beginning of yaml:
# @package _global_ # @package _group_ # @package _group_._name_ # @package foo.bar # @package foo._group_._name_
Default configuration in the latest Hydra 1.1 is _ group_
Run with parameters
That is, when you run a file, if you give multiple config parameters as input parameters, the script will run automatically multiple times, for example:
❯ python main.py lr=1e-3,1e-2 wd=1e-4,1e-2 -m [2021-03-15 04:18:57,882][HYDRA] Launching 4 jobs locally [2021-03-15 04:18:57,882][HYDRA] #0 : lr=0.001 wd=0.0001 [2021-03-15 04:18:58,016][HYDRA] #1 : lr=0.001 wd=0.01 [2021-03-15 04:18:58,149][HYDRA] #2 : lr=0.01 wd=0.0001 [2021-03-15 04:18:58,275][HYDRA] #3 : lr=0.01 wd=0.01 ❯ python my_app.py -m db=mysql,postgresql schema=warehouse,support,school [2021-01-20 17:25:03,317][HYDRA] Launching 6 jobs locally [2021-01-20 17:25:03,318][HYDRA] #0 : db=mysql schema=warehouse [2021-01-20 17:25:03,458][HYDRA] #1 : db=mysql schema=support [2021-01-20 17:25:03,602][HYDRA] #2 : db=mysql schema=school [2021-01-20 17:25:03,755][HYDRA] #3 : db=postgresql schema=warehouse [2021-01-20 17:25:03,895][HYDRA] #4 : db=postgresql schema=support [2021-01-20 17:25:04,040][HYDRA] #5 : db=postgresql schema=school
Refer to the corresponding section of the official document
OmegaConf
This part is mainly to_yaml directly to the unstructured str type of text information, separated by line breaks
config = OmegaConf.to_yaml(config, resolve=True)
# initialize training config
config = OmegaConf.create(config)
config.local_rank = rank
config.cwd = working_dir
# prevent access to non-existing keys
OmegaConf.set_struct(config, True)
Then come back through create again, add two attributes to it and reconstruct
3. More Exploration
See the official document emmm because I also read CJ's code and it looks good to use. Write down the Chinese version of the record.
It is probably known that config can be overridden,