As we all know (no), I mentioned before that I have a huluxian account. Huluxian is also a platform that has been with me for a long time. From the earliest search for cracked games to various miscellaneous technology sharing, entertainment and making friends, it can be barely completed. And I managed to get a lot of contribution value after mixing for so long. By the way, there is a certificate of merit (as for this, I didn't expect), more or less emotional. But in the twinkling of an eye, there are less than 10000 comments. It's more or less a shame to be an old user, but I don't have much time to comment next to each other. Suddenly, I thought I saw so many robot comments before. I just wrote one in python and started working (water article)
Show the wave chart at the beginning


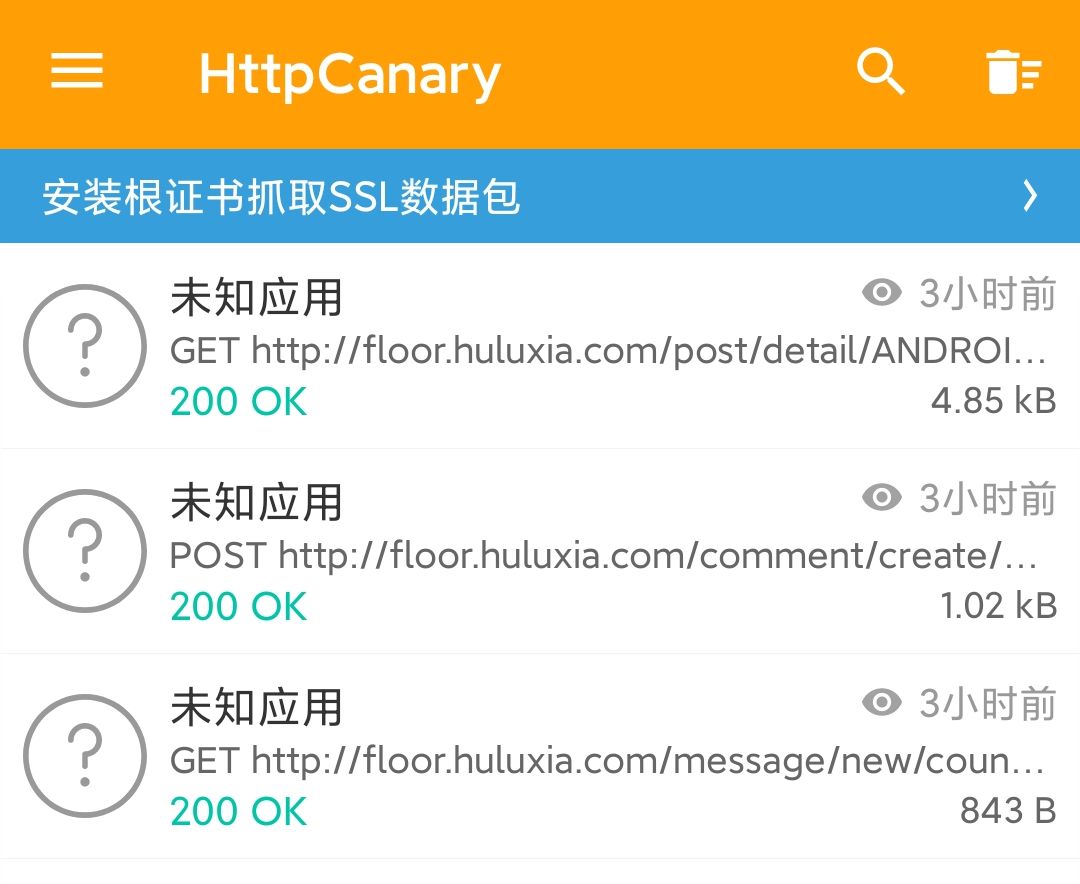
First of all, to realize the automatic comment of scripts, we first understand what links and data are used in the process of a comment through the package capturing software
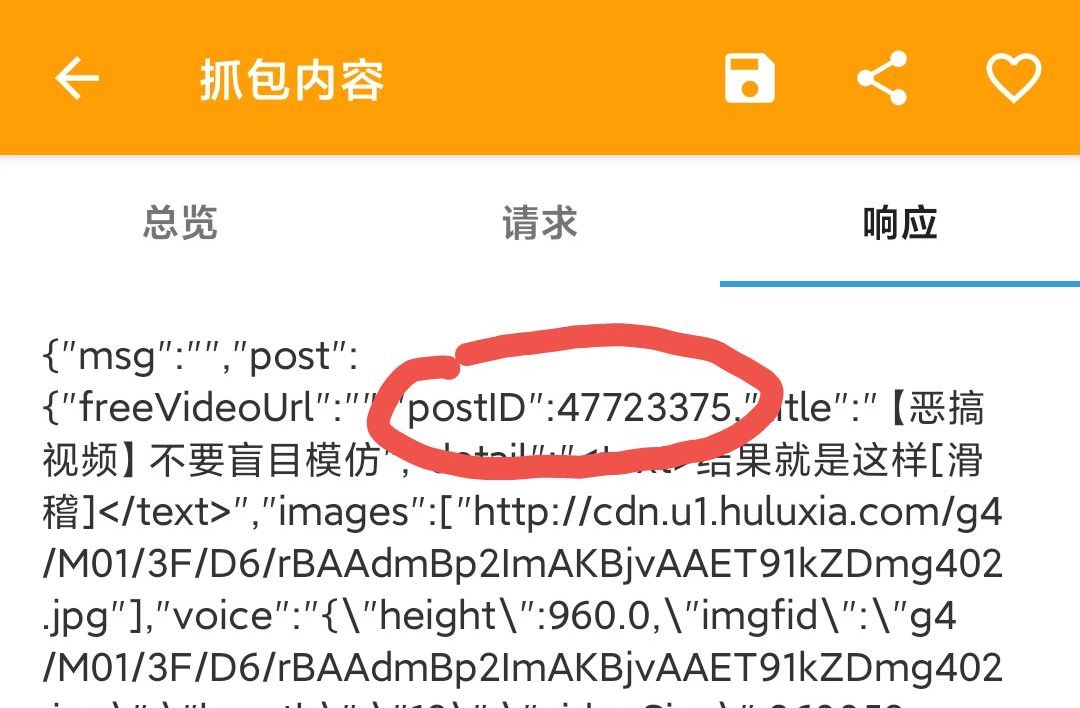
It is found here that a comment generates a total of three pieces of data
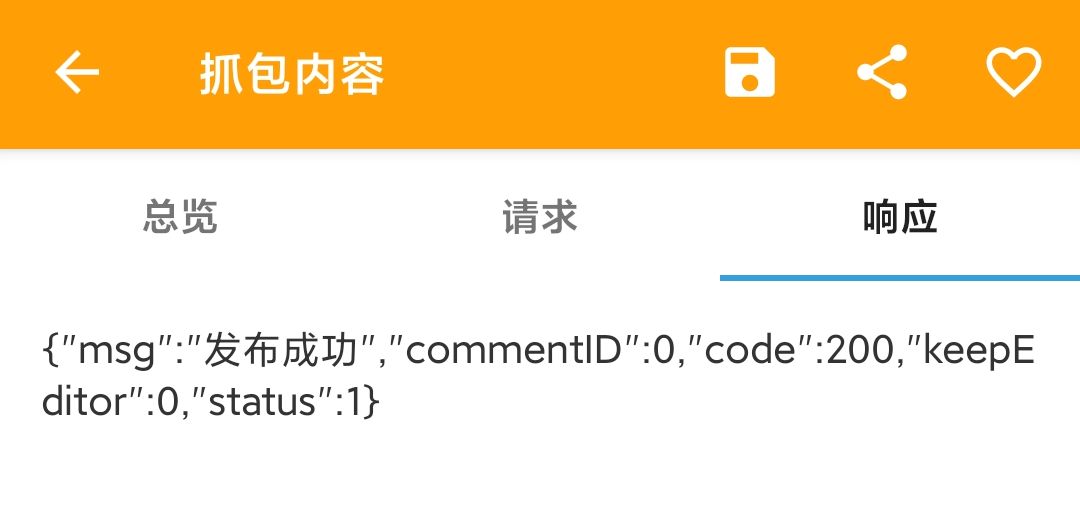
After judgment, the post data in the middle is parsed into the comment data just submitted
Next, let's analyze this packet in detail. First, we see the header information
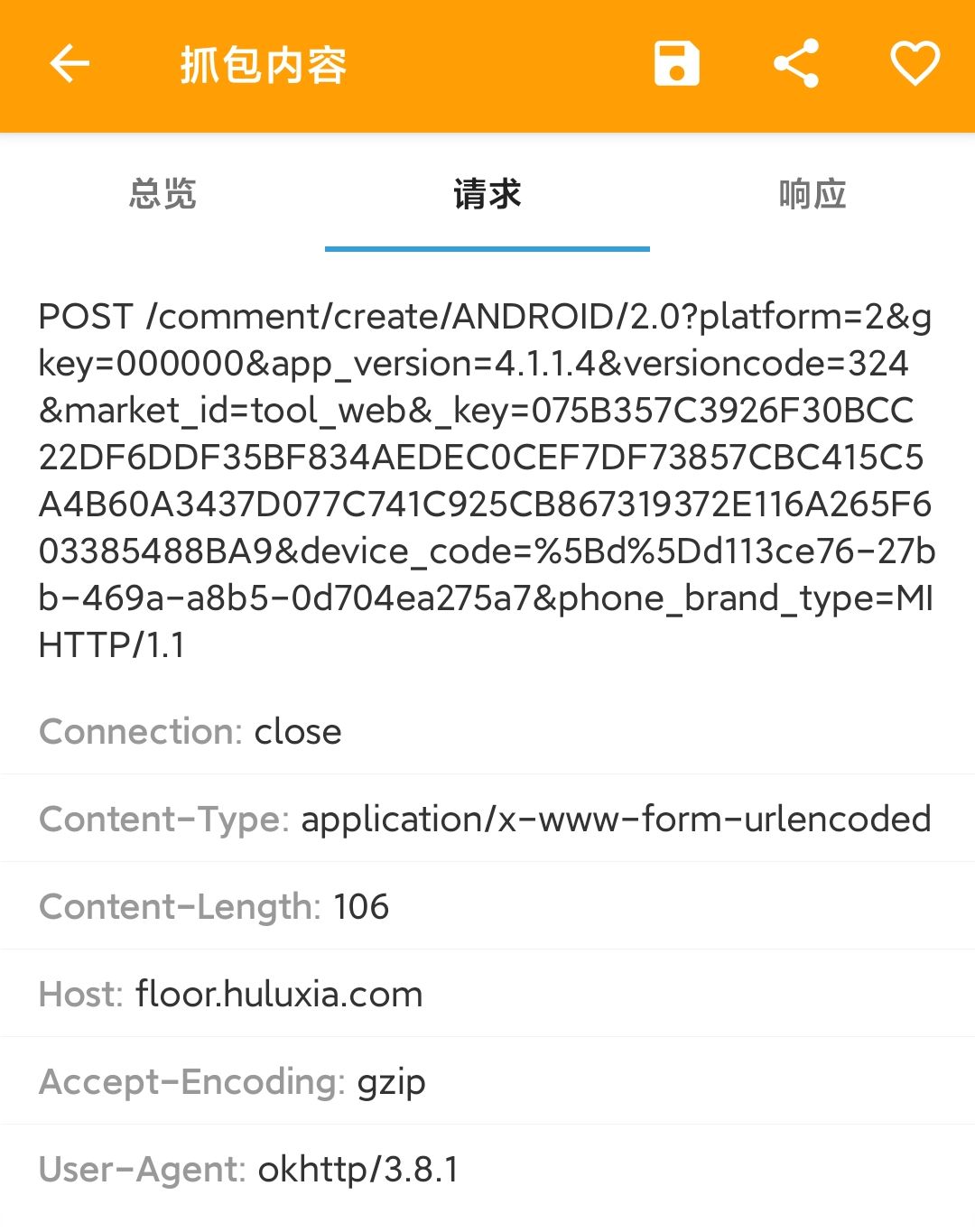
Briefly, from the url parameters in the post packet, you can clearly see such as key and device_code and other words, it can be inferred that the url parameters are generated by huluxia App based on the device code and cookie s. There is no need to take time to solve them. After logging in, you can directly capture the package and obtain them. After testing, as long as you don't manually logout, the key and device generated in the first article_ Code sustainable use, let's next look at the body of the post request

Format it
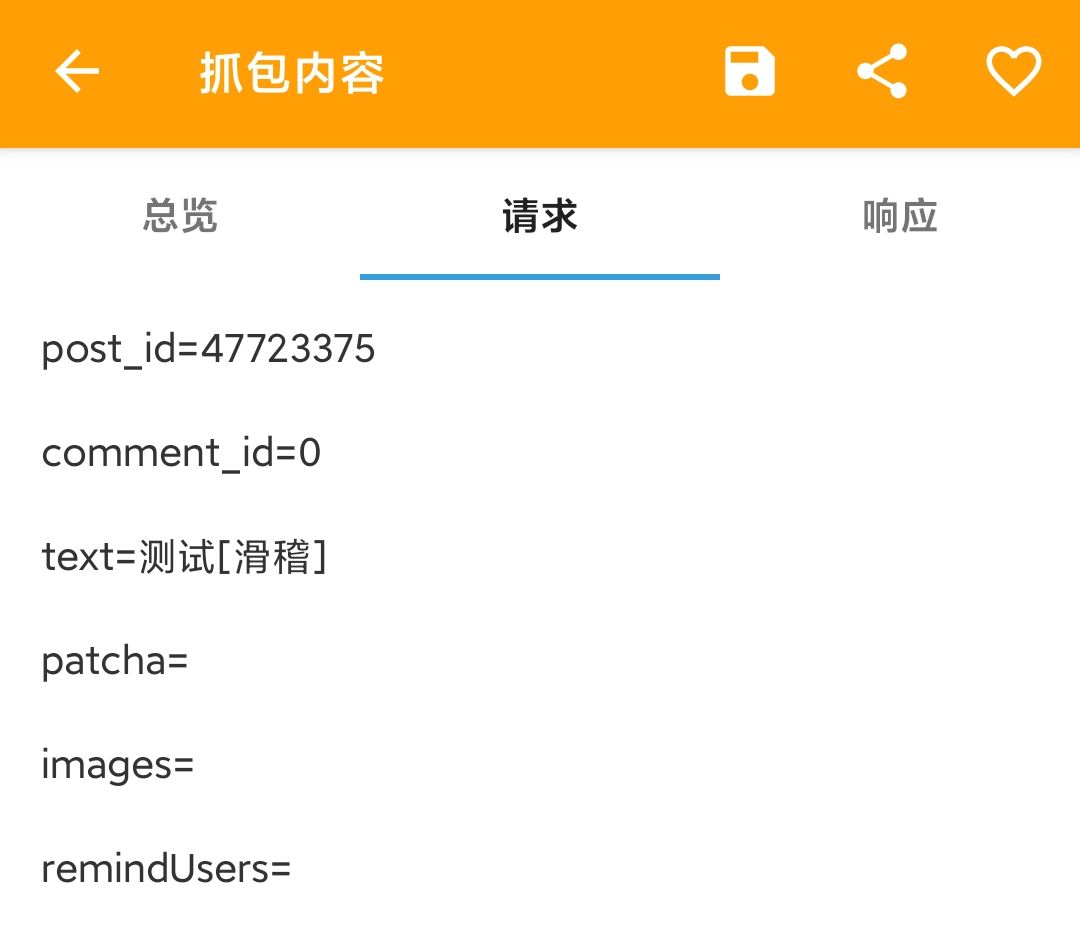
We can see that there are six parameters to analyze next to each other
The first parameter is post_id, which is found to be the id of the comment post after filtering the data (key points, which will be used in the later comments)
The second parameter is comment_id, which is determined to be the comment floor after calculation and test. Count from 0. This parameter has little impact on the packet structure. Skip it
The third parameter is text. From the screenshot of the post data body, we can see that the source data is the comment content after URL coding, which needs to be used to brush the comment later
The fourth parameter, patcha, seems to be that if the comment frequency is too high, it will require the input of verification code (I haven't encountered it at present, it seems that it's because I haven't commented much? Skip it for the time being)
The fifth parameter, images, is not much to say. It is obviously a picture in the comment. You should not encounter it when you brush the comment. Skip it for the moment. You can study it if you need it
The sixth parameter remindUsers is determined to be the user name of the comment reply after testing. It is not very useful to brush the comment. It may be used if the automatic reply function is used. It is reserved for the time being
After the main body is roughly analyzed, we begin to construct python code
First, realize the basic comment function. The module we need to use is the requests module, which is written based on the python 3 structure. Students who use Python 2 remember to change it
The requests module should not be self-contained. Remember to install pip first
First import the requests module
import requests
This is a reference for constructing the header information of headers, because huluxian is often updated, and the specific content shall be subject to the data obtained from packet capturing
headers = {
'Connection': 'close',
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': '106',
'Host': 'floor.huluxia.com',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.1'
}Next, set up comment links and post data
comment_url = "http://floor.huluxia.com/comment/create/ANDROID/2.0?platform=2&gkey=000000&app_version=4.1.1.4&versioncode=324&market_id=tool_web&_key=075B357C3926F30BCC22DF6DDF35BF834AEDEC0CEF7DF73857CBC415C5A4B60A3437D077C741C925CB867319372E116A265F603385488BA9&device_code=%5Bd%5Dd113ce76-27bb-469a-a8b5-0d704ea275a7&phone_brand_type=MI" post_data = "post_id=47723375&comment_id=0&text=%E6%B5%8B%E8%AF%95%5B%E6%BB%91%E7%A8%BD%5D&patcha=&images=&remindUsers="
Finally, use the post method of the requests module to submit the data and get the return value The final code is as follows
import requests
#Set header information
headers = {
'Connection': 'close',
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': '106',
'Host': 'floor.huluxia.com',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.1'
}
#Set reply url and post data
post_data = "post_id=47723375&comment_id=0&text=%E6%B5%8B%E8%AF%95%5B%E6%BB%91%E7%A8%BD%5D&patcha=&images=&remindUsers="
comment_url = "http://floor.huluxia.com/comment/create/ANDROID/2.0?platform=2&gkey=000000&app_version=4.1.1.4&versioncode=324&market_id=tool_web&_key=075B357C3926F30BCC22DF6DDF35BF834AEDEC0CEF7DF73857CBC415C5A4B60A3437D077C741C925CB867319372E116A265F603385488BA9&device_code=%5Bd%5Dd113ce76-27bb-469a-a8b5-0d704ea275a7&phone_brand_type=MI"
#post Submit Comment data
response = requests.post(url=comment_url, data=post_data, headers=headers)
print(response.text)Run it and return successfully
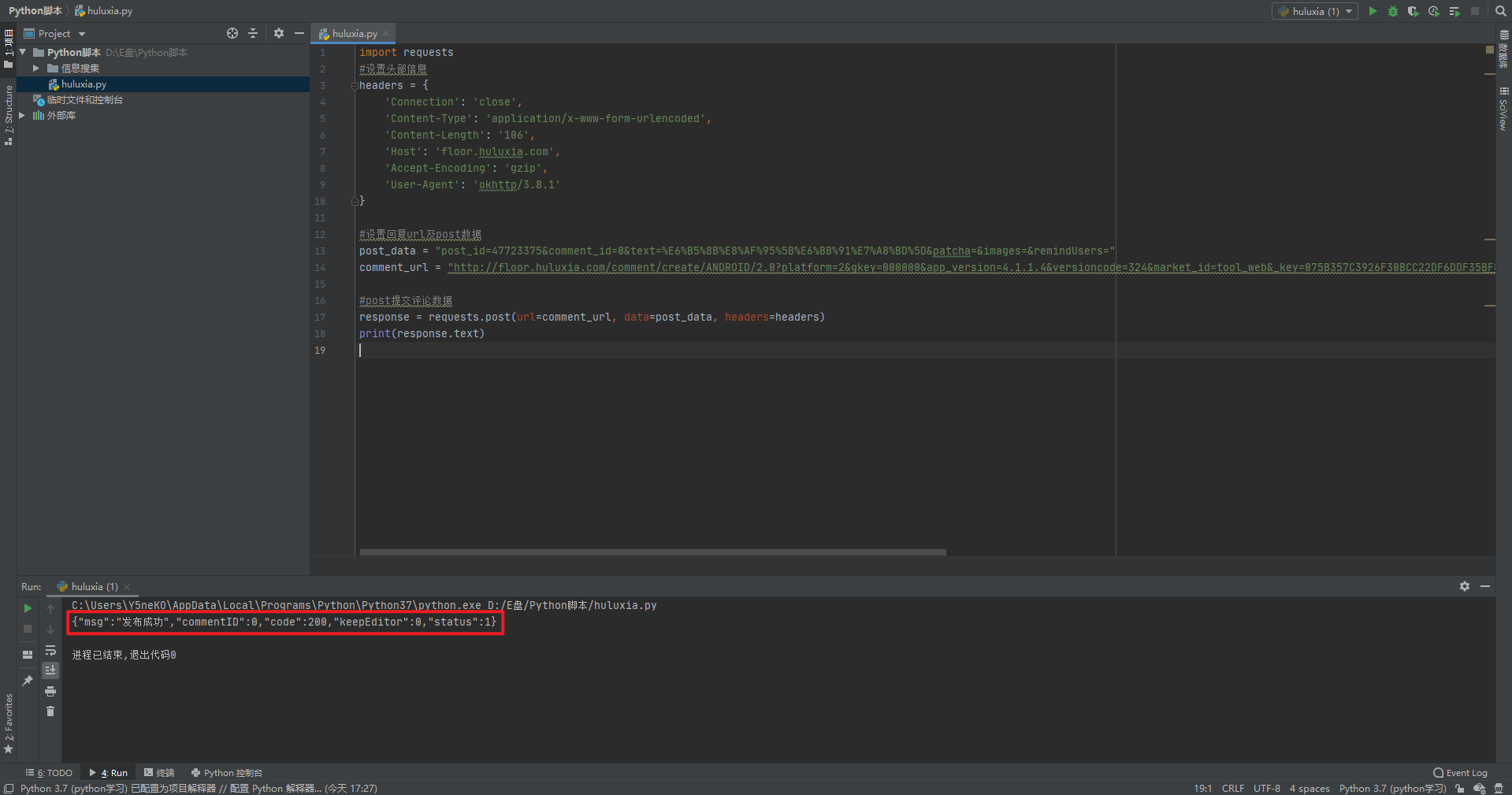
Comment success
After the basic functions are written, it's almost the same. Just after the implementation, send a comment To achieve the effect of brushing comments, we need to solve the following problems: continuous comments, too fast comment frequency, unable to comment on the same content continuously, etc The idea given here is to poll or loop statements, appropriately adjust the comment interval, random characters or call the robot api So we look forward to adding 100 million details. The code after adding details is like this
import requests
import random
import urllib.parse
import json
import time
# Set header information
headers = {
'Connection': 'close',
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': '106',
'Host': 'floor.huluxia.com',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.1'
}
# Generate random comments
def random_comment():
post_id = random.randint(40000000, 50000000)
comment_id = random.randint(1, 10)
comment_api = "http://api.btstu.cn/yan/api.php?charset=utf-8"
comment = urllib.parse.quote("%s" % comment_id + "[sleep][teacup]")
# comment_info = requests.get(comment_api, verify=False)
# comment = urllib.parse.quote("daily poisonous chicken soup time:" + comment_info.text + "[funny]")
comment_data = "post_id=%d" % post_id + "&comment_id=0&text=%s" % comment + "&patcha=&images=&remindUsers="
return comment_data, post_id, urllib.parse.unquote(comment)
def main():
# Set reply url and post
post_data = random_comment()
comment_url = "http://floor.huluxia.com/comment/create/ANDROID/2.0?platform=2&gkey=000000&app_version=4.1.1.4&versioncode=324&market_id=tool_web&_key=6862A43A7126C3C5D7AB0BFE61BAE16FA5852495DFCFB4DCD5D1D34F3B9678F18C11DF30A4EAC58ED693FD5A1E4E7DCA522FA2837AB0F714&device_code=%5Bd%5Dd113ce76-27bb-469a-a8b5-0d704ea275a7&phone_brand_type=MI"
post_url = "http://floor.huluxia.com/post/detail/ANDROID/4.1?post_id=%d" % post_data[1]
# Get post information (1)
post_response = requests.get(post_url)
post_json_data = json.loads(post_response.text)
# post Submit Comment data
print(comment_url)
print(post_data[0])
print(headers)
response = requests.post(url=comment_url, data=post_data[0], headers=headers)
json_data = json.loads(response.text)
if json_data['code'] == 104:
print("----------------------------")
print("Topic does not exist, skip this ID")
else:
# Get post information (2)
post_info = post_json_data['post']
post_category = post_info['category']
# Return status information
print("----------------------------")
print("Comment status:" + json_data['msg'])
print("Comments:" + post_data[2])
print("Post name:" + post_info['title'])
print("Section:" + post_category['title'])
for i in range(1, 99999):
main()
time.sleep(5)It can be regarded as version 1.0 of this script However, after the script test a few days ago, I found that many id posts have the situation that the topic has been deleted or the topic does not exist, which greatly affects the efficiency in the process of executing the code Therefore, a script is needed to collect val id post IDs
First of all, we get the subject information of the post by grabbing the package. Finally, we get such a url
http://floor.huluxia.com/post/detail/ANDROID/4.1?post_id=1
This url returns a string of json structure data. Let's format it to see the structure
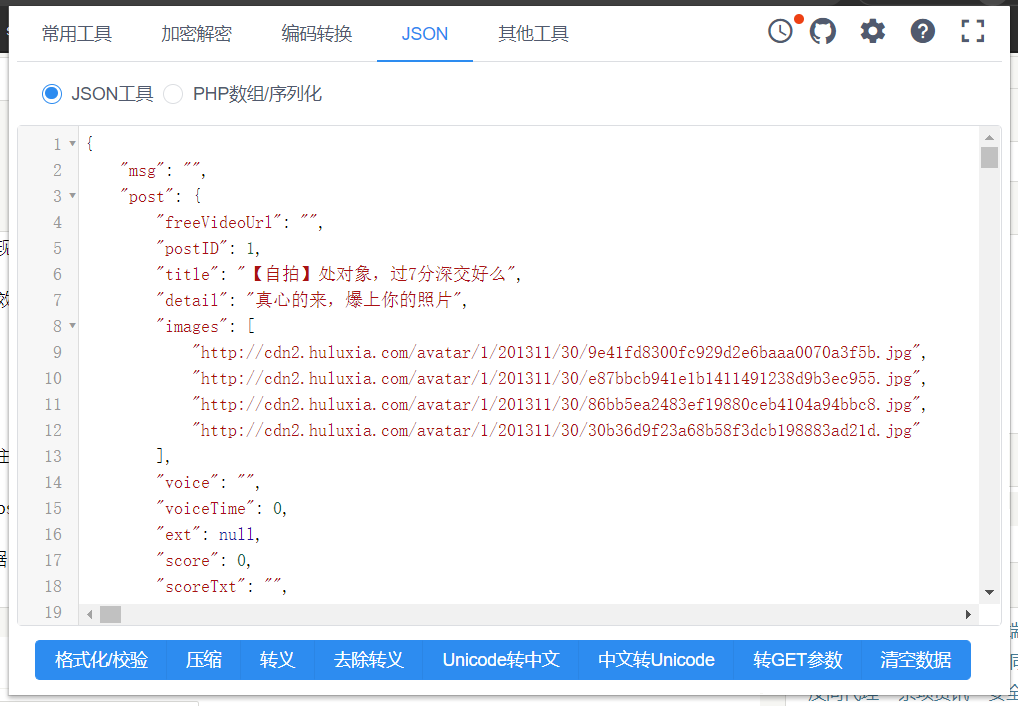
Let's look at a deleted post link
http://floor.huluxia.com/post/detail/ANDROID/4.1?post_id=112333
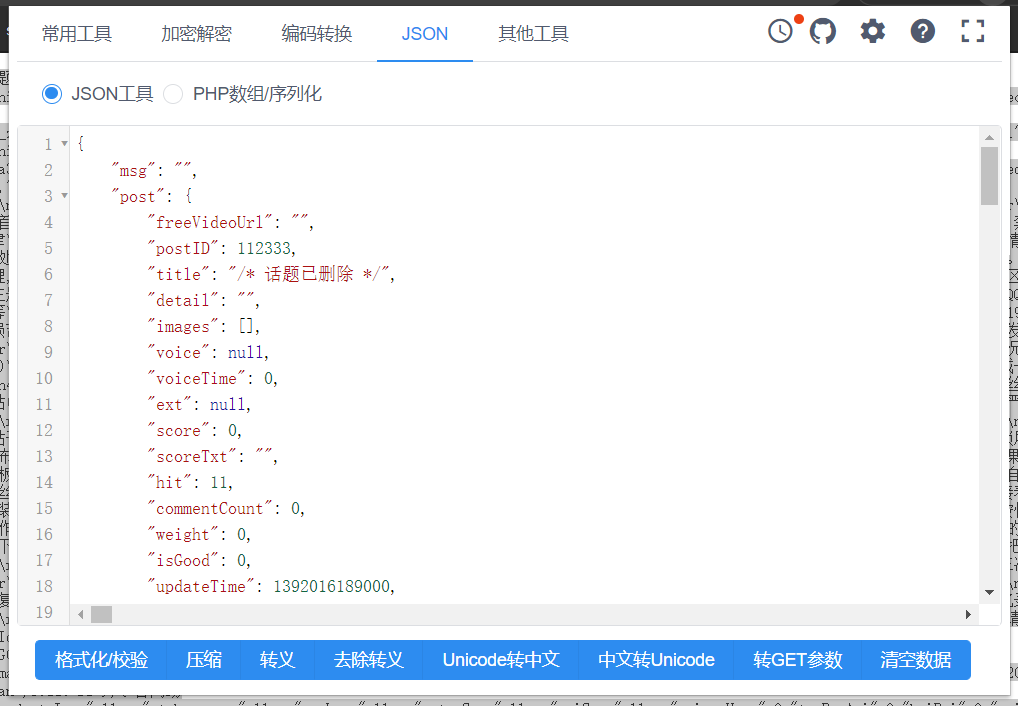
Finally, let's look at a non-existent post link
http://floor.huluxia.com/post/detail/ANDROID/4.1?post_id=112333231221321
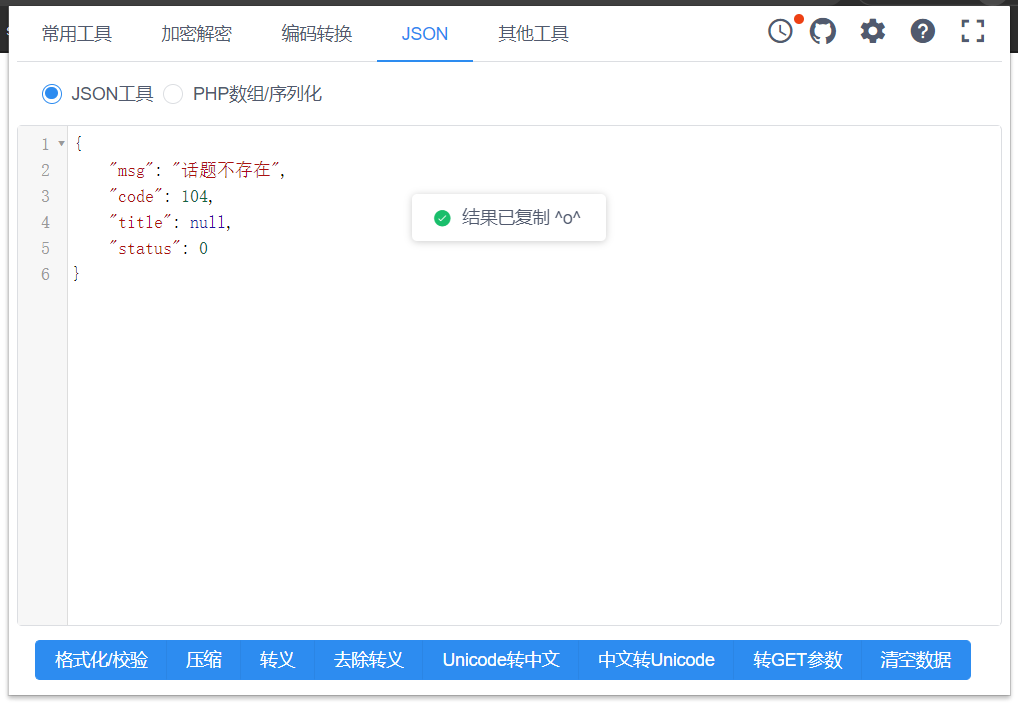
Observe their features. The features returned by deleted and non-existent posts are easier to be captured by crawlers. We take these two cases as the judgment conditions Start to construct python code, first import the module we want to use and define the url
import requests import json url = "http://floor.huluxia.com/post/detail/ANDROID/4.1?post_id=%s"
Then we write a for loop and assign values from 1 to traverse the post id, and use json Loads parses the returned json data
for post_id in range(1, 50000000):
post_data = requests.get(url % post_id)
post_json_data = json.loads(post_data.text)The following features can be clearly seen from the just pictures: If the post is deleted, the returned title is / topic has been deleted/ The post does not exist. One key value pair in the returned json is "code":104 Except for these two states, the rest is normal Thus, you can write an if elif loop to match the string
if '"code":104' in post_data.text:
print("Posts ID: %d" % post_id + " Status: topic does not exist")
elif "/* Topic deleted */" in post_data.text:
print("Posts ID: %d" % post_id + " Status: topic deleted")
else:
print("Posts ID: %d" % post_id + " Status: this topic is normal")When the "this topic is normal" condition is met, our write function writes the valid id to the text file By the way, another text file is continuously updated with the id of the loop to facilitate the next backtracking of the crawl progress The complete code is as follows:
import requests
import json
url = "http://floor.huluxia.com/post/detail/ANDROID/4.1?post_id=%s"
for post_id in range(29042, 50000000):
post_data = requests.get(url % post_id)
post_json_data = json.loads(post_data.text)
# print(post_json_data)
if '"code":104' in post_data.text:
print("Posts ID: %d" % post_id + " Status: topic does not exist")
elif "/* Topic deleted */" in post_data.text:
print("Posts ID: %d" % post_id + " Status: topic deleted")
else:
print("Posts ID: %d" % post_id + " Status: this topic is normal")
valid_id = open("valid_id.txt", "a")
valid_id.write(str(post_id))
valid_id.write("\n")
valid_id.close()
end_id = open("end_id.txt", "w")
end_id.write(str(post_id))
end_id.close()After running the script, the valid ID will be output to the file valid_id.txt
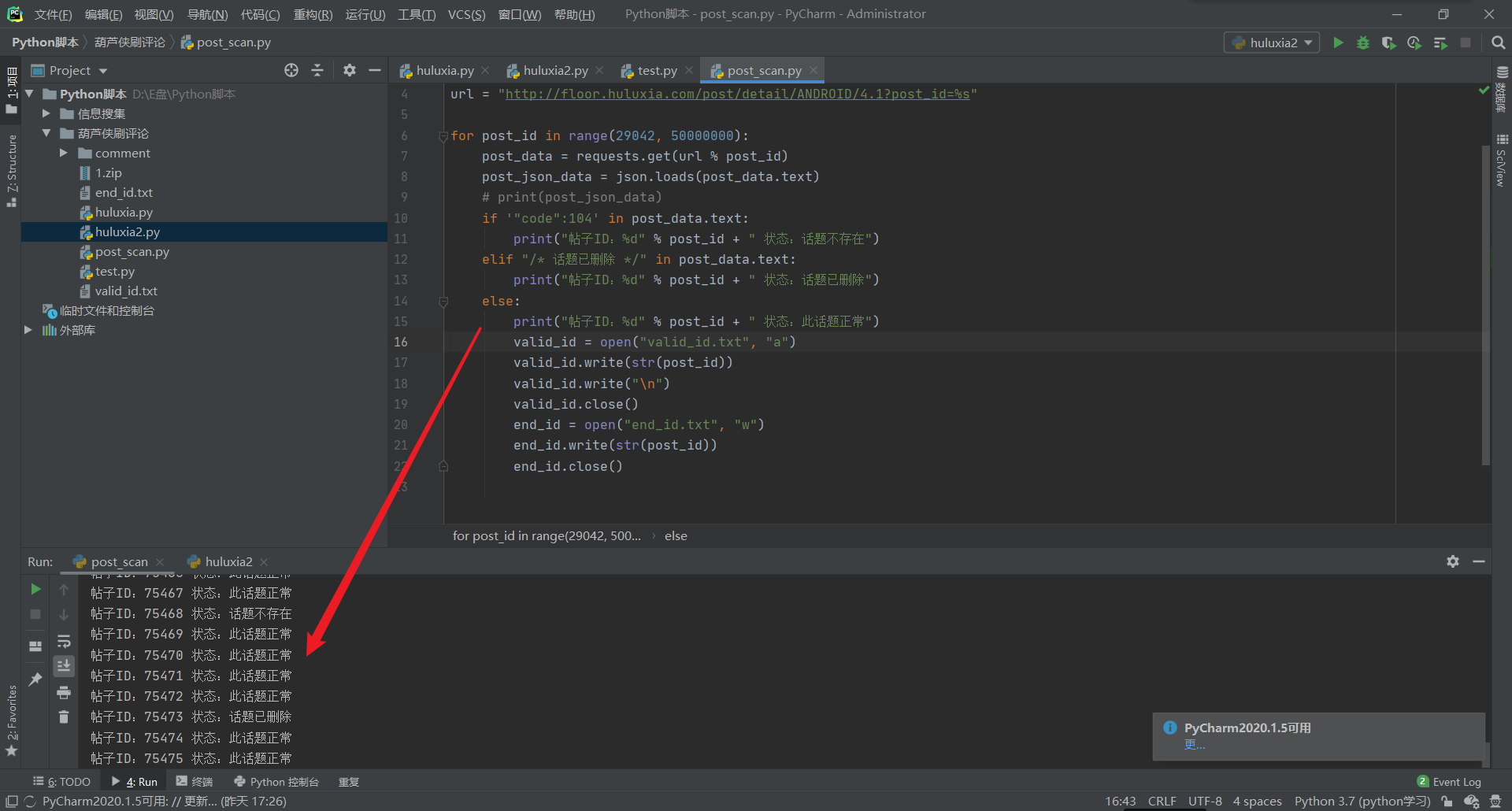
The format is like this
Next, we can use the file generated by this script to automatically obtain the valid id, which improves the efficiency a lot After improvement, the following functions are added: Automatically get comments by reading the contents of the file. You can change the comment configuration file and add comment statements at any time Automatically identify the section of the post and select different comment configuration files (stupid method, write repeatedly, the code is a little miscellaneous, because it's too delicious, I hope someone can help me optimize, whining)
The complete code is as follows:
import requests
import random
import urllib.parse
import json
import time
import linecache
# Set account key link
comment_url = "http://floor.huluxia.com/comment/create/ANDROID/2.0?platform=2&gkey=000000&app_version=4.1.1.4&versioncode=324&market_id=tool_web&_key=6862A43A7126C3C5D7AB0BFE61BAE16FA5852495DFCFB4DCD5D1D34F3B9678F18C11DF30A4EAC58ED693FD5A1E4E7DCA522FA2837AB0F714&device_code=%5Bd%5Dd113ce76-27bb-469a-a8b5-0d704ea275a7&phone_brand_type=MI"
# Set header information
headers = {
'Connection': 'close',
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': '106',
'Host': 'floor.huluxia.com',
'Accept-Encoding': 'gzip',
'User-Agent': 'okhttp/3.8.1'
}
# Gets the number of text lines for random comments
def get_lines(filept): # filept pass file path
f = open(file=filept, encoding='utf-8') # Adjust encoding code according to file content
n = len(f.readlines())
return n
# Get post ID
def get_post_id():
lines = get_lines(filept="valid_id.txt") # Cooperate with post_scan.py to read the collected valid post id
id_2 = random.randint(1, lines) # Random number of rows
post_id = linecache.getline(filename="valid_id.txt", lineno=id_2) # One post id per line
return int(post_id)
# Get post information
def get_post_info(post_id):
post_url = "http://floor.huluxia.com/post/detail/ANDROID/4.1?post_id=%d" % post_id
post_response = requests.get(post_url)
post_json_data = json.loads(post_response.text)
return post_json_data
# Determine the section of the post
def category_decide(post_info):
post = post_info['post']
category = post['category']
return category['title']
# Practical software comments are generated with the main intention of "thank you for sharing and take away"
def comment_syrj(post_id):
post_id = post_id
lines = get_lines(filept="comment/syrj.txt") # Get the number of reply profile lines
flag = random.randint(1, lines) # With the next statement, randomly extract the number of lines from the reply configuration file
comment = linecache.getline(filename="comment/syrj.txt", lineno=flag)
comment_data = "post_id=%d" % post_id + "&comment_id=0&text=%s" % comment + "&patcha=&images=&remindUsers=" # Comment post data body
return comment_data, post_id, urllib.parse.unquote(comment)
# Xinfan source comments are generated, mainly comments with the main intention of "very good-looking, thanks for sharing"
def comment_xfy(post_id):
post_id = post_id
lines = get_lines(filept="comment/xfy.txt") # Get the number of reply profile lines
flag = random.randint(1, lines) # With the next statement, randomly extract the number of lines from the reply configuration file
comment = linecache.getline(filename="comment/xfy.txt", lineno=flag)
comment_data = "post_id=%d" % post_id + "&comment_id=0&text=%s" % comment + "&patcha=&images=&remindUsers=" # Comment post data body
return comment_data, post_id, urllib.parse.unquote(comment)
# Pool comments are generated, mainly those with water
def comment_yc(post_id):
post_id = post_id
lines = get_lines(filept="comment/yc.txt") # Get the number of reply profile lines
flag = random.randint(1, lines) # With the next statement, randomly extract the number of lines from the reply configuration file
comment = linecache.getline(filename="comment/yc.txt", lineno=flag)
comment_data = "post_id=%d" % post_id + "&comment_id=0&text=%s" % comment + "&patcha=&images=&remindUsers=" # Comment post data body
return comment_data, post_id, urllib.parse.unquote(comment)
# Wishing comments are generated, mainly with the main intention of "thank you for sharing, wait for big guys to share"
def comment_xy(post_id):
post_id = post_id
lines = get_lines(filept="comment/xy.txt") # Get the number of reply profile lines
flag = random.randint(1, lines) # With the next statement, randomly extract the number of lines from the reply configuration file
comment = linecache.getline(filename="comment/xy.txt", lineno=flag)
comment_data = "post_id=%d" % post_id + "&comment_id=0&text=%s" % comment + "&patcha=&images=&remindUsers=" # Comment post data body
return comment_data, post_id, urllib.parse.unquote(comment)
# Comments on beautiful legs are generated, mainly praising and praising comments
def comment_mt(post_id):
post_id = post_id
lines = get_lines(filept="comment/mt.txt") # Get the number of reply profile lines
flag = random.randint(1, lines) # With the next statement, randomly extract the number of lines from the reply configuration file
comment = linecache.getline(filename="comment/mt.txt", lineno=flag)
comment_data = "post_id=%d" % post_id + "&comment_id=0&text=%s" % comment + "&patcha=&images=&remindUsers=" # Comment post data body
return comment_data, post_id, urllib.parse.unquote(comment)
# Game comments are generated, mainly comments with the main intention of "whether to play and position"
def comment_yx(post_id):
post_id = post_id
lines = get_lines(filept="comment/yx.txt") # Get the number of reply profile lines
flag = random.randint(1, lines) # With the next statement, randomly extract the number of lines from the reply configuration file
comment = linecache.getline(filename="comment/yx.txt", lineno=flag)
comment_data = "post_id=%d" % post_id + "&comment_id=0&text=%s" % comment + "&patcha=&images=&remindUsers=" # Comment post data body
return comment_data, post_id, urllib.parse.unquote(comment)
# Main function to send comment packet body
def main():
post_id = get_post_id()
post_info = get_post_info(post_id)
# print(str(post_info))
# print(type(post_info))
if "'code': 104" in str(post_info): # Determine whether the post is valid
print("----------------------------")
print("Topic does not exist, skip this ID")
elif "/* Topic deleted */" in str(post_info):
print("----------------------------")
print("Topic deleted, skip this ID")
else: # If the above two special conditions are not met, the post content is normal. Proceed to the next step to construct the data package
category = category_decide(post_info) # Get the section to which the post belongs, and use it to select the reply profile of different sections
post_data = post_info['post'] # Get post information for subsequent printing and return status
if category == "Practical software" or category == "Mobile phone beautification" or category == "Game tutorial" or category == "Technology sharing" or category == "Original technology" or category == "Welfare activities" or category == "Third floor College" or category == "Avatar signature": # Similar sections dominated by practical software sections
comment_data = comment_syrj(post_id) # Comment data
response = requests.post(url=comment_url, data=comment_data[0].encode('utf-8'),
headers=headers) # Receive comment return packet
response_json = json.loads(response.text) # The comment return packet is converted to json/dict format for subsequent reading of key values
# Return comment status information
print("----------------------------")
print("Comment status:" + response_json['msg'])
print("Comments:" + comment_data[2])
print("Post name:" + post_data['title'])
print("Section:" + category)
elif category == "Xinfanyuan" or category == "Three two shadows":
comment_data = comment_xfy(post_id) # Comment data
response = requests.post(url=comment_url, data=comment_data[0].encode('utf-8'),
headers=headers) # Receive comment return packet
response_json = json.loads(response.text) # The comment return packet is converted to json/dict format for subsequent reading of key values
# Return comment status information
print("----------------------------")
print("Comment status:" + response_json['msg'])
print("Comments:" + comment_data[2])
print("Post name:" + post_data['title'])
print("Section:" + category)
elif category == "Swimming pool" or category == "Entertainment world" or category == "Spoof" or category == "Model toy" or category == "Playstation":
comment_data = comment_yc(post_id) # Comment data
response = requests.post(url=comment_url, data=comment_data[0].encode('utf-8'),
headers=headers) # Receive comment return packet
response_json = json.loads(response.text) # The comment return packet is converted to json/dict format for subsequent reading of key values
# Return comment status information
print("----------------------------")
print("Comment status:" + response_json['msg'])
print("Comments:" + comment_data[2])
print("Post name:" + post_data['title'])
print("Section:" + category)
elif category == "Make a wish" or category == "Drawing workshop":
comment_data = comment_xy(post_id) # Comment data
response = requests.post(url=comment_url, data=comment_data[0].encode('utf-8'),
headers=headers) # Receive comment return packet
response_json = json.loads(response.text) # The comment return packet is converted to json/dict format for subsequent reading of key values
# Return comment status information
print("----------------------------")
print("Comment status:" + response_json['msg'])
print("Comments:" + comment_data[2])
print("Post name:" + post_data['title'])
print("Section:" + category)
elif category == "charming legs" or category == "Dimensional Pavilion" or category == "selfie":
comment_data = comment_mt(post_id) # Comment data
response = requests.post(url=comment_url, data=comment_data[0].encode('utf-8'),
headers=headers) # Receive comment return packet
response_json = json.loads(response.text) # The comment return packet is converted to json/dict format for subsequent reading of key values
# Return comment status information
print("----------------------------")
print("Comment status:" + response_json['msg'])
print("Comments:" + comment_data[2])
print("Post name:" + post_data['title'])
print("Section:" + category)
elif category == "game" or category == "Steam" or category == "LOL Mobile Games" or category == "Glory of Kings" or category == "DNF Mobile Games" or category == "Game for Peace" or category == "Call of duty mobile game" or category == "Cross Fire" or category == "Original God" or category == "Crazyracing Kartrider" or category == "QQ Flying car" or category == "Big ball battle" or category == "Minecraft" or category == "League of Heroes" or category == "DungeonFighter" or category == "After tomorrow" or category == "Cool running every day" or category == "Xinyou recommendation":
comment_data = comment_yx(post_id) # Comment data
response = requests.post(url=comment_url, data=comment_data[0].encode('utf-8'),
headers=headers) # Receive comment return packet
response_json = json.loads(response.text) # The comment return packet is converted to json/dict format for subsequent reading of key values
# Return comment status information
print("----------------------------")
print("Comment status:" + response_json['msg'])
print("Comments:" + comment_data[2])
print("Post name:" + post_data['title'])
print("Section:" + category)
else:
print("----------------------------")
print("No predefined sections:" + category + ",skip")
for i in range(1000):
main()
time.sleep(6)The specific function descriptions are in the notes, so I won't explain more The comment configuration file is mainly the file name read by the comment parameter and placed in the comment directory under the same directory. The configuration file needs to be stored in utf-8 code, otherwise the script may report an error
I will put all the code in github, and there may be updates in the future. github project link: https://github.com/Y5neKO/huluxia_auto_comment