Recently, a small partner said that a tool is needed to compare the differences between two excel tables and directly mark the rows with differences.
The code is quite simple. In order to facilitate Xiaobai's use, I package it into an exe file and click execute to output the results.
1. Let's talk about how to use it first, followed by the code
Link: https://pan.baidu.com/s/1oNEeIDOnw1Grw2MOdJrwUQ
Extraction code: w29l
Go to the network disk link first and download the file:
If you don't need the source code, Download xlsx directly_ compare. Rar is enough.
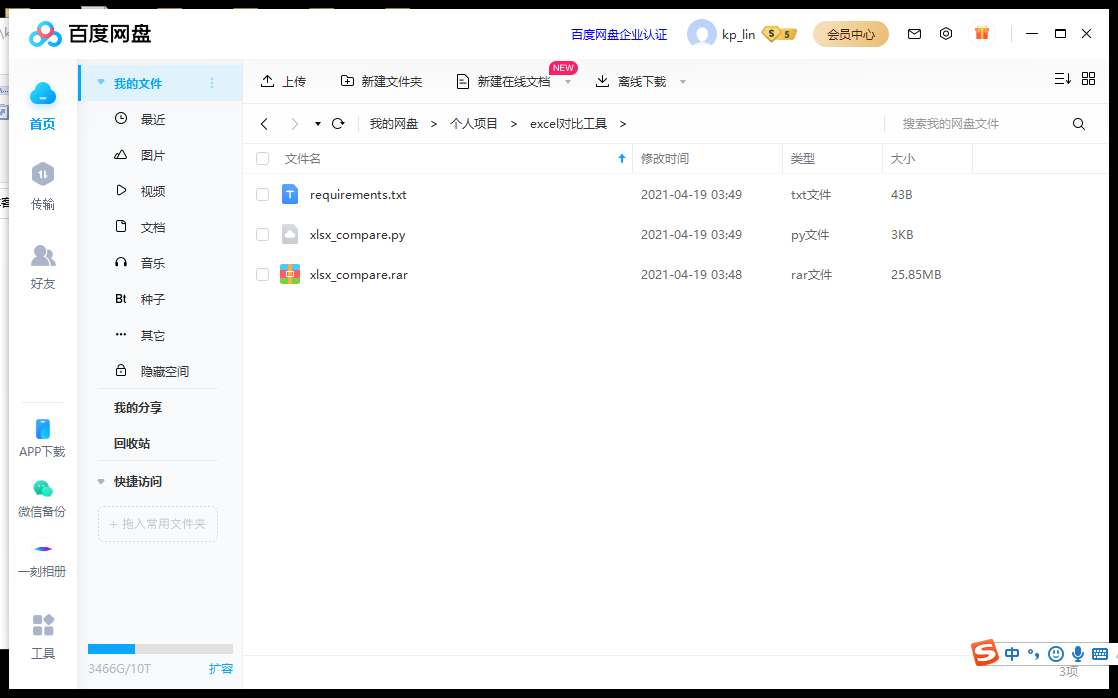
Open after decompression:
The two xlsx files here are the files I use to test. You can directly replace them with your own. They must be two. Don't put other files.
Highlight: your two excel files must be xlsx format files, and the comparison content is put in Sheet1.
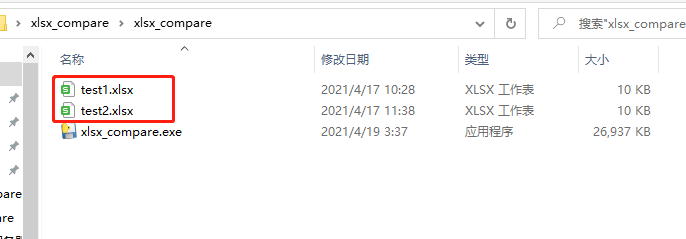
Click the exe file and the result is as follows:
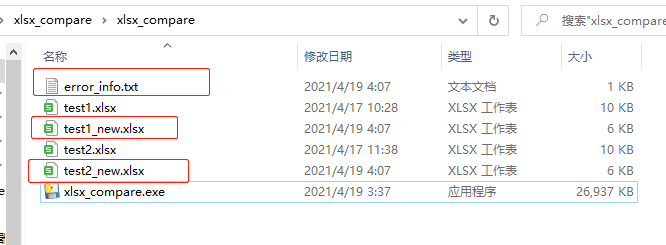
Three documents will be output, the first error_info.txt means that the error information will be written into this file during execution. If it runs normally, it is written as.

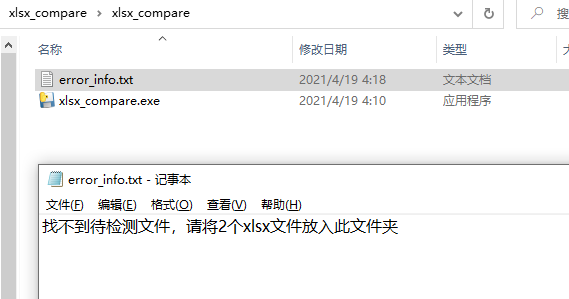
If an exception occurs, for example, you forget to put two reference files in, error_info.txt is like this
The other two new ending files are the comparison results. Open them and have a look.
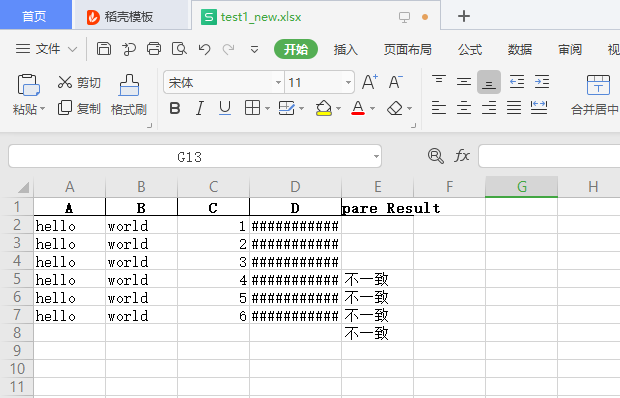
Because the length of column D is too long.
If any inconsistency is found in the comparison, it will be marked with Compare Result in the last column
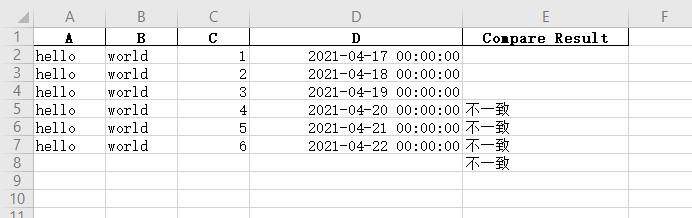
In this case, lines 5, 6 and 7 of the two files are inconsistent, and line 8 is because of test1 Xlsx has no data in line 8, while test2 Xlsx has, so it is also marked.
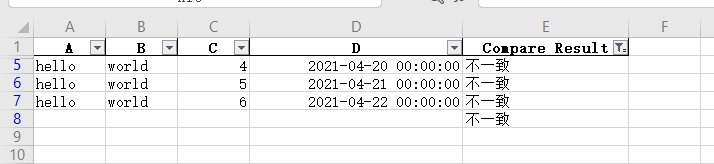
In this way, we can get all the inconsistent lines of the two files by filtering through the excel filter
2. Code
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# date: 2021/4/17
# filename: xlsx_compare
# author: kplin
import pandas as pd
import os
def my_log(info):
try:
with open('error_info.txt', 'w+') as f:
f.write(info)
f.close()
except Exception as e:
print('The following error occurred while writing the error log:\n%s'%e)
def get_file():
try:
# Get 2 files in the current folder
dir_path = os.getcwd()
files = os.listdir(dir_path)
ret = []
for i in files:
if i.endswith('.xlsx') and not i.endswith('_new.xlsx'):
ret.append(i)
if i.endswith('.xlsx') and not i.endswith('_new.xlsx') and '~$' in i:
info ='Please close the file%s'%i
my_log(info)
return None
if len(ret) == 0:
info = 'Cannot find the file to be detected, please send 2 xlsx Put files in this folder'
my_log(info)
return None
# print(ret)
return ret[0], ret[1]
except Exception as e:
my_log(str(e))
def main(file1, file2):
try:
# 1. Obtain the original file path and name, and prepare the new file name and file path to be generated first
fname1, ext = os.path.splitext(os.path.basename(file1))
new_file1 = file1.replace(fname1, fname1 + '_new')
fname2, ext = os.path.splitext(os.path.basename(file2))
new_file2 = file2.replace(fname2, fname2 + '_new')
# 2. Read file
df1 = pd.read_excel(file1)
df2 = pd.read_excel(file2)
length = len(df1) if len(df1) >= len(df2) else len(df2)
# If the number of rows of the two data blocks is inconsistent, make up the same number
if len(df1) - len(df2) > 0:
# Get the column name of DF1
d = {}
for i in df2.columns:
d[i] = ['' for x in range(len(df1) - len(df2))]
concat_df = pd.DataFrame(d)
df2 = pd.concat([df2, concat_df])
if len(df2) - len(df1) > 0:
d = {}
for i in df1.columns:
d[i] = ['' for x in range(len(df2) - len(df1))]
concat_df = pd.DataFrame(d)
df1 = pd.concat([df1, concat_df])
dis_index = []
for i in range(len(df1)):
ret = df1.iloc[i, :]==df2.iloc[i, :]
if False in ret.tolist():
dis_index.append(i)
dis_list = ['' for i in range(length)]
for i in dis_index:
dis_list[i] = 'atypism'
df1['Compare Result'] = dis_list
df2['Compare Result'] = dis_list
df1.to_excel(new_file1, index=False)
df2.to_excel(new_file2, index=False)
my_log('The verification is successful. The reference document is:%s%s and %s%s'%(fname1, ext, fname2, ext))
print('Verification is complete, please check the new file')
except Exception as e:
print('Unknown error occurred, please check error_info.txt')
my_log(str(e))
if __name__ == '__main__':
if not get_file():
print('Error reading file, please check error_info.txt')
else:
file1, file2 = get_file()
main(file1, file2)
There are three functions in total:
1,my_ The log function is used to write logs.
2,get_ The file function is used to get all suffixes under the current path xlsx files will be excluded_ new.xlsx file, and if there is an open excel file in the current folder, it will automatically end the operation and prompt to close the open excel file in the current folder.
3. The main function is used to process the comparison and output the results:
Here, pandas is mainly used to read the data and compare them row by row. If they are inconsistent, the position of the difference will be recorded. After checking all rows, add a column of Compare Result to the data block, mark the different rows, and finally write them to generate two new files.
All dependent packages are in requirements Txt:
pandas 1.1.4
openpyxl 3.0.7
xlrd 1.2.0
You can directly PIP install - R requirements Txt, download and install the dependent package directly.
The logic is very simple, but it has not been fully tested. There may be other errors in some special cases. If so, leave me a message to explain what caused the error and improve it when you have time.